
Building Production Machine Learning Systems on Google Cloud Platform (Part 3)
Scaling out to a cloud platform for fast model training, evaluation, inferencing, logging, and monitoring.

This is the third part of a four-part series. I suggest you read part 1 and 2 for a better understanding:
In this article, we will continue the exploration of production machine learning systems on GCP with a special focus on the design of high-performance ML systems.
Content
- Efficiency at training
- Fast input pipelines
- Efficient inferencing
This is a descriptive series at a high-level, there will be another series on implementing some of these standard concepts but if you would love to get fully hands-on before then, I suggest you take the Advance Machine Learning with Tensorflow on GCP course by Google ML team for a start.
Design High-Performance ML systems
High-performance ML systems could mean different things to different companies depending on the project goal. This could mean a powerful ML system that has the ability to handle a large dataset, a system that can do the job as fast as possible, a system that has the ability to train for a long period of time, or even achieving the best possible accuracy, etc. These many factors and characteristics of high-performance ML systems are important, but one key aspect is the time it takes to train a model. Assuming we wish to train a model to attain a specific evaluation measure (e.g. accuracy), we could design a high-performance ML system from the infrastructure performance perspective. When allocating or provisioning for infrastructure to the machine learning tasks, we should consider some key factors such as time-to-train, budget, inference, and prediction time.
Time-to-train and budget: To optimize the training budget, one needs to consider at least time, cost, and scale.
- Time: How long are you willing to spend on the model training? Imagine you are training a recommender system to recommend products to customers on a daily basis. This means you have a maximum of 24 hours to finish your ML cycle from training to deployment. The ideal maximum time to train such a model should be 16 hours so as to have time for testing and deployment, etc.
- Cost: How much are you willing to spend on model training in terms of computing cost? This falls back to business decisions: You wouldn’t want to train for 16 hours every day if the incremental benefit of this is not sufficient.
- Scale: How much data will you be training on? Would it be better to train on a single, more expensive machine or multiple cheaper machines?
In general, you will want to tune performance to reduce training time, reduce cost, and increase the scale. The table below shows that training performance could be bound by one of the three sub-headings (input/output: how fast is the data ingestion component for each training, CPU: how fast can you compute the gradient for each training steps, and memory: how many weights can you hold in memory).

Faster Input Pipeline
Apart from carrying out optimizations for training the model, you can make the effort to improve the performance of the input/output pipeline which becomes very important if the model is I/O bound when using multiple GPU or TPU.
When running on a single GPU or TPU, the input pipeline might be able to keep with the speed at which the model requests for preprocessed data batches just as shown in the figure below.
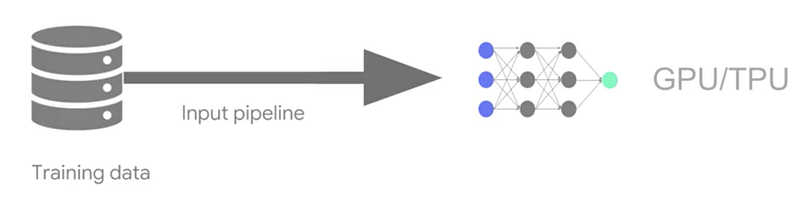
There will be a need for input pipeline optimization when the model is running on multiple GPU/TPU to prevent bottlenecks during which the iteration could have finished and you are waiting for the next preprocessed data batch, which might not yet be available.
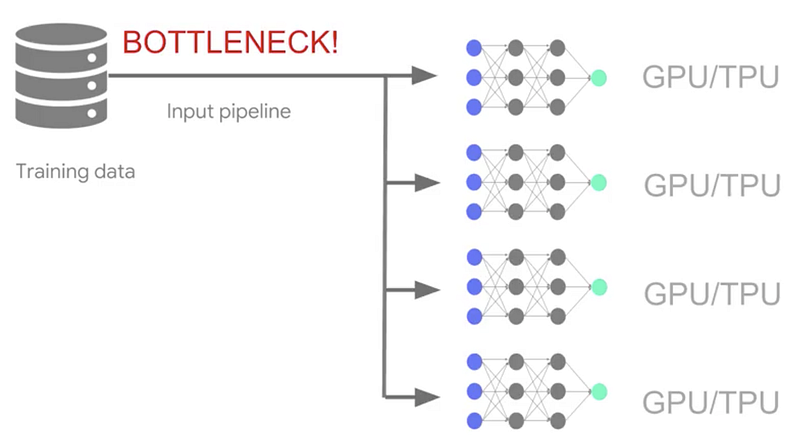
To avoid prevent these bottlenecks, we can make the pipeline more efficient by doing any of the following if we are using TensorFlow for modeling.
- Direct Feed from Python: This is the easiest but slowest as it requires the entire dataset to be in memory and thus makes the pipeline memory bound.
- Native Tensorflow Ops: This is difficult to do compared to the direct feed from Python, but worth doing as this ensures data security and privacy.
- Transformed TensorFlow Records: This could be a pain to do as there will be a need to account for this conversion in the ML system’s architecture, which could lead to lots of changes, but it is the most efficient. We can achieve this using Apache Beam, TFX, etc.
Efficiency at Inferencing
Designing a high-performance ML system is not complete without considering the efficiency of the system at inference. We could list and evaluate the ML system inference performance based on throughput (query per second), latency (how long does a query actually take), and cost in terms of infrastructure and maintenance depending on what is best for the problem.
Inference and Prediction Time: Another aspect of the design of a high-performance ML system is in prediction. During inferences, performance differs depending on the mode of prediction you have chosen, which could be a batch prediction, online, offline, or even hybrid.
For batch prediction, the factors in consideration for a high-performance system are time, cost, and scale.
- Time: How long does it take you to do all the predictions?
- Cost: Is the prediction cost-effective?
- Scale: Is there a need to use distributed machines or just a single machine?
For Online Prediction: Since the user is waiting for the prediction, there will be no need for carrying out predictions on a distributed graph. Instead, a machine can be used but scaled out to microservice (GKE, ML-Engine, etc.) to handle multiple requests. The performance can then be a measure of QPS (query per second).
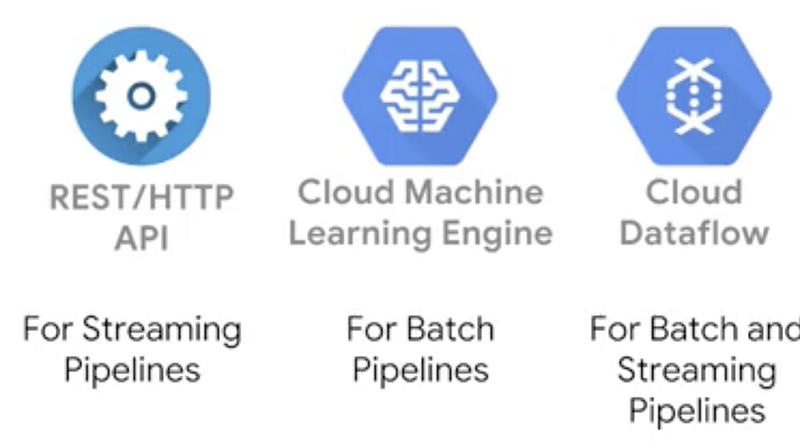
We could achieve this efficient inferencing with three different options on GCP depending on the kind of pipeline we are implementing as shown in the figure below:
Wrapping up
We have been able to highlight the various ways we can design high-performance ML systems to maximize efficiency at training, input pipeline, and at the inference stage. This is a general overview as there are many other factors in each that could be considered as well. In Part 4, the concluding part of this series, the focus will be on building hybrid cloud machine learning models, Kubeflow for hybrid cloud, and optimizing TensorFlow graphs for mobile.
Do find time to check out my other articles and further readings in the reference section. Kindly remember to follow me so as to get notified of my publications.
Connect with me on Twitter and LinkedIn
Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for data science, machine learning, and deep learning practitioners. We’re committed to supporting and inspiring developers and engineers from all walks of life.
Editorially independent, Heartbeat is sponsored and published by Comet, an MLOps platform that enables data scientists & ML teams to track, compare, explain, & optimize their experiments. We pay our contributors, and we don’t sell ads.
If you’d like to contribute, head on over to our call for contributors. You can also sign up to receive our weekly newsletters (Deep Learning Weekly and the Comet Newsletter), join us on Slack, and follow Comet on Twitter and LinkedIn for resources, events, and much more that will help you build better ML models, faster.