Building Microservices: Using Node.js with DDD, CQRS, and Event Sourcing — Part 1 of 2
tl;dr: I aim to help you learn and apply CQRS and event sourcing using a modern approach.
Companies often have a desire to scale software from the very beginning. In this article, we will discuss an approach to building large-scale distributed microservice-based architectures using DDD, CQRS, and event sourcing.
The event sourcing pattern implies that events are the source of truth. CQRS and event sourcing based systems are often considered as building blocks for microservice architectures. Important questions can come up when CQRS and event sourcing is introduced — things like what events are required to carry out a given domain responsibility? or do we even need events or event sourcing? Thus, CQRS adds complexity and is not suitable for most projects.
I plan to share with you a modern approach for applying the CQRS and event sourcing patterns — using Node.js and TypeScript. Please note that both the CQRS and event sourcing patterns can be applied independently of one another. For my example project, I used an event store called “Event Store” designed by Greg Young (the guy who coined the term “CQRS”). Event Store makes the persistence and streaming of events, atomic — an atomic transaction implies a series of operations that occur either entirely or not at all, it must imply data integrity.
In Part 1 of this article, we will go over the concepts applied; and in Part 2, we will look at the actual implementation of these concepts in more detail.
What are microservices?

Microservices are a software development technique — a variant of the service-oriented architecture style that structures an application as a collection of loosely-coupled services with a bounded context.
One great benefit of using the microservice architecture is that it allows you to choose the right tool for the job every time, always allowing for technical diversity—polyglot systems that focus on enterprise need. Additionally, you can think more clearly in terms of “domain knowledge” instead of “database schemas.” Anyone can understand domain knowledge — you do not have to be a developer to understand it.
The most beautiful creations both man-made and natural are a combination of singular useless parts (i.e. cells and structures), intelligently combined together towards a unified purpose — all vitally important and all principally useless on their own. In the very same nature, a microservice is dependent on things like networks, gateways, security, cloud infrastructure, and service orchestration to govern and fulfill its blueprint or legacy.
Thinking long-term when designing your microservice architecture can help to reduce flaws in design earlier on — the onion architecture and the hexagonal architecture are some ways of thinking about your microservice architecture design. Additionally, IO automata is an approach for designing event sourcing systems.
Patterns applied within microservice architectures can be broken down into three different categories…
application patternsapplication infrastructure patternsinfrastructure patterns
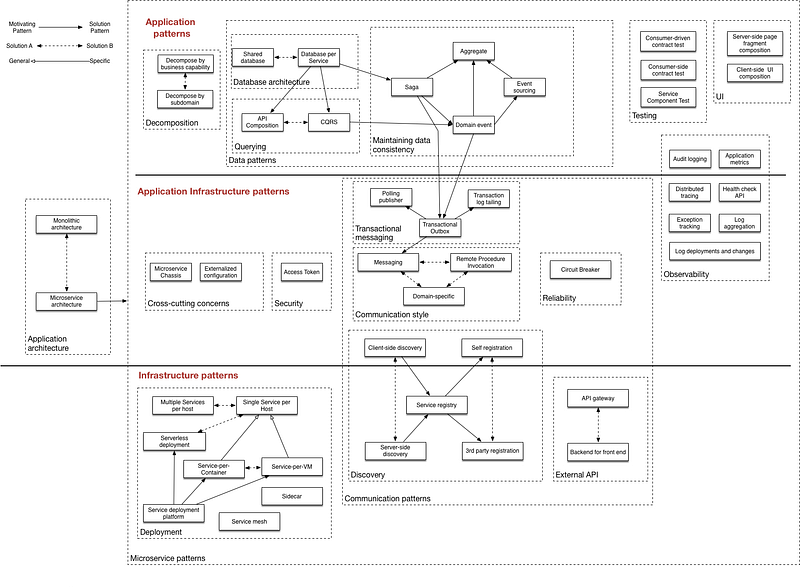
Woah! That is a lot of stuff but do not get overwhelmed, we will not go in-depth on all the microservice patterns labeled above — I only wanted to bring awareness to all of these known patterns. Companies like Netflix and Microsoft contribute to discovering and applying these patterns in production systems throughout the globe.
In this article, let us keep things simple and focus only on creating a single microservice with “Users” being the domain-model boundary.
Something to keep in mind is that many microservices can cover a single domain boundary, but a single microservice should not cover more than one domain boundary.
(N) Services => Bounded Contexta trade-off: eventual consistency
Distributed systems introduce something called “eventual consistency” — a form of weak consistency. This means that if no new updates to an object are made, then eventually all reads will return the last updated value and everyone is happy. Eventual consistency is a factor that enables microservices to be distributed.
The CAP theorem states that when you are designing a distributed system you cannot achieve all three of Consistency, Availability and Partition Tolerance. You can pick only two. (source)
technology heterogeneity
Generally, microservices should not share anything (i.e. databases) between each another — allowing microservices to live independently of one another. Microservices are meant to follow the loose-coupling principle. A team focused on building microservices should be free to discover and apply the latest technologies that are better suited for the job. It goes without saying that the DRY principle (don’t repeat yourself) is not always suited within microservice architectures — more accurately, the DRY principle simply means to not duplicate code. My general rule is to not violate the DRY principle within a microservice but be relaxed to violating the DRY principle across many microservices.
The process of creating a new microservice is meant to be fast, easy, and reliable.
The statement above presumes microservices to be easier to continuously deliver — a benefit of applying the microservices architecture in the first place. To speed up the development and creation of new microservices, a microservice chassis can be employed to address cross-cutting concerns such as logging, health checks, and service registration and discovery.
communication between microservices
Microservices need a lightweight approach for communicating with one another. HTTP/1.1 is certainly a valid protocol but there are better options — especially when considering performance. One approach is to use gRPC, an open-source RPC framework that is meant to be performant and efficient.
gRPC uses HTTP/2 for transport, Protocol Buffers as the interface description language, and provides features such as authentication, bidirectional streaming and flow control, blocking or nonblocking bindings, and cancellation and timeouts. (source)
deployment cycles
Developers may use Docker when building microservices. Docker allows you to replicate your development environment across multiple machines — allowing for faster developer onboarding, efficiency, and all of the above.
For a “production-like” environment, you can deploy containers to Docker Swarm, a container orchestrator. Container orchestrators allow you to run multiple instances of an application running behind a port. Kubernetes is an open-source production-grade container orchestration service.
acknowledge failures as they will occur
Distributed systems reduce an application’s SLA (service level agreement) uptime — things can fail more, and they will. It is important to test for failures and handle all failures gracefully. The key is to expect everything to fail at some point, as this allows you to build a more fault-tolerant system. Observability into your system is a vital factor for obvious reasons, such as monitoring failures and tracking improvements.
My project overview
what’s under the hood?
A simple RESTful microservice with CQRS/ES built using an open-source enterprise-level Node.js server-side framework called Nest.js.
Nest uses modern JavaScript, is built with TypeScript (preserves compatibility with pure JavaScript) and combines elements of OOP (Object Oriented Programming), FP (Functional Programming), and FRP (Functional Reactive Programming). (source)
Users API — handles commands that append events to User aggregates; queries are not implemented on purpose allowing you to choose a preferred database technology of choice for obtaining denormalized data. The Users API also does not implement authentication or authorization out-of-the-box and is meant for demonstration purposes only.
Here is a list of features that I believe are important to keep in mind…
- 👮🏽 Guidelines
- 📝 Living Documentation
- 👨🏼💻 Developer Productivity
- 🏎 Performance
- 🚀 Scalability
- 🧬 Adaptability
- 🧪 Testability
These features help keep the codebase maintainable, reliable, scalable — and also allow developers to ship new features faster to meet user and business demand on-time and under budget.
Additionally, the bigger a team gets, the more it helps to enforce common guidelines. The open-source API design guideline (source) created by the good team over at PayPal is a great example of API guidelines. Other open-source API guidelines exist and some of them may be found here. As long as all microservices follow a common design path, odds are you will experience lesser issues — this is also an oxymoronic statement because microservices should be independent of one another.
DDD in a nutshell
Domain-driven design (DDD) is an approach to software development for complex needs by connecting the implementation to an evolving model. The premise of domain-driven design is the following: placing the project’s primary focus on the core domain and domain logic; basing complex designs on a model of the domain; initiating a creative collaboration between technical and domain experts to iteratively refine a conceptual model that addresses particular domain problems. (source)
TypeScript in a nutshell
TypeScript is a strict syntactical superset of JavaScript, and adds optional static typing to the language. TypeScript is designed for development of large applications and transcompiles to JavaScript. (source)
Developers tend to make mistakes caused by human error. TypeScript can help reduce some bugs in code as the team size grows, by offering type inference all while offering JavaScript interoperability and ES6+ features.
Fun fact: Anders Hejlsberg, lead architect of C# and creator of Delphi and Turbo Pascal, has worked on the development of TypeScript.
Docker in a nutshell
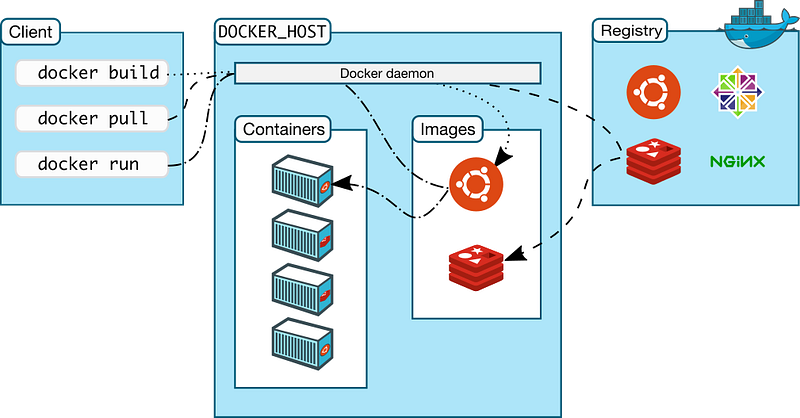
Docker allows an application to run in a container (guest OS) on your machine (host OS)—it enables the utilization of operating-system level virtualization.
Docker is one of my favorite technologies — after I had learned it, I could not sleep for some days purely out of excitement. It is one of those technologies that comes around after many moons have passed. Virtualization has been here for some time now, but Docker made it even easier to apply it in both development and production environments.
We will use Docker to launch the project locally and experience it for ourselves. If you are new to Docker do not worry, it is quite easy to get started with using my project as I have already created the Docker files necessary to run the project. There is something called a Docker compose file (docker-compose.yml) which is used to launch an instance of the Users microservice as well as the Event Store, on their respective ports — scripts have been added to make it even easier to spin up and tear down these instances.
To use Docker, you will need to have it installed on your machine. I have a Mac computer so I am using Docker Desktop for Mac — feel free to install Docker however you please.
I recommend using Docker Desktop for local environments.
Fun fact: Docker Desktop ships with Kubernetes, a production-grade service orchestration platform open-sourced by our friends at Google.
getting started
- clone the repo on GitHub https://github.com/qas/examples-nodejs-cqrs-es-swagger
- follow the installation instructions via the README
- Fire up all Docker service instances by running the following commands
$ ./scripts/up.sh ## to start
$ ./scripts/down.sh ## to stopproject scope
commands — actions users take
CreateUserCommand => [UserCreatedEvent]
WelcomeUserCommand => [UserWelcomedEvent]
UpdateUserCommand => [UserUpdatedEvent]
DeleteUserCommand => [UserDeletedEvent]events — reactions from commands
UserCreatedEvent => [UserCreatedSaga]
UserWelcomedEvent
UserUpdatedEvent
UserDeletedEventsagas — transactions from events
UserCreatedSaga => [WelcomeUserCommand]Every action causes a reaction
Event-driven architecture applies a paradigm called reactive programming — which is a fancy way of saying programming with asynchronous data streams. Streams can be simply defined as ongoing events ordered in time.
I will explain what event sourcing is using my project as an example. If you are new to event sourcing, please read this article by Martin Fowler.
A request can be described as a command (action) that causes an event (reaction).
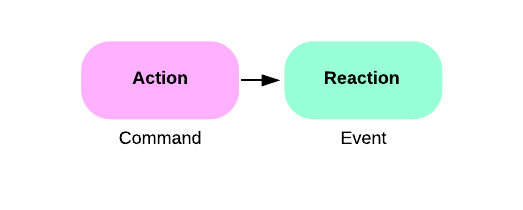
commandsare dispatched to a respective command handler to validate the command and run some domain logic as part of the contracteventsare dispatched to a respective event handler to update materialized state based on the event
Instead of using schemas to define business processes, events can be used to define business processes. Organizations practice something called “event storming,” where knowledge is acquired from conversations and then applied to domain-models as events. Event storming can likely improve cross-team coordination.
Event names are best defined in past-tense format.
To keep things simple and easy to understand, I make use of only 4 events in my project. Let’s have a look at the events covered in this project…
UserCreatedEvent
UserWelcomedEvent
UserUpdatedEvent
UserDeletedEventSimple enough, right?
event contracts
The event contract defines an event, it should contain data on how to serialize an object into a transportable data structure and rehydrate the object back into form.
The logical meaning of an event contract is influenced by domain-driven design—the name of the event and its field values.
separation of concerns
CQRS (Command Query Response Segregation) is a simple concept that implies separating your write models (commands) from your read models (queries). By using a pattern called event sourcing, a command causes an event to be stored — which is later published to subscribers of that event. An event handler may even contain logic to update some materialized state — that can be rendered using queries.
Command => Store Event => Publish Event => Materialize View
Query => Return Materialized ViewFor some situations, this separation can be valuable, but beware that for most systems CQRS adds risky complexity. — Martin Fowler (source)
My project covers the “write” (commands) side of CQRS since it is the more complicated counterpart — I leave it up to you to finish the “read” (queries) side.
CQRS plainly introduces the concept of using events to communicate changes to an application’s state. Event sourcing introduces the notion of storing the events in an immutable event log (event store) and modeling materialized state changes based on that event log.
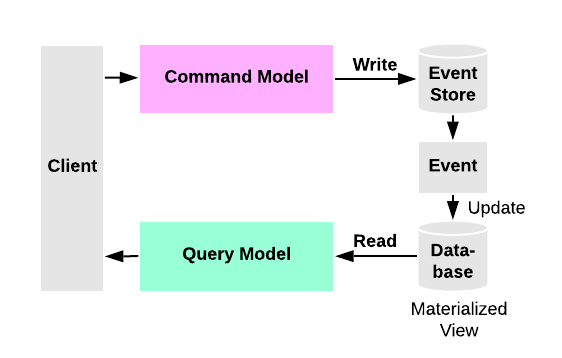
CQRS is separate from event sourcing but they are usually grouped together, however, event sourcing is not a requirement to apply the CQRS pattern within a given project. A given state can be represented as an append-only sequence of events. Every single “write” must be followed by an update to its respective “read” model.
store events using event sourcing
Event sourcing is the act of storing all changes to an application as events rather than only storing current changes — in other words, you append every event ever made in your application. Not being able to overwrite an existing event is a feature of event sourcing. Additionally, the concept of storing events is not new and is also seen in log tailing systems.
Event Sourcing ensures that all changes to application state are stored as a sequence of events. (source)
event sourcing has a purpose
The purpose of using event sourcing is to generate a given state in time using events. Event projection supposes that all events tracked as deltas are replayable — an application using transactional IDs can also replay events beyond the borders of a single microservice allowing visibility into the complete lifecycle of a user request.
The simplest way to think of using Event Sourcing is to calculate a requested application state by starting from a blank application state and then applying the events to reach the desired state. It’s equally simple to see why this is a slow process, particularly if there are many events. (source)
event sourcing vs. CRUD
The CRUD (Create, Read, Update, Delete) pattern implies that models are mutable. The event sourcing pattern implies that models are immutable. By design, event sourcing only supports the “Create” and “Read” philosophy of the CRUD pattern.
Sagas are long-lived transactions
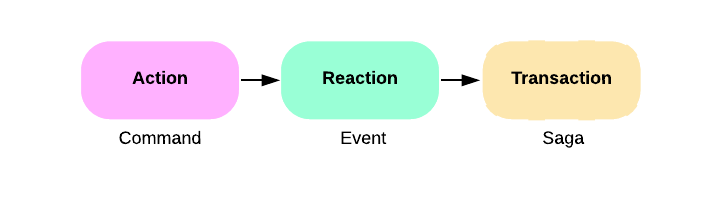
A long lived transaction that can be broken up into transactions, but still executed as a unit. Both the concept and its implementatlon are relatively simple, but in its simplicity lies its usefulness. (source)
Implement each business transaction that spans multiple services as a saga. A saga is a sequence of local transactions. Each local transaction updates the database and publishes a message or event to trigger the next local transaction in the saga. If a local transaction fails because it violates a business rule then the saga executes a series of compensating transactions that undo the changes that were made by the preceding local transactions.
Vocabulary reference
domain model — In software engineering, a domain model is a conceptual model of the domain that incorporates both behavior and data. In ontology engineering, a domain model is a formal representation of a knowledge domain with concepts, roles, datatypes, individuals, and rules, typically grounded in description logic. (source)
bounded-context — Bounded Context is a central pattern in Domain-Driven Design. It is the focus of DDD’s strategic design section which is all about dealing with large models and teams. DDD deals with large models by dividing them into different Bounded Contexts and being explicit about their interrelationships. (source)
aggregate — Aggregate is a pattern in Domain-Driven Design. A DDD aggregate is a cluster of domain objects that can be treated as a single unit. An aggregate will have one of its component objects be the aggregate root. (source)
event storming — Event storming is a workshop-based method to quickly find out what is happening in the domain of a software program. The basic idea is to bring together software developers and domain experts and learn from each other. To make this learning easier, event storming is meant to be fun. (source)
event sourcing — Event sourcing is a great way to atomically update state and publish events. The traditional way to persist an entity is to save its current state.
event store — Events are persisted in an event store. Not only does the event store act as a database of events, but it also behaves like a message broker. It provides an API that enables services to subscribe to events. Each event that is persisted in the event store is delivered by the event store to all interested subscribers. The event store is the backbone of an event-driven microservices architecture. (source)
event projection — Event projections are about deriving current state from a stream of events.
containers — A container is a standard unit of software that packages up the code and all its dependencies so the application runs quickly and reliably from one computing environment to another. (source)
orchestration — Applications are typically made up of individual containerized components (often called microservices) that must be organized at the networking level in order for the application to run as intended — the process of organizing multiple containers in this manner is known as container orchestration. (source)
Next up: Part Two
Stay tuned for more! In part two, we will cover the implementation in detail.
Other Info
Below, you will find a link to the project as well as my contact info.
- Project’s GitHub
- Qasim Soomro’s website
- Qasim Soomro’s LinkedIn
- Qasim Soomro’s AngelList
- Qasim Soomro’s Twitter
Resources
- Martin Fowler — CQRS (article)
- Greg Young — Event Sourcing (video)
- MSDN — CQRS Journey (article)
- The Twelve-Factor App — 12factor.net (website)
- Eric Evans — Domain-Driven Design, Tackling Complexity in the Heart of Software (book)
- Christopher Richardson — Microservice Patterns (book)
- PayPal — API Guidelines (website)
- Kanasz Robert — Introduction to CQRS (source)
- Werner Vogels — Eventually Consistent (source)
Ad