
Building an Apache Airflow configured with Local Executor and Spark Standalone Cluster with Docker
A guide on how to set up an environment to work with Airflow and Spark

Brief context
For a Data Engineer, it is only natural to create ETL processes on a daily basis. And, apparently, there is no better solution for this purpose than Apache Spark. These ETL processes should also be automated with a tool such as Apache Airflow.
Recently, my team and I hit a problem with how to run DAGs in parallel without overloading the system. To solve this problem, a development environment was created with Docker, where Apache Airflow with Local Executor was responsible only for the orchestration of DAGs, and Apache Spark in Standalone Mode for data processing.
In this article, I will share with you how to create the development environment that includes Apache Airflow and Apache Spark in Standalone Mode.
Component overview
Apache Airflow
Apache Airflow is an open-source tool to author, schedule, and monitor workflows programmatically. It is one of the most robust platforms used by Data Engineers for orchestrating workflows or pipelines.
To run instances of tasks, Apache Airflow has a special mechanism called Executor. There are many different executors for different purposes. In our case, we need a lightweight executor that can run tasks in parallel.
The LocalExecutor is a perfect match for our solution. He completes tasks in parallel that run on a single machine.
To store Airflow metadata we also need a database for this purpose we use PostgreSQL.
After deciding which executor and which database to use, the following architecture was created, that allows individual airflow components to work in tandem using docker containers.
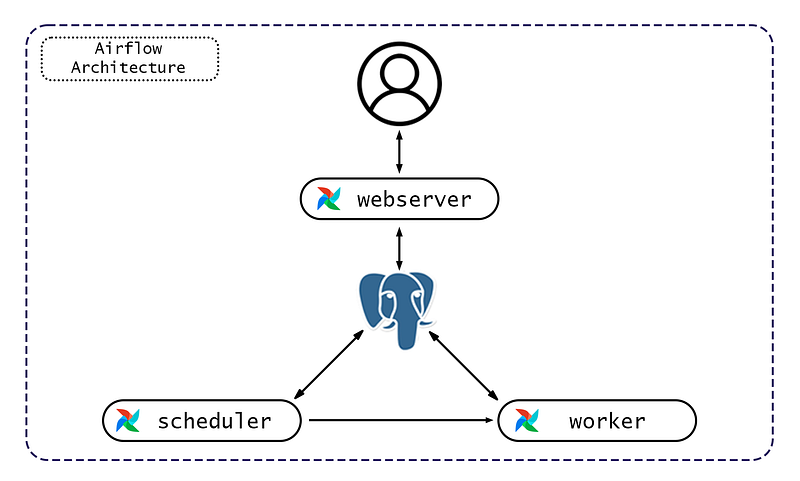
- The scheduler is the main part of Airflow. It monitors, updates, and triggers the task instances once their dependencies are complete.
- The worker executes the tasks given by the scheduler.
- The web server allows interaction with the system via web UI.
Apache Spark
After creating the Airflow cluster, we encountered a second problem with container overload.
Airflow has a lot on its plate (planning, monitoring, etc.), and we just added one more thing — run the Spark tasks in the same container, which caused an overload problem. To resolve this issue we added to the cluster a separate module that will be responsible to execute Spark jobs
Apache Spark is an open-source, general-purpose distributed data processing engine that is suitable for use in a wide range of circumstances. It can be run in different modes, but we were interested in Standalone Mode, which allows us to deploy the Spark cluster on a single machine.
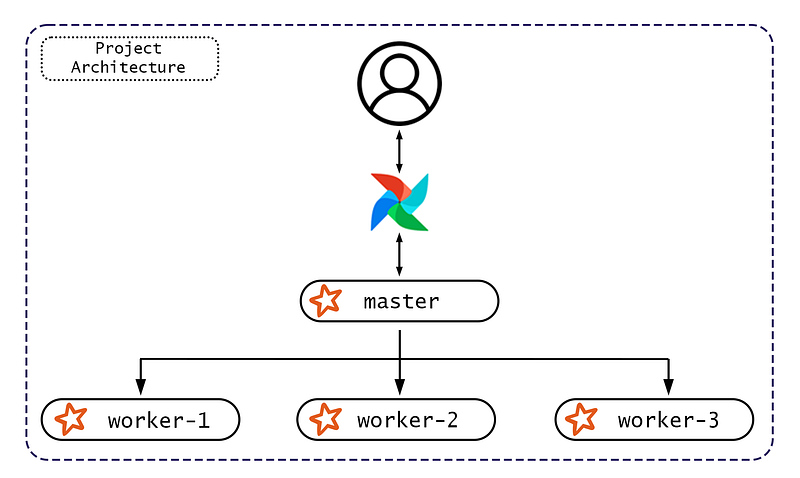
- The master is the driver that runs the main program where the spark context is created.
- The worker consists of processes that can run in parallel to perform the tasks scheduled by the driver program.
How to run the environment
Default Version
- Apache Airflow 2.3
- Apache Spark 3.1.2
Prerequisites
Download Project
git clone https://github.com/mbvyn/AirflowSpark.git
Run containers
Inside the AirflowSpark/docker/
docker-compose up -d
Check the access
login: airflow
password: airflow
Configure Spark Connection
- Go to Connection
Admin >> Connections
- Add a new record like in the image below
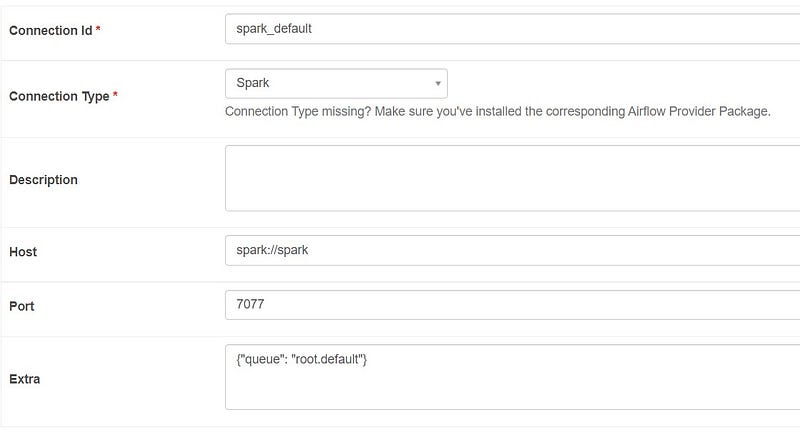
Increase the number of Spark Workers
It is possible to increase the number of workers and specify their memory and cores. Just add the following code to docker-compose.yml and change SPARK_WORKER_MEMORY and/or SPARK_WORKER_CORES as you wish.
Conclusion
Airflow and Spark are some of the most important tools in Data Engineer’s work. Having such an environment configured on a local machine, which was described in this article, allows you to easily develop and test your solutions.
You can also check out the GitHub repository for additional information and examples of DAG and spark jobs.
Hope this article was helpful. See you!