Build a Transformer in Pytorch
Transformers are a powerful model in modern machine learning, particularly in Natural Language Processing (NLP) tasks such as language translation and text summarization. They have revolutionized the field by replacing Long Short-Term Memory (LSTM) networks due to their ability to handle long-range dependencies and parallel computations. At the heart of Transformers is the attention mechanism, specifically the concept of ‘self-attention,’ which allows the model to weigh and prioritize different parts of the input data. This mechanism is what enables Transformers to manage long-range dependencies in data. It is fundamentally a weighting scheme that allows a model to focus on different parts of the input when producing an output. This mechanism allows the model to consider different words or features in the input sequence, assigning each one a ‘weight’ that signifies its importance for producing a given output.
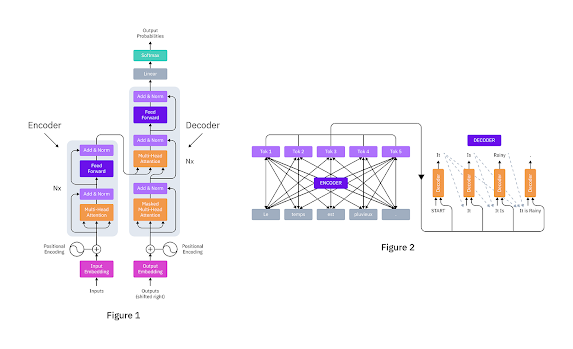
Transformer Implementation Steps
- Setting up PyTorch: Before diving into building a Transformer, it is essential to set up the working environment correctly. First and foremost, PyTorch needs to be installed. PyTorch (current stable version — 2.0.1) can be easily installed through pip or conda package managers.
- Importing the libraries and modules: The first step in building a Transformer is to import the necessary libraries and modules. The following libraries are required: torch, torch.nn, torch.nn.functional, and torch.optim.
- Defining the basic building blocks: The next step is to define the basic building blocks of the Transformer. These include Multi-head Attention, Position-Wise Feed-Forward Networks, and Positional Encoding.
- Building the Encoder block: The Encoder block is responsible for encoding the input sequence. It consists of a stack of identical layers, each of which has two sub-layers: a multi-head self-attention mechanism and a position-wise fully connected feed-forward network.
- Building the Decoder block: The Decoder block is responsible for decoding the encoded input sequence. It also consists of a stack of identical layers, each of which has three sub-layers: a multi-head self-attention mechanism, a multi-head attention mechanism over the output of the Encoder block, and a position-wise fully connected feed-forward network.
- Combining the Encoder and Decoder layers to create the complete Transformer network: The final step is to combine the Encoder and Decoder layers to create the complete Transformer network.
Now let’s build the model with Pytorch step by step
Before we begin, make sure you have PyTorch installed. If not, you can install it using:
pip install torch torchvision
Step 1: Importing Libraries
Start by importing the necessary libraries:
import torch
import torch.nn as nn
import torch.optim as optimStep 2: Define the Transformer Model
The Transformer architecture comprises an encoder and a decoder. We will focus on the encoder for simplicity. Let’s define the basic components of the Transformer:
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1):
super(TransformerEncoderLayer, self).__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
def forward(self, src):
src2 = self.self_attn(src, src, src)[0]
src = src + self.dropout(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(torch.relu(self.linear1(src))))
src = src + self.dropout(src2)
src = self.norm2(src)
return src
class TransformerEncoder(nn.Module):
def __init__(self, encoder_layer, num_layers):
super(TransformerEncoder, self).__init__()
self.layers = nn.ModuleList([encoder_layer() for _ in range(num_layers)])
def forward(self, src):
for layer in self.layers:
src = layer(src)
return srcStep 3: Instantiate the Model
Now, let’s create an instance of our Transformer model:
d_model = 512 # Adjust according to your requirements
nhead = 8
num_layers = 6
transformer_model = TransformerEncoder(TransformerEncoderLayer(d_model, nhead), num_layers)Step 4: Data Preparation
Prepare your data for training. For simplicity, we’ll use a dummy dataset:
# Load your dataset and preprocess as needed # For example, tokenization, padding, etc.
Step 5: Loss Function and Optimizer
Define the loss function and optimizer for training:
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(transformer_model.parameters(), lr=0.001)Step 6: Training the Model
Now, let’s train the Transformer model:
num_epochs = 10
for epoch in range(num_epochs):
for data in dataloader: # Iterate over your data batches
inputs, targets = data
optimizer.zero_grad()
outputs = transformer_model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()Step 7: Evaluate the Model
After training, it’s essential to evaluate the model on a separate test set:
# Prepare your test data
# Evaluate the model
with torch.no_grad():
for test_data in test_dataloader:
test_inputs, test_targets = test_data
test_outputs = transformer_model(test_inputs)
# Perform evaluation metrics calculationThat was it. We built and trained a Transformer model using PyTorch. This tutorial covered the fundamental steps, but remember that tuning hyperparameters, adjusting the model architecture, and fine-tuning are crucial for achieving optimal performance in real-world scenarios.





