
Boosting Password Security with Natural Language Understanding: Building a Simple Password Strength Checker with BERT Transformer
The final model is trained on 2 million most common and randomly generated passwords, works well (weighted accuracy 99.4%) for passwords not exceeding 10 symbols, and can be freely used via Huggingface

In an era where cyber threats are more pervasive than ever, ensuring the security of online accounts is of paramount importance. Passwords are often the first line of defense against unauthorized access, making their strength a critical factor in safeguarding our digital lives.
In this article, I show how to enhance password security by harnessing the power of the BERT (Bidirectional Encoder Representations from Transformers) transformer model, one of the most common up-to-date publicly available models in Natural Language Understanding.
The first step is to take the publicly available dataset of about 1 million of the most common passwords, also publicly available in Kaggle, and to mix them with an equal sample of 1 million randomly generated complex passwords with lengths between 6 and 10 symbols, including lower and upper cases letters, digits, and common special characters.
Then, I use one of the available pre-trained HuggingFace models to further train the data — Google’s BERT case-sensitive model — which has about 108 million trainable parameters.
The final code for data selection and training is available as a Kaggle notebook.
The training process takes about 45 minutes using NVIDIA TESLA P100 GPU available for Kaggle users, and increases the overall accuracy (based on the test set) from about 50% to 99.4%:

Picking some of the data samples also shows a reasonable performance of the model:
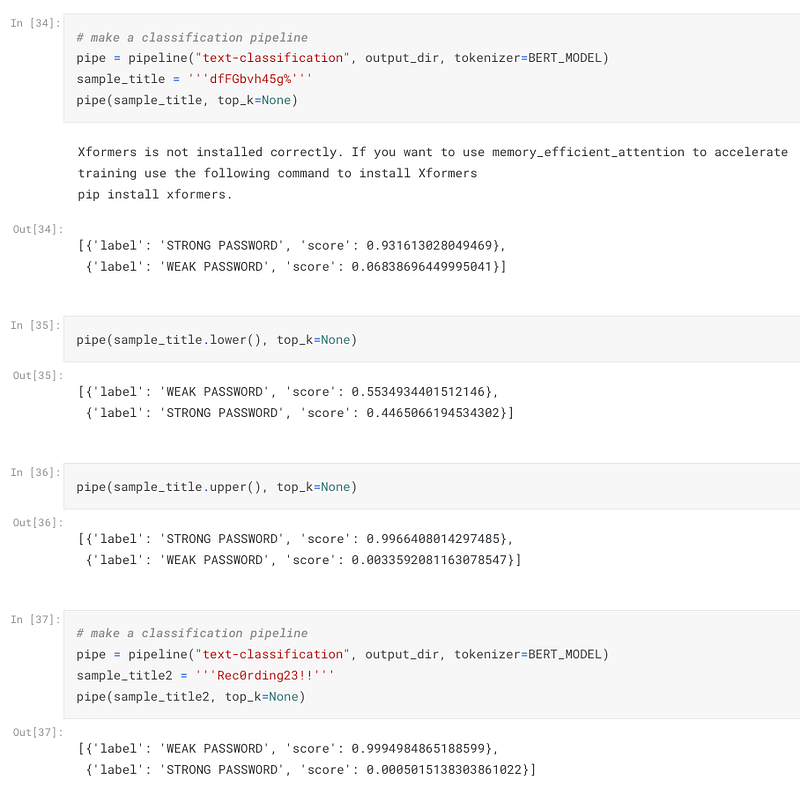
The final model can be freely used via HuggingFace. Note however that in hosted inference API, due to the default (uncased) tokenizer, there is no difference between lower and upper case letters. To use the model with the correct tokenizer, one needs to invoke the model as follows:
# Use a pipeline as a high-level helper - need to specify cased tokenizer
from transformers import pipeline
pipe = pipeline("text-classification", model="dima806/strong-password-checker-bert", tokenizer="bert-base-cased")I hope these results will be useful for you. In case of questions/comments, do not hesitate to write in the comments below.




