
ARTIFICIAL INTELLIGENCE | VISUAL LANGUAGE MODEL
BLIP-2: when ChatGPT meets images
BLIP-2, a new visual language model capable to dialogue about images

ChatGPT shocked the world with its ability to converse naturally. However, ChatGPT cannot see. is it possible to have a model that can read an image and discuss it with a user?
Vision language models: what they are and why it is difficult
In recent years there has been much attention and research on language models (LMs). On the other hand, for a long time, images were analyzed using convolutional neural networks, until in recent years a way was found to fit transformers with images as well (Vision Transformers, ViTs). Why not combine the two worlds?
On the one hand, there are questions that cannot be answered by text alone or by images alone, so we need a model that can combine the two worlds. For example, tasks such as image captioning, visual question answering, and many more. Here we have seen why this would be extremely useful in more detail:
On the other hand, it is not easy to scale ViTs, there are problems with training stability although Google has found a promising way to solve this problem.
Also, training LMs is extremely expensive, in fact, you need a large amount of data and parameters. The scaling law states that some emergent behaviors are noticed only with a certain number of parameters. This has led to the race for ever larger and more capable models, but still, it has required enormous resources of both hardware and data. However, some studies show that perhaps such large models are not even necessary, but just need more attention to data.
In addition, in recent months the attention of both experts and newspapers has been focused on ChatGPT, a chatbot that can naturally answer endless questions, and is capable of programming, writing poetry, and many other things. On the other hand, ChatGPT is basically an LMs to which reinforcement learning has been applied, and a similar approach can be applied to any LMs:
So, we need a model that is capable of answering questions on both images and text (visual model) and maybe can answer questions with ChatGPT, say no more: BLIP-2 is what you need and the best part is that the checkpoints are there on HuggingFace.
BLIP-2: a general introduction
As the authors say there is some interest in Vision-language models, on the other hand, it was expensive to train them because they tried to use an end-to-end approach (basically you create a model and use both images and text to train it, this requires huge datasets of images and text).
On the other hand, if we have both good LMs and maybe a good vision model why not combine the two? This would make the model much more computationally efficient.
Pre-trained language models, in particular large language models (LLMs), offer strong language generation and zero-shot transfer abilities. To reduce computation cost and counteract the issue of catastrophic forgetting, the unimodal pre-trained models remain frozen during the pre-training. source (here)
Sounds very cool. In other words, you take a language model and a visual model and join them together, without even having to train them (they are frozen, after all). But is it really that simple?
In order to leverage pre-trained unimodal models for VLP, it is key to facilitate cross-modal alignment. However, since LLMs have not seen images during their unimodal pretraining, freezing them makes vision-language alignment in particular challenging. source (here)
A model trained on the text has not seen an image during training, and when we want to ask a textual question about an image we need the said alignment between the textual and visual components of our vision-language model (by the way, this is the most challenging part). How to solve this?
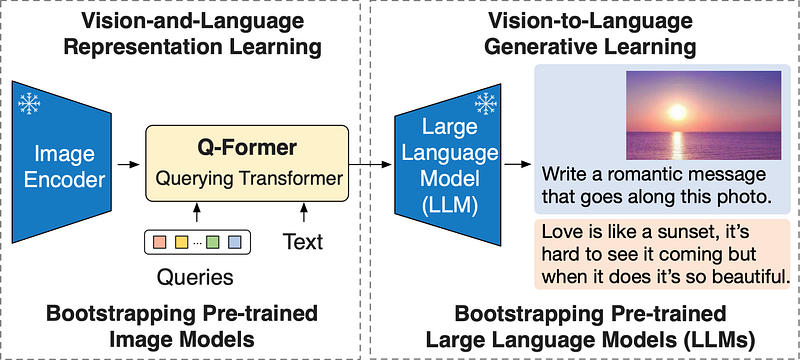
On the one hand, Google with Flamingo had tested an image-to-text generation loss, which, however, proved to be inefficient. The authors then suggest a new possibility
To achieve effective vision-language alignment with frozen unimodal models, we propose a Querying Transformer (Q-Former) pre-trained with a new two-stage pre-training strategy
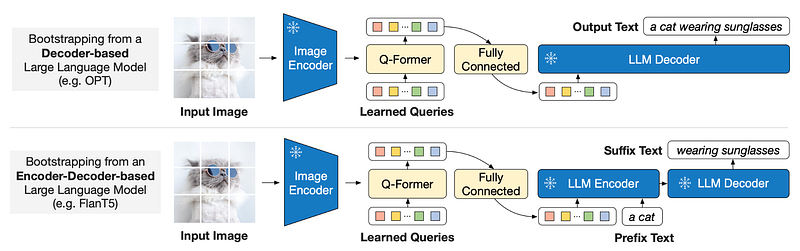
Precisely what is this Q-Former? a lightweight module (another small transformer) that increases the overall capabilities of the model. This mini-transformer learns query vectors, these vectors are used to extract information from the frozen visual encoder. In other words, the image goes through the visual model and we get a representation of the image, this is then adapted by the Q-former so that then the LMs can understand what is in the image and output to text.
During the training, the authors used vision-language representation learning so the Q-former can learn the visual representations most relevant to the text. Then they used vision-to-language generative learning to make sure that the output of the Q-former can be interpreted by LMs. So the Q-former basically is the bridge that connects the other two components of the model, extracts information from the visual model, and reprocesses it into something it can be understood by the language model.

Why BLIP-2 is important?
In the next section, we will analyze this in better detail, for the moment what are the most important contributions of this model?
- BLIP-2 effectively leverages both frozen pre-trained image models and language models. And it is doing this using a new lightweight and efficient component the Q-former. This allows BLIP-2 to achieve state-of-the-art performance on various vision-language tasks.
- Using the LLMs model (like FlanT5 and OPT), BLIP2 can leverage zero-shot image-to-text generation “that follows natural language instructions, which enables emerging capabilities such as visual knowledge reasoning, visual conversation, etc.”
- It is more compute-efficient than another state-of-the-art model, for example: outperforms Flamingo by 8.7% on zero-shot VQAv2, while using 54× fewer trainable parameters. In addition, the approach can be used for other vision-language models.
BLIP2 in details

The Q-former
Clearly, the heart of Blip2 is the Q-Former. In short, it is a transformer that extracts information from the frozen image encoder (a fixed number of output features, regardless of input image resolution) using a collection of trainable query vectors.
This is the only part of the model that is trainable, and it is connected to both the visual model and the language model. And it consists of two submodules:
- an image transformer that interacts with the frozen image encoder for extracting visual features.
- A second module is a text transformer that can function as both a text encoder and a text decoder.
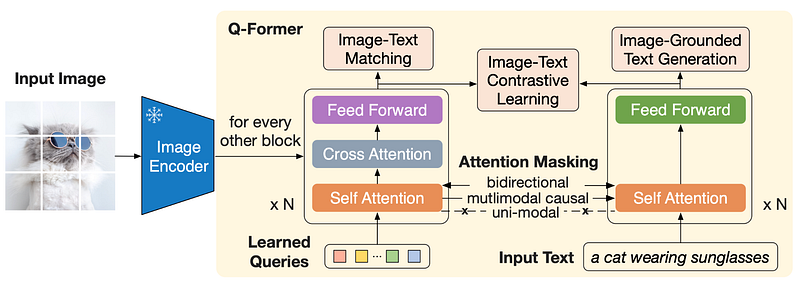
We create a set number of learnable query embeddings as input to the image transformer. The queries interact with each other through self-attention layers, and interact with frozen image features through cross-attention layers (inserted every other transformer block). The queries can additionally interact with the text through the same self-attention layers. Depending on the pre-training task, we apply different self-attention masks to control query-text interaction. source (here)
The authors then created a number of learnable query embeddings (the query vectors we mentioned earlier) that can interact with each other through self-attention layers, and with frozen image features through cross-attention layers. In fact, in the classical transformer, we have the self-attention head and the feed-forward layer, here instead we have in the middle of these components the cross-attention layer.
In addition, these queries can also interact with the text, using the self-attention layers. Depending on the pre-training task, the authors use different self-attention masks to control the interaction between queries and text.
The Q-Former is initialized using BERT-base weights, while cross-layer attentions are randomly initiated. In total, the Q-Former consists of only 188 M parameters (including queries). Although 188 M of parameters, sounds like a lot this is significantly less than approaches used in the past.
The authors used 32 queries, each with a dimension of 768 ( which is the same as the hidden dimension of the Q-Former). Notice, that is actually much smaller than the image features obtained from the visual model used (257x1024 for ViT-L/14). This is important because it forces the model to extract the most relevant visual features encoded by the visual encoder.

The training
The training is divided into two parts, as the Q-Former has to learn how to converse with the two frozen components.
Bootstrap Vision-Language Representation Learning from a Frozen Image Encoder
The main purpose of Q-Former is to learn how to extract the most informative visual representation of text. Okay, but how? To do this, the authors decided that the best way was to jointly optimize three pre-training objectives:
- Image-Text Contrastive Learning (ITC). Used to learn how to align an image representation and text representation, maximizing the mutual information between them.
- Image-grounded Text Generation (ITG). This teaches the Q-former how to generate text, given as input as image conditioning.
- Image-Text Matching (ITM). To learn fine-grained alignment between image and text representation.
The cool idea is that during all three training objectives, both the input format and model parameters are shared. The trick is to utilize a different masking strategy between queries and text, so you can control the interaction between them.
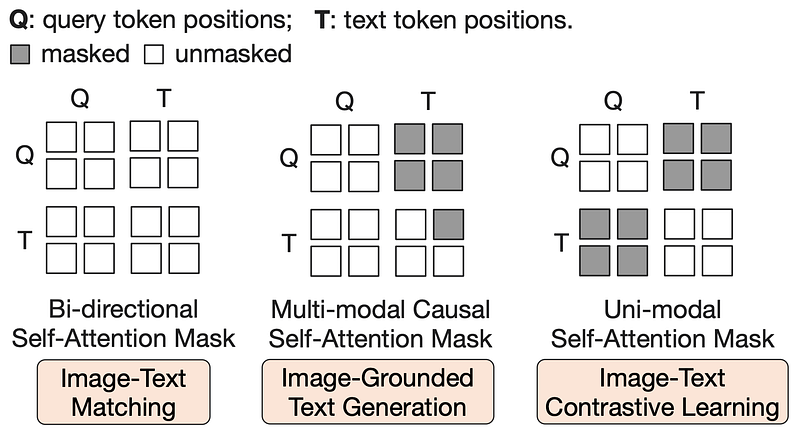
Bootstrap Vision-to-Language Generative Learning from a Frozen LLM
In the first part, we connected the visual model, now we need to connect the LMs. This is needed because we want to leverage the t the LLM’s generative language capability.
As shown in the figure, the output of the Q-Former is projected linearly to match the size of the text embedding of the LLM. This is to allow the LLM to embed the visual information extracted from the Q-former. In other words, the visual encoder extracts features from the image, but now the Q-former selects what is relevant information while filtering out what is irrelevant to the LLM.
This step is critical because it avoids the catastrophic forgetting problem by reducing the burden of the LLM to learn vision-language alignment.
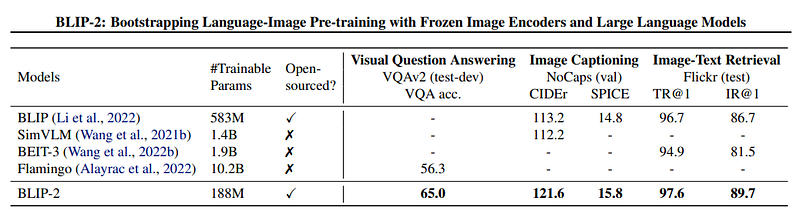
Results

The authors tested the model in different settings (especially in zero-shot image-to-text generation):
The model performed better than previous state-of-the-art models. Incidentally, these models have many more parameters to train and none of them are open-source.
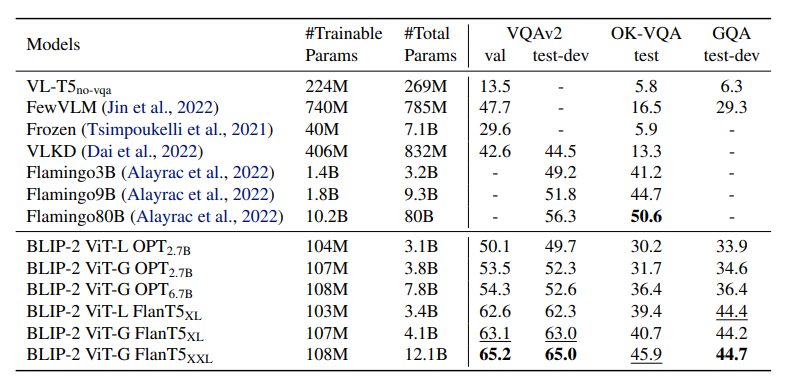
In addition, the results show that having a stronger image encoder or a stronger LM lead to better performance. In fact, ViT-G outperforms ViT-L, and using an instruction-tuned model such as FLanT5 performs better than OPT. In addition, these results show that the training approach of BLIP-2 can be used with any visual model and LMs.
However, the model has also some limitations
Recent LLMs can perform in-context learning given fewshot examples. However, our experiments with BLIP-2 do not observe an improved VQA performance when providing the LLM with in-context VQA examples. We attribute the lack of in-context learning capability to our pretraining dataset, which only contains a single image-text pair per sample. source (here)
In addition, the model can lead to some unsatisfactory results “due to various reasons including inaccurate knowledge from the LLM, activating the incorrect reasoning path, or not having up-to-date information about new image content”.

Can I use it?
Yes! it is open source, they have released the model on GitHub
- Here is the model sheet
- Here and here there are some tutorial resources if you want to use it
- Here you have the model checkpoints.
- Here (HuggingFace site) and here (SalesForce site) you can play with the model.
For example, you can use some of the examples they provide. Or you can input an image and ask a question about it.
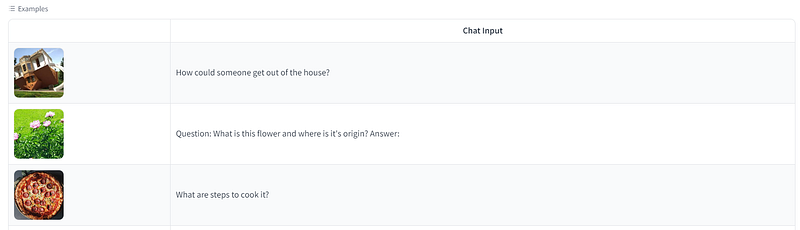
As an Italian, I have chosen to test the pizza prompt
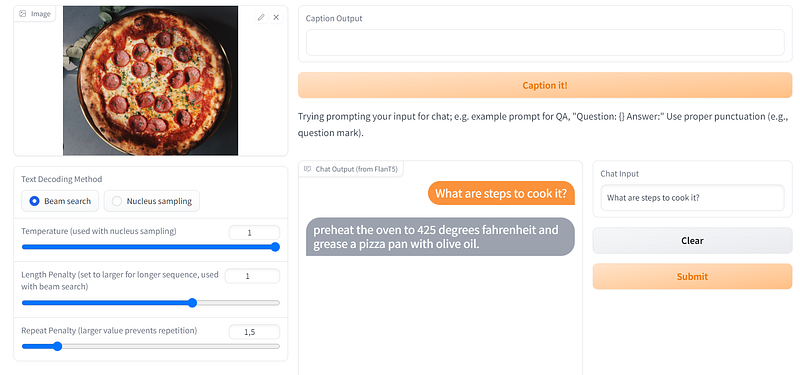
And I am actually satisfied with the result:

Conclusions
BLIP2 achieves state-of-the-art by using a compute-efficient method and shows how an LMs and a visual model can be put into communication in an elegant way. In addition, this is a step forward in multimodal conversational AI agents.
After all, many tasks need the model to analyze multiple types of input (images, text, and so on). In the future, there will be models that use different components to be able to analyze sounds, videos, and images and answer questions. Probably, instead of training a model from scratch using large datasets, they will use a model for each mode and a mini-transformer to integrate the various components. In other, words, the models of the future will be modular, composed of various submodules that talk to each other.
If you have found this interesting:
You can look for my other articles, you can also subscribe to get notified when I publish articles, and you can also connect or reach me on LinkedIn.
Here is the link to my GitHub repository, where I am planning to collect code and many resources related to machine learning, artificial intelligence, and more.
Level Up Coding
Thanks for being a part of our community! Before you go:
- 👏 Clap for the story and follow the author 👉
- 📰 View more content in the Level Up Coding publication
- 💰 Free coding interview course ⇒ View Course
- 🔔 Follow us: Twitter | LinkedIn | Newsletter
🚀👉 Join the Level Up talent collective and find an amazing job




