
BRAIN | AI | BRAIN RECORDINGS |
Beyond Words: Unraveling Speech from Brain Waves with AI
AI is capable of decoding speech from non-invasive brain recordings
META AI introduces a new machine learning model capable of decoding speech from brain recordings. This model could enable thousands of people with brain injuries to return to communicating
Reading a mind as a book

Every year many people lose the ability to communicate. This can happen due to accidents (brain injuries), strokes, or other degenerative diseases. On the other hand, it has been estimated by the United Nations that there are more than 1 billion people with some form of disability. In recent years, brain-computer interfaces (BCIs) have been successfully used to help people reduce the effects of these disabilities. These tools have also enabled people with speech paralysis to be able to communicate (up to 15 words per minute).
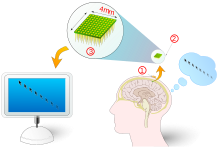
BCIs require an array of electrodes to be inserted into the cortex or otherwise in direct contact. Because this approach requires surgery it is obviously invasive and has risks. Scar tissue could form and body reactions to the presence of this foreign body (thus risking rejection and having to be removed).
Given the risks, several researchers have suggested decoding language from non-invasive recordings of brain activity. In general, two techniques have been proposed:
- magneto-encephalography (MEG). a functional neuroimaging technique where brain activity is mapped using a magnetometer.
- electroencephalography (EEG). is a diagnostic examination in which the electrical activity of the brain is recorded using electrodes.
Although these instruments have become increasingly sophisticated, they still produce a noisy signal that varies widely depending on individuals and instruments. Given their complexity, researchers rather than using the signals in their original form have preferred to derive hand-crafted features.
Many studies then conducted feature extraction and only trained a model. In addition, some of these models were built for one patient at a time. This approach clearly has scalability limitations.
Can we decode the brain?
Recently a paper tried to create a model that can decode speech from recorded signals.
The first problem in being able to create a model that can decode speech from brain signals is that we do not know how spoken words are represented in the brain. So before they could apply a model to subjects with a disease, the authors started with healthy subjects listening to recordings in their language.
In the approaches used so far, the model has been considered as if it were a special case of regression. Instead, the authors suggest using a contrastive loss (CLIP loss). This loss function was originally defined to align the latent representation of text and images. So the authors think of aligning the latent representation of spectrograms of brain activity and sound.
The authors define a new brain module for spectrograms (MEL or EEG). the input is the spectrogram and a vector representing the corresponding patient (one-hot encoding of the study participant). This module consists of a spatial attention layer for spectrograms and a participant-specific 1 × 1 convolution (a sort of embedding). This is then followed by three convolution layers. the output of the model is the latent representation of the brain signal.
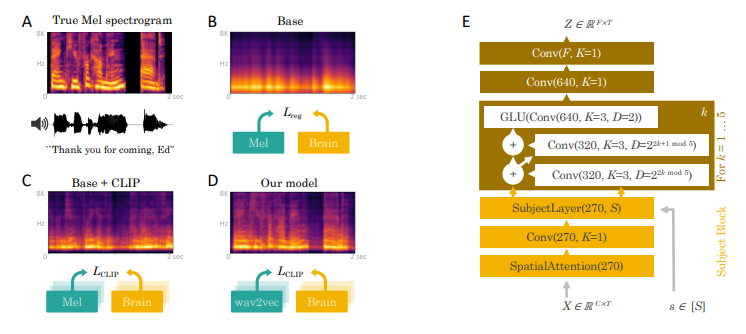
At the same time, the authors use Wav2vec to analyze sound and extract a representation of speech. Thus, the idea is to maximize the alignment between the latent representation of sound and brain activity.
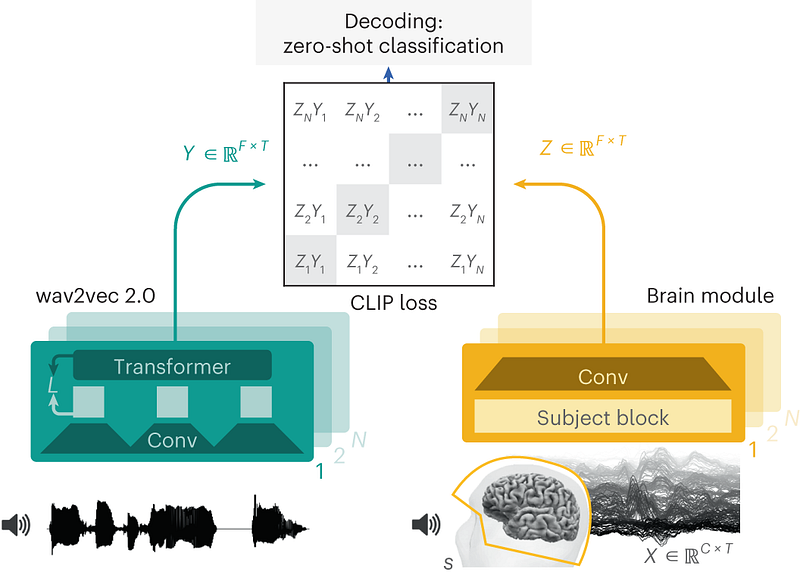
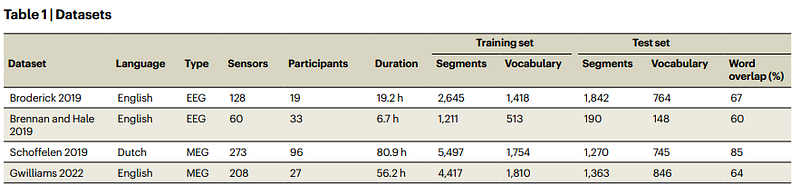
Once the model was defined, the authors curated a collection of MEG and EEG datasets by listening to short stories (175 participants in total). They then evaluated the model in identifying the corresponding audio segments for 1,500 brain recording segments (4 different datasets).
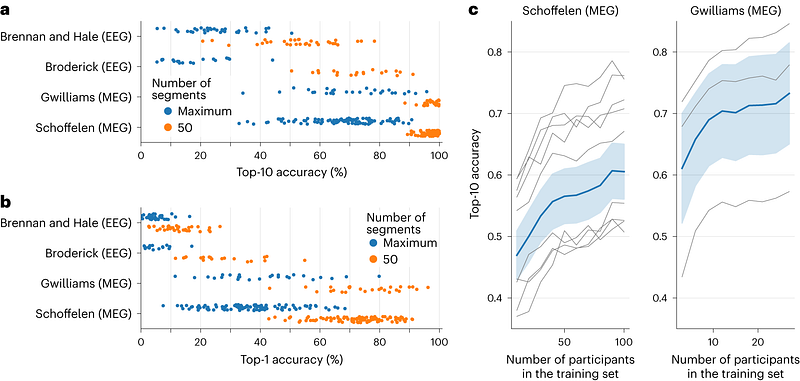
The results obtained using MEG are significantly superior to EEG (in each case superior to a random baseline). In this case, the model achieves excellent performance for the exact segment and even better performance when considering the most likely segments.
The authors also make a study to understand the model's important elements. As they show a model trained with regression objective (Base model) is superior to a random model but contrastive loss (‘+ Contrastive’) improves the results. In addition, working with the latent representation of both spectrograms and sound yields much better performance
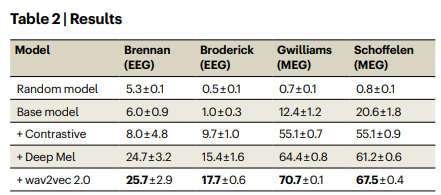
The authors also note:
- The various components of the brain module are necessary (convolution, spatial attention module, and so on).
- Generally, MEG is superior to EEG for decoding, but this is an inherent problem of the instrument (and varies depending on the EEG device that was used to record).
- Also, the greater the number of participants in the study the greater the performance of the model (the model is thus able to take into account the inter-individual variability).
What representation does the model learn?
it is difficult to be able to understand what the model is decoding from a brain signal. This is an important issue, though, because it is related to the interpretability of the model.
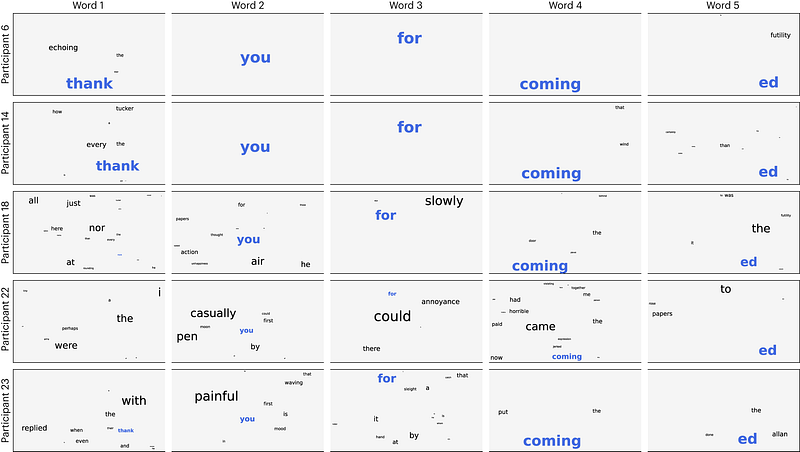
In the figure below we look at the associated probability for each participant for the phrase ‘Thank you for coming, Ed’. On the one hand, we can see for which participants the model had the best and worst results. The question is, in case the model is wrong where does the error come from? Is the error related to the phonology or to the semantics of the sentence? Answering this question allows us to improve the model.
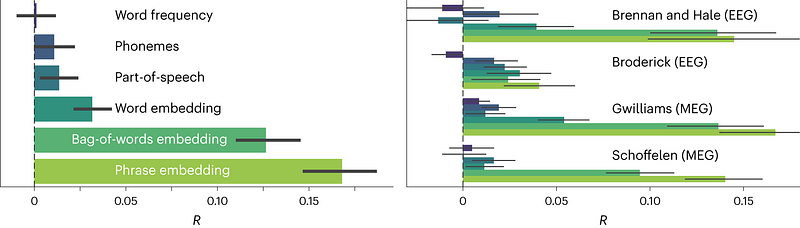
To try to answer this question, the authors analyzed predictions for a single word and for the segment in which the word is contained. The authors then trained a linear regressor to estimate the probability of the correct word for the model. The goal is to understand through this linear model what factors influence the prediction of the correct word (low-level representations such as phonemes or high-level representations such as sentences). The results show that part-of-speech, word embedding and phrase embedding are correlated with the predictions. In other words, the model is more influenced by a higher level of representation. The model relies on semantic and syntactic representations more than on the word representation itself.
The authors have also released the code:
Parting thoughts

The model succeeds in accurately identifying from brain activity segments the corresponding speech segments. This is already a remarkable achievement considering that this is noisy data.
Historically being able to analyze this data required creating complex pipelines and often dedicated to each participant. The advent of deep learning has made it possible to conduct pipelines much more nimbly. The authors here propose an end-to-end architecture that requires minimal preprocessing, making analysis much simpler.
To date, we have yet to learn how the brain represents language. This obviously impacts the result. The authors therefore exploited a model trained with large amounts of speech and aligned with a model that learns from brain signals. This is a very clever approach.
In any case, it is still premature to think that this model can enter the clinic. The tools used are far from portable and the model still needs to be refined. In fact, the model must be capable of understanding more complex sentences and have greater accuracy.
What do think? Let me know in the comments
If you have found this interesting:
You can look for my other articles, and you can also connect or reach me on LinkedIn.
Here is the link to my GitHub repository, where I am planning to collect code and many resources related to machine learning, artificial intelligence, and more.
https://github.com/SalvatoreRa/tutorial
or you may be interested in one of my recent articles: