
Behind the Working of Music Search Apps Like Shazam: Create Your Own Music Search App

Ever wondered how your favorite music searching app works?. Well, this is the correct place to find out.
Ever since I was a kid I was both a music and tech lover. I spent most of my day listening to music and reading about technology. Sometimes I listened to some new song playing around me and I liked it. I wanted to play it but not always Google search was enough to find the song. Then came the Shazam app and it was a great gift to me at the moment. After finding some of my favorite songs playing around, my tech lover side kicked in and wanted to find how it works. After some research, I found out that it uses Machine Learning for music match. After doing more research I got hold of the concepts. Which later motivated me to share the idea with other people as well.
So here I am presenting you with brief insights into the concept behind music match apps like Shazam. Here we will build a simple prototype of the music search app using Deep Learning. By the end of the article, you will have complete intuition behind the music search apps.
Some basic concepts
Short Time Fourier Transform
The Short-time Fourier transform (STFT), is a Fourier-related transform used to determine the sinusoidal frequency and phase content of local sections of a signal as it changes over time. By applying STFT we can decompose a sound wave into its frequencies. The result of this is called a spectrogram. The spectrogram can be thought as a stack of Fast Fourier Transform stack on top of each other. It is a way of visually representing a sound’s loudness or amplitude.
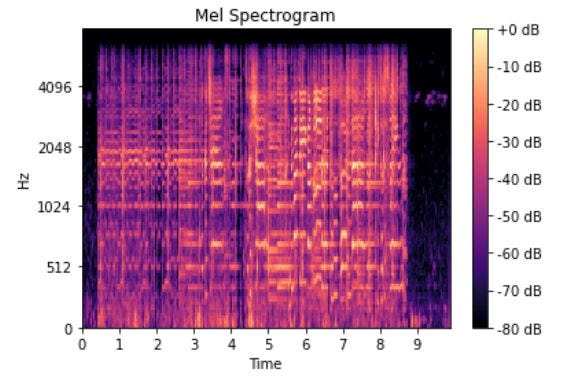
Mel Spectrogram
A mel-spectrogram is a spectrogram where the frequencies have been converted into mel-scale. The below image shows a mel-spectrogram of a sound clip.
Siamese Neural Networks
Siamese neural networks are a special kind of network where two identical copies of the same network are fed with different vectors. Instead of recognizing something they learn to find the similarity or difference between two vectors. They are mostly used for one-shot learning.

The neural networks N1 and N2 are essentially having the same architecture. When the input vectors are fed to the network then they both generate feature which is also known as embedding in certain literatures. These neural networks share the same weights and are trained in such a way that that they generate such embeddings that when we calculate the distance for those two embeddings then the distance is minimum for similar vectors and maximum for different vectors.
Overview
Having enough knowledge about the concepts which are going to be used in these article, lets now dive into the details of how this type of system work and how to build our own system.
Music search engines work on the principle of acoustic fingerprint match in a large database of songs. Whenever we record some sound then the music is processed by an algorithm which converts the music to some sort of acoustic fingerprint or feature in simple term. This feature is matched with the features of the song stored in a large song database which contains almost all popular songs in the world. The song whose feature has maximum similarity is returned as a result and everyone is happy.
In this article, we will train a Siamese network to compare recorded music with songs in our database. Since running the siamese network for all songs might be time-consuming and computationally expensive,we will create another network using this network by which searching will be highly efficient.
The article will be divided into three parts:-
- Building and training the Siamese neural network.
- Creating a neural network using weights from this siamese network which optimizes the search.
- Performing the search.
Building and training the Siamese neural network
To train any model getting appropriate data is very important. Here I am using my music collection as the dataset for the project. For the real-life project we might need to create the dataset differently but to keep things simple and understandable by most of the readers I have tried to keep the things as simple as possible.
Now let’s import all the libraries necessary for our use case.
The Siamese network we are using here will not directly work on sound but will work on the mel spectrogram of the sound so here we gonna create a function that will convert the audio fragment passed to it into the Mel spectrogram and save it as an image file.
Now let’s build the Siamese network.
First, we will build the encoder of the Siamese network in the earlier figure,the blocks N1 and N2 are called the encoders of the Siamese networks because they encode the input vectors or image into some fixed length embedding.
Here, we will build an encoder that will have 4 convolutional layers with 3x3 kernel with filters in order 32,64,64,64. A global maxpooling2D layer will follow them at the end.
Having created the encoder function now let’s build the Siamese network. Here we will create two instances of the encoder which will share the same weight and will create two embeddings. The output of these embeddings will be fed to a layer which calculates the Euclidean distance between the two embeddings. The output of the distance layer will be fed to a dense layer with sigmoid activation which calculates the similarity score.
The model takes images of sizes 150 x 150 and is trained using binary cross entropy which you will know why when we will discuss the data generator.
Let’s implement the above concepts in code.
Now let’s create the data generator and other utilities functions.
Here our Siamese neural network aims to find the similarity between the images of two audio clips. So in order to achieve it, we create a data pair as follows.
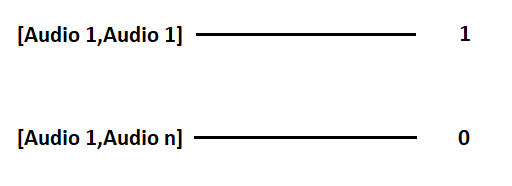
When the generator is asked to generate a batch of images then that batch contains data in the fashion as shown above. Let the batch size be n then n/2 of the batch will contain a pair of similar images and their label will be 1 while remaining n//2 will have pair of different images labeled as 0.
The function different_label_index makes sure we get different pair by generating a different index for both images.
The function load_img loads the mel spectrogram images and resizes them.
Having created all the functions of our need now let’s read the songs in our songs folder which is currently acting as our dataset and save their spectrograms.
In the below code we read each song file one by one using the librosa library and we save the spectrogram of the whole track divided in 10s each. So, while the song is searched the user needs to have at least a recording of 10s.
In my case songs are located in D:/Songs/ folder.
This generates the spectrogram of all the audio segments and stores in spectrograms folder in the same working directory.
Now let’s train the Siamese network on those mel spectrogram images using early stopping and model checkpoint with train and test split of 75% and 25% respectively.
Now we have successfully trained our siamese net and its ready for checking our songs but there is a serious issue that running a siamese network every time on our spectrograms to check the similarity is a very time consuming and computationally expensive process. Neural networks are themselves very computationally expensive. Therefore in the next section, we will use this model’s weight and build another optimal network. We will also apply a trick which will drop the time complexity from O(n²) to O(n).
Creating a neural network using weights from this siamese network which optimizes the search
Since the Siamese network will have to run every time the comparison is made that will prove to be a huge computation burden for our system. In this section, we propose the idea of distance estimation between the feature of the fragment of the song. So the neural network will have to run only once during the whole search process.
The idea is that since the Siamese network shares the same weights between the networks, we can grab those weights and can create a single network having the same architecture as that of blocks N1 and N2 in our siamese network and transfer the weights from our previous network to it. The resulting network will be able to create embeddings of the fragments of the songs which are to be stored in our database. When the user queries a song the song is converted to embeddings stored in our database and the song which is having maximum similarity or minimum distance is returned.
Let me break the idea in subsequent steps.
Let’s import all the libraries that we need. Also let’s borrow few helper functions from the previous sections.
Note:-All these codes belong to another file called test.
Now let’s load the trained Siamese model and have a look at its representation in Keras using the summary function of the model class.

Since the Siamese network shared the same weights across the block N1 and N2, then Keras uses the same layer for predicting both Vector 1 and Vector 2 which is evident from the model’s summary. Hence we can grab that layer from the Siamese model which will act as our new model for generating embedding.
Using model.layers attribute of the model class we can get the layers of the model as list. If we pay attention to the summary of the model we can observe that the layer we wanted is present as index 2. Hence we can get that layer as demonstrated below.Also we will look at the summary of this new model.
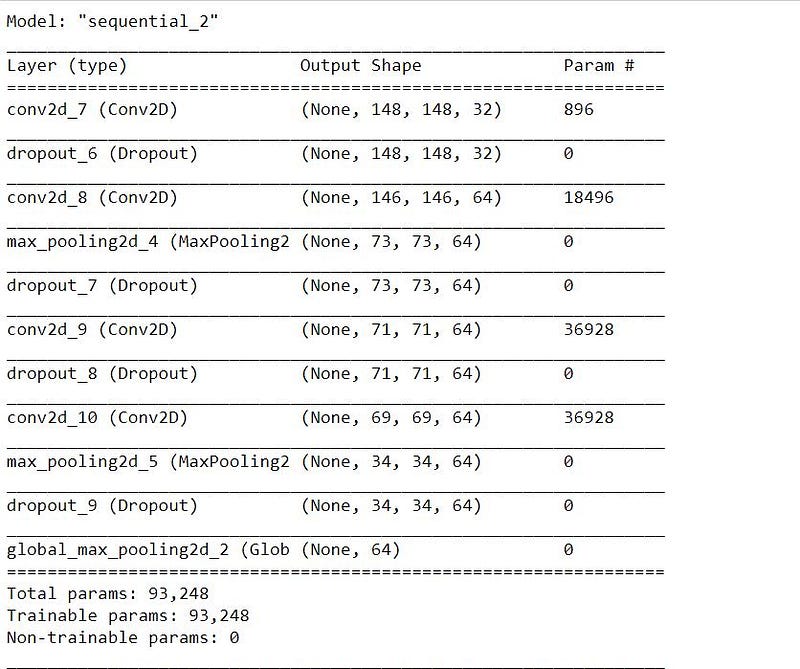
It is clear from the model’s summary that the new model has the same structure as the N1 or N2 block of the Siamese model and hence it can be used to generate embedding of the song’s fragment. Also since the model has been obtained from the trained Siamese model then it has all its weights.
Now same as the previous section where we created spectrograms for the fragments of the songs to train the model here also we will create a spectrogram and store them in another folder called Test_Spectrograms. Soon after we create the file using the create_spectrogram function, we will also open that file and will use the embedding model to generate embedding for it. Also at the same time, we add the name of the song we are processing as a key in dictionary songsspecdict. The value of the key is the array containing all the fragments embedding of that song.
Here we are interested in the dictionSary obtained above. For the sake of simplicity, I decided to store the songs embedding in the dictionary instead of the database so that most of our readers understand it.
Also after dictionary is created we save it using pickle library for later use.
Our dictionary appears like this:-
{‘song1’:[frag1_embedding,frag2_embedding,….fragN_embedding],’song2’:[frag1_embedding,frag2_embedding,….fragN_embedding],……}.
Now let’s load the dictionary for searching.
Now we are all set for performing the search.
Performing the search
Here we will load the first 10 sec of the song the best day by Taylor Swift and we will create a spectrogram of it. We will then use our embedding model to generate embedding for it. This embedding will be compared with those stored in our dictionary and the one whose distance is minimum then its key will be returned as the title of the song.
My test_songs folder contained the following songs:
13 Breathe (feat. Colbie Caillat).m4a
14 Tell Me Why.m4a
15 You’re Not Sorry.m4a
16 The Way I Loved You.m4a
18 The Best Day.m4a
Taylor Swift — Fearless — Mp3indir.ML.mp3.
The output was:-

Improving the system
Here as you can observe that we used the part of the original recorded track for searching but in the real world the recording may involve various noises in the background like vehicle horns, people talking, etc. Also, the first 10 sec of recording may or may not include the full content of which was supposed to be present in instead say we recorded from 2 sec after the song was played so this track alignment may not be present in a real-world case. Since I wanted to explain the concept in the most simple way so I created a very simple dataset since creating a full-fledged dataset alone is a very time-consuming task. I just created a dataset that was sufficient for explaining the concept.
- A better dataset could be used which contains the recordings of the songs in various conditions.
- Data augmentation could be done.
- After obtaining a suitable dataset the model itself could be fine-tuned by adding more layers keeping the bias-variance tradeoff.
References and further reading
Congrats you have just learned how these music search systems work and you are in place to build your own. If you have some doubts regarding the above concepts feel free to leave down in the comment section.
Link to jupyter notebooks:-





