
Behind Gen AI project: A Comprehensive LLM Technologies Costs Analysis
For Business decision-makers, Enterprise Architects and Developers
My greatest appreciation goes out to Alexis Barta, Christophe Locoge, and Thomas Cartoux. Their feedback, unique ideas, and thoughtful dialogue were instrumental in shaping our exploration of this topic.
Introduction
In today’s rapidly evolving technological landscape, Generative AI Models like LLM implementations have become a cornerstone for business decision-makers, architects, and software developers. However, understanding the costs associated with different LLM models and embedding modes is crucial for making informed decisions. This article will provide a detailed cost analysis covering project setup, project run, and maintenance, along with a real-world business case study for practical insights.
Before we start! 🦸🏻♀️
If you like this topic and you want to support me:
- Follow me on my LinkedIn and like this link for this article and other information about data 🔭
- Follow me on Medium and subscribe to get my latest article🫶
- Clap my article 50 times, that will really really help me out.👏
Global Vision of your Generative AI Technical Stack
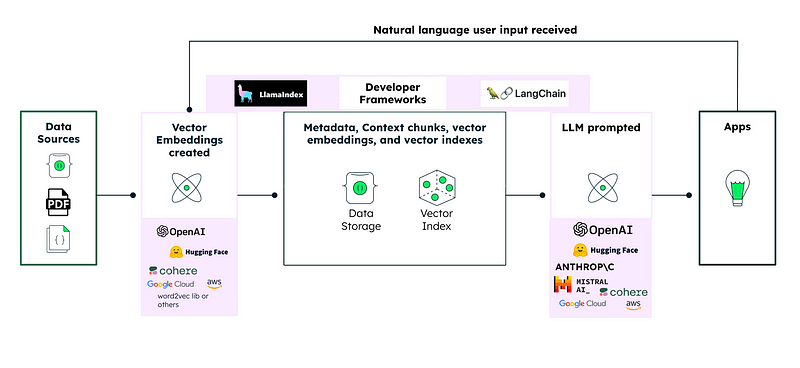
Before we delve into the costs, it’s vital to comprehend the structure of your Generative AI application; specifically, your technical stack. For illustrative purposes, let’s consider a well-represented example: an application featuring a chatbot powered by an LLM, used to enhance retrieval generation.
In such an architecture, your first step involves preparing a vector store containing your proprietary knowledge. This information maybe in PDFs, documents, or even housed in a database — hence we consider it as your primary data source. To prepare this vector store, you need to generate embeddings. You have a multitude of options: especially selecting between the array of embedding models provided by different organizations, which generally can be categorized into open-source models or API-based embedding models. We’ll dive into the cost elements of API-based embedding models in a following section.
Once your knowledge base is prepared, your users can start posing questions to the LLM. Each question received by the natural language model necessitates a transformation into embeddings. We’ll also illustrate how to optimize cost during this transformation in a subsequent segment.
The question, once transformed into an embedding, triggers the search for similar documents from your pre-existing vectorized knowledge store. The result — a set of documents, is then used to prepare a contextualized prompt sent to the LLM for obtaining the answer. Again, you primarily have two options for LLM models: API-based LLM models and self-hosted models. We’ll dissect the cost associated with your chosen LLM model.
In this article, we’ll focus particularly on analyzing the costs of embedding models and LLM models. Then, armed with a business case, we’ll traverse the cost analysis journey step-by-step.
Choosing an Embedding Model: Open-source versus API-based
Selecting an appropriate embedding model is a critical step in setting up your Generative AI application. Essentially, there are two options: open-source models and API-based models.
Open-source embedding models
Open-source models, as the name suggests, are publicly available models that you can use free of charge. They rely on a community of developers for updates and improvements. Their free-of-cost nature and the flexibility they offer make them a popular choice. However, managing and maintaining these models might require in-house expertise.
Here are some of them:
- Word2Vec: Developed by Google, Word2Vec represents words as dense vectors and captures semantic relationships between words.
- GloVe (Global Vectors for Word Representation): GloVe is an unsupervised learning algorithm that learns word embeddings by analyzing global text statistics.
- FastText: Developed by Facebook, FastText is an extension of Word2Vec that also considers subword information, making it effective for handling out-of-vocabulary words.
- BERT (Bidirectional Encoder Representations from Transformers): BERT is a transformer-based model designed for pre-training on large corpora and is known for its bidirectional context understanding.
API-based embedding models
On the other hand, API-based models are commercial products that come at a cost. They are managed and updated by the companies that created them. You’re leveraging their expertise in the field, and this can often mean access to advanced, optimized models. The trade-off here is the cost associated with their use.
Before we delve into the costs associated with each embedding model, let’s get an overview of some of the options available:
| Model | Provider | Model Name
|------------------------------|----------|--------------------------------
| OpenAI Text Embedding | OpenAI | text-embedding-ada-002
| AWS Bedrock Embedding Model | AWS | Titan Embeddings
| Cohere Embedding Model | Cohere | Not specified
| GCP Vertex Embedding Model | GCP | textembedding-gecko@001
| Azure OpenAI Embedding Model | Azure | text-embedding-ada-002| Model | Cost per 1K Tokens |
|------------------------------|---------------------------------|
| OpenAI Text Embedding | $0.0001 |
| AWS Bedrock Embedding Model | $0.0001 |
| Cohere Embedding Model | $0.0001 |
| GCP Vertex Embedding Model | $0.0002 |
| Azure OpenAI Embedding Model | $0.0001 |
Above information was collected and checked on 26 November 2023
From the table above, we can see that most providers offer their models at a cost of $0.0001 per 1k tokens, but Google’s GCP Vertex API charges slightly more — $0.0002 per 1k tokens.
Analyzing Large Language Models Cost: Self-Hosted vs. API-Based Models
Deploying a Large Language Model (LLM) is a critical part of your AI application, with two primary options: a self-hosted one or an API-based model. Each model offers unique benefits and carries different cost implications that need to be considered.
Self-Hosted LLM
A self-hosted LLM is run on your infrastructure — you are entirely in control. The significant part of the costs associated with a self-hosted LLM is related to the necessary hardware to seamlessly run the model. A popular choice is using NVIDIA’s graphics processing units (GPUs) like the NVIDIA T4, A10G, A100, V100 or V100S, known for their performance and optimization for machine learning tasks.
The cost for a self-hosted model includes the initial price of the hardware and its installation, scaling, maintenance, and potential replacement costs. Furthermore, energy consumption and cooling equipment expenses add to the ongoing operating costs. Keep in mind, a self-hosted model may require technical expertise for integration and maintenance, adding further to the cost.
Businesses considering self-hosted options for deploying Large Language Models (LLMs) must consider infrastructure costs. A critical part of this cost is the GPU pricing. Below is a comparison of GPU pricing across three major providers: AWS, Microsoft Azure, and Google Cloud:
| Provider | GPU | GPU Options | GPU Memory (GB) | GPU Cores | vCPU* | Memory (GB)* | Hourly Rate | Monthly Cost |
|----------------|-------------|-------------|-----------------|------------|-------|--------------|-------------|--------------|
| AWS EC2 | V100 32 GB | 8x | 32 | 640 | 12 | 96 | $3.06 | $2,203 |
| Microsoft Azure| V100 32 GB | 8x | 32 | 640 | 5 | 84 | $2.75 | $2,010 |
| Google Cloud | V100 16 GB | 1, 2, 4, 8x | 16 | 640 | 8 | 30 | $2.88 | $1,471 |Above information was collected and checked on 26 November 2023
Above table gives us an example of using Nvidia V100 GPU regarding the cost of infrastructure when considering self-hosting a Large Language Model (LLM). Of course you have many other GPU options with different other cloud provider (OVH, scaleway etc.).
- Computational Resources: The use of V100 GPUs in each case ensures high-end computing capabilities necessary for running LLMs. However, they come with varying GPU memory, GPU cores, vCPU, and overall memory across providers, affecting the performance.
- Cost Differences among Providers: AWS EC2 has the highest hourly rate and monthly cost but also provides the highest vCPU and more overall memory compared to Azure and Google Cloud. Azure offering has a slightly lower hourly rate but a comparable monthly cost. Google Cloud provides lower GPU memory, lower overall memory but also has the lowest monthly cost, which can be more cost-effective based on your memory requirements.
- Flexible GPU options: Google Cloud proposes a more flexible structure for GPU Options, allowing 1, 2, 4, or 8 GPUs to be used simultaneously. This flexibility may be advantageous depending on your specific GPU requirements.
Other costs to consider when self-hosting LLMs include:
- Hardware Maintenance and Upgrade Costs: Servers and other hardware components may need maintenance or replacements over time. You would also need to consider future upgrade costs to accommodate more advanced models or scalability needs.
- Software, Licensing, and Support Costs: This includes the cost of operating systems, database management systems, potential third-party software, and the cost of tech support.
- Operational Expenditure: Things like electricity costs, cooling costs, and physical space for server farms can add to the total cost.
- Network and Bandwidth Costs: These can be significant especially for services that transfer large amounts of data regularly.
- People and Skills Requirements: Self-hosting usually requires more IT resource, and people with certain knowledge and skills to manage and maintain the infrastructure.
Remember, self-hosting an LLM could provide better control and potentially save costs in the long term, but it demands a larger initial investment and ongoing resource commitment. This is a trade-off to keep in mind when comparing self-hosting with using an API-based LLM service.
API-Based LLM
With API-based LLMs, the model is hosted by a service provider. This often eliminates the need for heavy upfront costs for hardware acquisition and maintenance. Instead, you’ll typically be charged based on usage — each request to the LLM via the API carries its cost.
While the API usage cost depends on the provider, handling large volumes of requests can significantly add up the costs. An additional consideration is the network costs to send requests and receive responses, which could also impact the overall cost of using an API-based LLM.
| Provider | Model | Context | Input/1k Tokens | Output/1k Tokens |
|----------------|-------------------------|---------|----------------:|----------------:|
| OpenAI / Azure | GPT-3.5 Turbo | 16K | $0.001 | $0.002 |
| OpenAI / Azure | GPT-3.5 Turbo Instruct | 4K | $0.0015 | $0.002 |
| OpenAI | GPT-4 Turbo | 128K | $0.01 | $0.03 |
| OpenAI / Azure | GPT-4 | 8K | $0.03 | $0.06 |
| OpenAI / Azure | GPT-4 | 32K | $0.06 | $0.12 |
| Anthropic | Claude Instant | 100K | $0.00163 | $0.00551 |
| Anthropic | Claude 2 | 100K | $0.008 | $0.024 |
| Google | PaLM 2 | 8K | $0.0005 | $0.0005 |
| Cohere | Command | 4K | $0.001 | $0.002 |Above information was collected and checked on 27 November 2023
Based on the above table, we can derive a few insights about pricing of API based LLM (Large Language Models) across different providers:
- Variability in Cost based on Capacity and Complexity: The cost per 1K tokens tends to increase with the context length and the model’s complexity. For instance, comparing GPT-3.5 Turbo and GPT-4 Turbo from OpenAI, we can observe that the complex GPT-4 Turbo model costs comparatively higher.
- Provider-wise Cost Differences: Different providers offer different pricing structures. For instance, comparing Anthropic’s ‘Claude Instant’ and ‘Claude 2’ shows distinct pricing, presumably reflecting the difference in the models’ capabilities.
- Trade-off between Cost and Performance: The choice of model depends on the trade-off between cost and performance requirements. More complex models might offer better performance but at a higher cost. For example, Google’s ‘PaLM 2’ model has the lowest cost but also the lowest context length.
Above information provides a solid baseline for decision-making when choosing a provider and a model, and the specifics of your application and budget requirements will play a crucial role in this decision. Always consult the latest pricing on each provider’s official website for the most accurate information.
Business Case Study
To put theory into practice, let’s examine a real-world case study comparing two different LLM models and their associated costs.
Consider an e-commerce business managing a catalog of 10 million products. the company needs to generate embeddings for 10 million product descriptions, consisting of 500 tokens per product, and then process client requests through a language model comprising ~100 input tokens and ~1000 output tokens. I will recalculate costs for these three scenarios.
For our e-commerce business scenario, we now consider a period of six months, during which they receive 100,000 client queries per month. Our three case scenarios now adapt as follows:
In Case 1, we’re using ‘GPT-3.5 Turbo’ with OpenAI’s Text Embedding:
- The one-time cost for generating the embeddings for the entire product catalog remains $500.
- The cost for processing LLM requests is estimated to be $0.0011 per request. With 100,000 customer queries per month, the processing cost comes to $110 monthly. Over six months, this totals $660.
- By summing the embedding generation with the six-month processing costs, the total cost for this case comes out to be $1160.
For Case 2, which involves ‘Claude 2’ and GCP’s Vertex Embedding Model:
- The one-time cost for generating the embeddings for all products is $1,000.
- The cost for handling LLM requests was estimated as $0.0088 per request.
- For 100,000 customer queries per month, this totals $880 monthly.
- Over the course of six months, this equates to $5280.
- By combining the one-time embedding generation cost and the six-month processing cost, the Case 2 cost estimate comes to $6280.
Lastly, in Case 3, where we use a hosted model on an AWS v100 Server: The monthly server cost is approximately $2,203, i.e., around $13,218 for six months, not factoring any kind of discounts or the number of requests the server can handle concurrently.
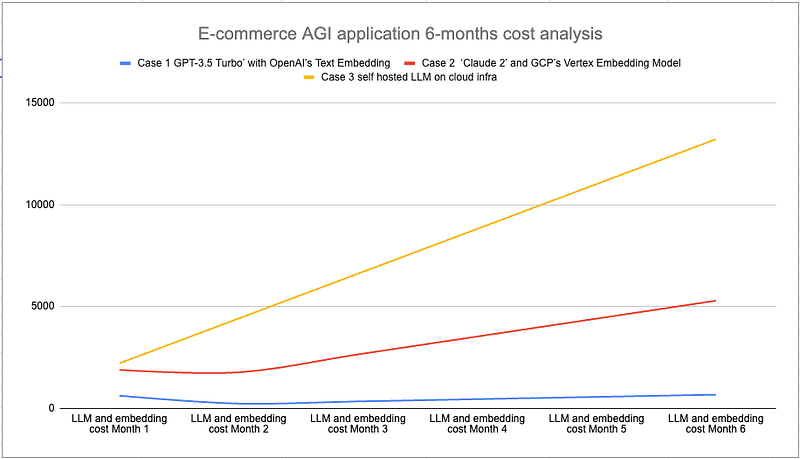
In case that the client queries continues growing to 1 millions queries per month, it is important to note that self-hosted LLM models may incur less expense then API based LLM models such as Claude AI.
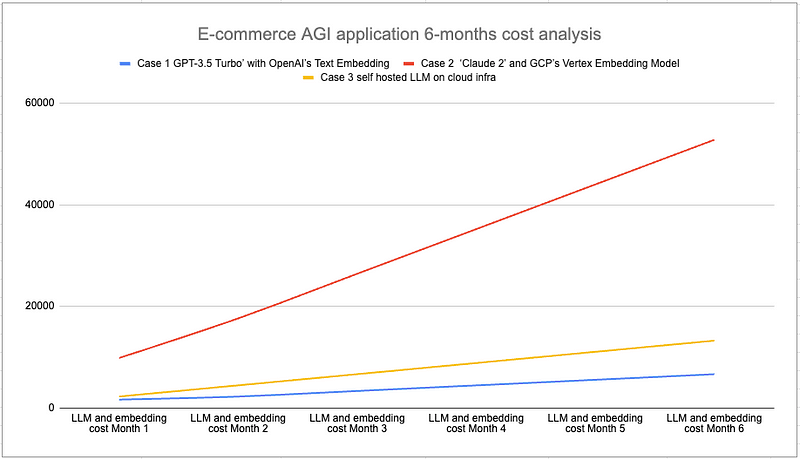
It’s important to note again that this fiscal estimation is simplified and does not consider other factors like model speed, reliability, infrastructure, and operating costs. Nonetheless, it gives a broad understanding of how costs might stack up under diverse scenarios for a substantial e-commerce business over an extended period.
Optimizing the cost of using Large Language Models (LLMs):
- Reuse Answers from Database: Store your LLM queries and answers in a database. Before sending a new request to the LLM model, check your database to see if any similar questions have already been asked and answered. This approach can substantially reduce the number of queries processed by the LLM, thus cutting costs significantly.
- Efficient Use of Tokens: In certain models like the ones from OpenAI, the cost depends significantly on the number of tokens processed. To minimize cost, it might be beneficial to make the queries as concise as possible, removing unnecessary or redundant information prior to processing.
- Choose the Right Model: Higher-capacity models might lead to better results but at a higher cost. Sometimes, a lower-cost model might achieve comparable performance for specific tasks. Therefore, it’s worth testing different models to achieve a balance between cost and performance.
- Monitor and Adjust: Regular assessment of your LLM’s performance can help identify areas for improvement. You might find ways to modify your queries, batch size, utilization rate or the number of requests in a manner that could significantly lower costs.
Conclusion
In conclusion, our comparative analysis of three distinctive approaches for managing product recommendations using large language models provided key insights into their cost structures, albeit with a few simplifications.
We find that the OpenAI ‘GPT-3.5 Turbo’ coupled with OpenAI’s Text Embedding presents the most economical solution for an e-commerce business aiming to process a substantial number of client queries per month. These cost savings potentially make this approach highly attractive for businesses dealing with extensive catalogs and high volumes of customer queries, provided the quality of results meets their business requirements.
Finally, while the self-hosted LLM model on GPU empowered server demonstrates potential for offering competitive results in certain scenarios, its usefulness for our current evaluation remains uncertain due to various unmeasured factors such as request handling capacity, model optimization, and variable pricing structures.
Given these points, cost-benefit analyses tailored to specific operational scales, client query volumes, and the quality of results is paramount in selecting an approach that suits specific business needs best. In all cases, understanding the scale and architecture of the solution in relation to the scale of the business, and adding to that a consideration of the overall system costs (including setup, operational costs, and maintenance), will result in a more comprehensive understanding and a safer choice.
Before you go! 🦸🏻♀️
If you liked my story and you want to support me:
- Clap my article 50 times, that will really really help me out.👏
- Follow me on Medium and subscribe to get my latest article🫶
- Follow me on my LinkedIn to get other information about data 🔭





