
Bayesian Inference: A Unified Framework for Perception, Reasoning, and Decision-making

“…the most important questions in life…are indeed, for the most part, only problems in probability. One may even say, strictly speaking, that almost all of our knowledge is only probable.”
— Pierre-Simon Laplace, Philosophical Essay on Probabilities
Over 200 years ago, French mathematician Pierre-Simon Laplace recognized that most problems we face are inherently probabilistic and that most of our knowledge is based on probabilities rather than absolute certainties. With this premise, he fully developed Bayes’ theorem, a fundamental theory of probability, without being aware that the English reverend Thomas Bayes (also a statistician and philosopher) had described the theorem sixty years ago. The theorem, therefore, was named after Bayes, although Laplace did most of the mathematical work to complete it.
In contrast to its long history, Bayes’ theorem has come into the spotlight only in recent decades, finding a prominent surge in its applications in diverse disciplines, with the growing realization that the theorem more closely aligns with our perception and cognitive processes. It manifests the dynamic adjustment of probabilities informed by both new data and pre-existing knowledge. Moreover, it explains the iterative and evolving nature of our knowledge-acquiring and decision-making.
In addition, Bayesian inference has become a powerful technique for building predictive models and making model selections, applied broadly in various fields in scientific research and data science. Using Bayesian statistics in deep learning is also a vibrant area under active study.
This article will first review the basics of Bayes’ theorem and its application in Bayesian inference and statistics. We will next explore how the Bayesian framework unifies our understanding of perception, human cognition, and decision-making. Ultimately, we will gain insights into the current state and challenges of Bayesian intelligence and the interplay between human and artificial intelligence in the near future.
Bayesian Theorem and Inference
Bayes’ theorem begins with the mathematical notion of conditional probability, the probability restricted to some particular set of circumstances (note: detailed mathematical explanations are not in the scope of this article, which can be found in many excellent stories published on Medium). In contrast to the frequentist approach to derive how probable is the data set given the null hypothesis, Bayes’ theorem derives the probability of when the hypothesis is true given the data collected, as expressed in the following formula:
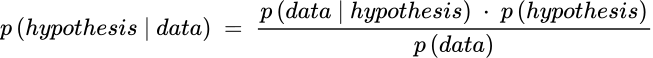
The equation can be re-written in English as:
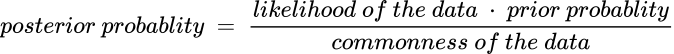
Here, we run into three concepts of Bayes’theorem:
- Posterior probability: the probability of the hypothesis given the data, p(hypothesis | data). It reflects the degree of belief in a hypothesis based on the information provided by the observed data and is the result of each Bayesian computation.
- Likelihood: the probability of the data given a hypothesis, p(data | hypothesis). Generally speaking, a likelihood expresses the extent to which a hypothesis fits the data.
- Prior probability: the prior probability of the hypothesis, p(hypothesis). It reflects the degree of belief in the hypothesis before the data is observed.
The core part of the theorem is that the prior belief influences your current belief deduced from the new data. The net result is the posterior probability calculated from both the prior probability and the likelihood of the data.
Let’s use the famous cancer diagnosis example to illustrate how it works. The original problem is like this: We know the prevalence of breast cancer in the population of women is 1%. Suppose a mammogram test gives a true positive rate of 90% (also called sensitivity, meaning if the test is given to 100 cancer patients, 90 of them are positive) and a false positive rate of 9% for those women without cancer. The question is, what’s the probability for a woman to have cancer if she tests positive? Many people would think the woman has a 90% chance of getting cancer. The Bayes’ rule gives a different answer.
Here, the hypothesis is “having cancer”; the data is when the test result is positive. We now plug into the Bayes’ theorem as:
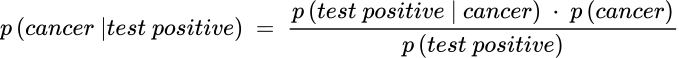
Because p(test positive) in the denominator includes both true positive and false positive, the above equation is expanded to:
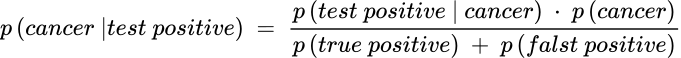
where:
p(true positive) = p (cancer) * True positive rate
p(false positive) = p (not cancer) * False positive rate
Now we plug in the numbers:
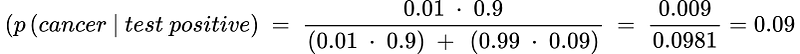
The result shows that the woman has only a 9% chance of getting cancer, even though the test has a sensitivity rate of 90%. The result has been counter-intuitive to most people, including doctors. The main culprit is the 1% p(cancer), which is the prior knowledge of cancer rate over the whole women population. The likelihood of 90% needs to be applied on top of the 1% prevalence rate. In addition, because 99% of people do not have the cancer, the 9% false positive rate is, in fact, pretty high (0.99 * 0.09), which raises the denominator relative to the numerator in the equation. Hypothetically, if the cancer rate is 10%, the result would be vastly different (53%). We can see how the prior impacts the posterior probability.
Let’s look at another example: a test for COVID-19 infection has a 100% true positive rate to detect the COVID-19 virus in those who have the infection and has a 99.9% accuracy rate of identifying that someone does not have the virus (i.e., a 0.1% chance of false positive). Assuming the prevalence of the virus at the height of the pandemic is 2%, what’s the chance of having the COVID-10 virus if a person tests positive? We use the same formula and plug in the numbers accordingly:
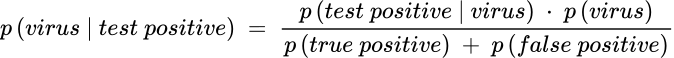
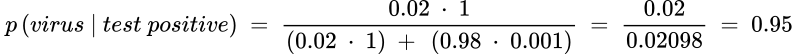
The posterior probability of 95% means the person most likely has the virus if the test is positive. Suppose after the pandemic, the prevalence becomes much lower to 0.2%. The posterior rate becomes 67%, meaning there is about a 1/3 chance a person does not have the virus even if the test result is positive.
More broadly speaking, Bayes’ theorem uses probability to measure a belief or hypothesis. The probability is a characterization of our state of knowledge and can be applied to any proposition to quantify how strongly we believe it. Furthermore, it incorporates the prior knowledge and updates it based on the observed data with the posterior probability.
For more complicated data analysis and research cases, Bayesian inference is applied in which a hypothesis is a potential parameter value for a statistical model that fits the observed data. The probability of the parameter value given the data varies continuously; therefore, it is called the posterior distribution. Simply put, the Bayesian inference becomes:
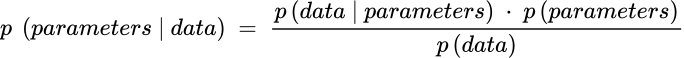
Here, p(parameters) holds the prior estimate of the parameter values while p(parameters | data) is the parameter probability given the new observed data.
In the presence of multiple competing models, Bayesian statistics plays a crucial role not only in estimating parameters but also in selecting the optimal model. As the number of parameters and the complexity of models increase in the formulation of priors and likelihoods, the calculation of the posterior distribution can pose mathematical challenges, especially when dealing with integrals of probabilities. New techniques, such as Markov chain Monte Carlo (MCMC) that involves sampling from a probability distribution, have been developed to tackle these challenges.
Last but not least, Bayesian inference does not help us to come up with the hypothesis in the first place. It is a probability theory that explains how our belief is updated or reinforced, but it does not create the belief itself. Nevertheless, it enables us to get closer to the correct belief or the optimal solution via parameter estimates and model selections, which has been proven to be a powerful approach for data-driven discoveries and predictions.
Bayesian Inference Model for Perception
Our sensory organs register physical signals from the surrounding world and convert them into electrical impulses, which, however, become a neural Morse code for our brains to interpret. These sensory signals typically allow for multiple possible interpretations. In addition, the information provided might be of low quality; for example, the interested objects might be poorly lit, vague from a distance, or moving fast. Even high-quality sensory information does not guarantee a single interpretation; for example, a two-dimensional retinal image is compatible with infinitely many three-dimensional objects. Given all these challenges, how do our brains figure out objects effortlessly in a fleet moment?
In addition, historically, there has been a long debate about how objectively we can see the world and how much of our perception comes from our own illusions. Philosopher René Descartes made his famous statement, “I think, therefore I am,” which is not totally wrong given plenty of psychological evidence suggesting that our brains can fill in from our memory to make up what we see and that we are sometimes fooled by our illusions, particularly when the external world is presented differently than we expected.
All of these started to make sense when neuroscientists and psychologists came around the Bayesian inference in the 1980s. The basic idea is to think of the sensory stimulus (e.g., the visual image) as reflecting both stable properties of the world and uncertainties introduced in the sensory process. Our prior belief in an object gives the probability based on previous experience and knowledge, and current sensory data provide us with the likelihood of the object we perceive. Our final perception, which mostly happens intuitively, is the object and its features with the maximum posterior probability.
Let’s go through a detailed example of color constancy. The estimation of color is a classic case of perceptual ambiguity. A surface reflects the light it receives with specific wavelengths and proportions depending on the material of the surface. However, the light that hits our eyes is a product of both the reflected light and the light source, and our brains need to make some inferences to differentiate them.
Suppose a banquet of flowers is on a table next to a window. Sunlight reflects off the beautiful flower petals and hits your eyes. Your eyes send the signal coding the 690-nanometre (nm) wavelength to your brain. Now, it is your brain’s task to figure out the flower’s color. There are two hypotheses:
- The flower is orange and illuminated by white light
- The flower is white and illuminated by orange light
Given the sensory information, the likelihood of both hypotheses is equally high. Your previous experience tells you that sunlight from the sky is white, and flowers are typically colorful under bright sunlight. For the 1st hypothesis, therefore, the prior probability of seeing an orange flower under white light is much higher, and so is the posterior probability than hypothesis 2. Your brain, therefore, proceeds with the 1st perception automatically.
A substantial body of experimental and theoretical work has elucidated the nature of perception as a probabilistic inference process and that the brain deduces the most probable state of the world by incorporating sensory inputs and previously learned knowledge. The scope of research encompasses various perceptual domains, including visual perception(e.g., color constancy, visual motion, contour grouping), other sensory systems, and the interplay among multiple sensory modalities. Bayes’ theorem also explains perceptual illusions as the by-products of this inference process. For example, people normally perceive motion slower than the reality without sensory updates. In a foggy environment, a driver tends to speed up as influenced more by the prior belief due to the diminished visual cues.
The Bayesian inference is particularly prominent in perceptions with temporal or spatial constraints. When I walk into a dark room, before my eyes adapt to the dim light, I rely on my prior knowledge and try to use my other senses (e.g., sound and touch) to gather information. In this process, I move slowly due to lacking confidence but still bump into a chair. Once my eyes adapt to the light, I can move swiftly around the obstacles in the room. At the same time, my internal map is updated with the chair that was knocked over. Within seconds, my brain makes the unconscious inferences based on the prior knowledge and information from multiple sensory channels, and guides my actions accordingly.
In summary, many neuroscientific studies have shown that the computational goals of human perception are inherently Bayesian, which is an optimal method for deciding what to believe under uncertainty. Remarkably, these processes happen mostly unconsciously, with the neural circuitry hosting the prior knowledge updated seamlessly for future reference.
Bayesian Reasoning
In recent decades, while Bayesian thinking has been widely adopted in every scientific field, its prominence in our human’s rational thinking has also increased significantly. One of the previous concerns against the Bayesian theorem was that the prior is subjective. Ironically, the main reason that makes Bayesian reasoning rational is the consideration of the prior.
In the ever-changing and complex world, we rarely get all the relevant information at once. Media often focuses on specific events by presenting partial information without enough context. The Bayesian theorem makes us consider prior belief and current likelihood before formulating a solid conclusion. This thought process has been proven much more rational than simply believing (or disbelieving) the facts available at hand.
Let’s look at the most famous Linda question from Daniel Kahneman in “Thinking, Fast and Slow”:
“Linda is thirty-one years old, single, outspoken, and very bright. She majored in philosophy. As a student, she was deeply concerned about issues of discrimination and social justice and also participated in antinuclear demonstrations.”
Question: which of the following answers is more plausible:
- Linda is a bank teller
- Linda is a bank teller and is active in the feminist movement.”
Psychologists Amos Tversky and Daniel Kahneman found that over 80% of the participants would pick number 2 because it fits the feminist stereotype. However, Bayesian thinking would enable us to choose the correct answer. The statement about Linda gives evidence to support that the likelihood of the second answer is more than the first. Suppose we estimate the possibility of 60% for the 2nd answer (Linda is likely a feminist bank teller) as opposed to 40% for the 1st answer (Linda is a bank teller only). In contrast, before coming to this problem, the probability of being a bank teller is much higher than for a feminist bank teller, assuming a ratio of 20 to 1. With the multiplication of the prior and likelihood, the posterior probability of Linda being a bank teller is much higher than being both a feminist and a bank teller. It leads us to choose the 1st answer as the correct one.
This example shows the process of Bayesian reasoning, where we should not draw conclusions from the current evidence presented without thinking about prior knowledge. The ignorance of prior is happening everywhere if we think as a Bayesian. A friend of mine had traveled alone for a year around the world. After viewing the YouTube videos on the crimes, she prefers to stay at home and avoid traveling alone in the future. Another friend forbids her family to travel by airplane together because she fears losing multiple family members at once. My mother panics about the consequences of certain diseases whenever one of the blood tests is slightly beyond the normal range. These examples involve the ignorance of the prior, but the reactions are only based on the exposure of specific facts.
Conversely, we should not ignore the likelihood of new evidence by over-leaning the prior. An essential concept of the theorem is that the prior is updatable. With this said, starting with a highly vague prior is okay if it is unknown. For probability distributions, the prior can begin with a significant variance, which is then narrowed down with more evidence. While ignoring priors could lead us to cognitive biases or unfounded conclusions, sticking too much to the prior by ignoring or selectively picking new supporting data could lead to confirmation bias or superstitions.
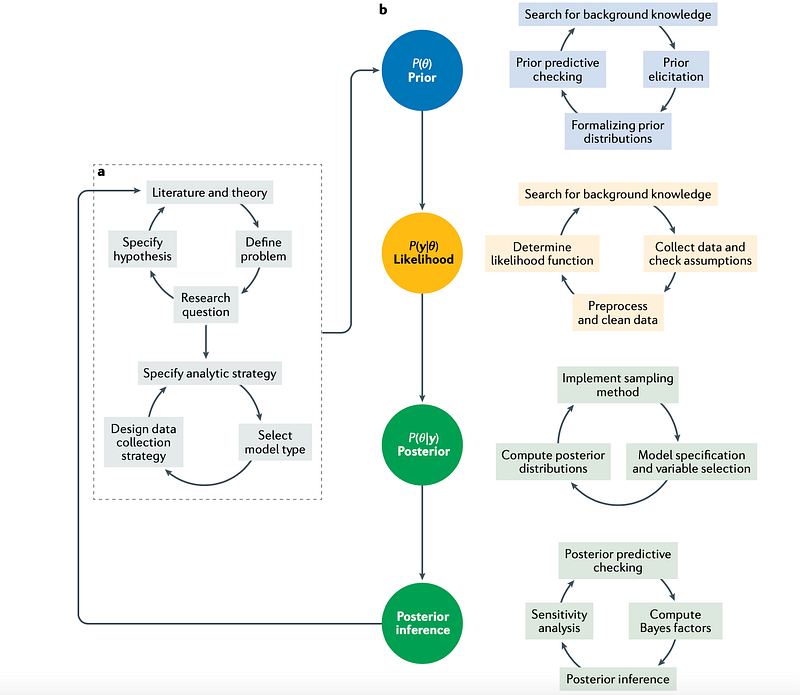
As frequentists, we usually question the sample size, sampling methods, and representativeness of the sample data; Bayesians also want to know the prior conclusions or estimates before the data is collected and how likely the current hypothesis aligns with the previous one. An excellent primer on Bayesian statistics and Modeling published in the magazine Nature Reviews Methods Primers depicts the standard Bayesian workflow (see picture below) for scientific research. Each cycle starts with the search for background knowledge and formalizing priors, ending with updating the prior for future cycles. Although the paper addresses the scientific community, the principles and concepts apply to all Beyasian practitioners.
Bayesian Posterior Probability for Decision-making
As we reviewed in the last article on decision-making, the outcome of a successful decision is an optimal action yielding the maximum rewards or minimum losses. The posterior probability of a perception or belief does not render the complete picture for making a final decision. The latter requires the assessment of the options that reflect both the predictions and the expected consequences of actions. Given this, a utility function is needed to quantify the potential consequence of each action by plugging in the Bayesian posterior probabilities.
To discover how human brains make decisions, scientists have also adopted the Bayesian inference applied to perception and other disciplines. The only difference is that the data observed is the final action selected, and the hypothesis requires the consideration of a plausible utility function (or a loss function). Since nature is a decision-maker that pushes organisms to adopt the most effective solutions available, it makes sense that evolution should favor Bayesian solutions. Remarkably, the study by Geisler and Diehl supports this hypothesis, using the standard Bayesian approach with a utility function appropriate for natural selection.
A fundamental part of decision-making is tackling the future of uncertainties. The posterior probability from Bayesian inference reflects the uncertainty and, therefore, the confidence level of a hypothesis. As discussed above, this uncertainty happens in our brains unconsciously when we perceive our environment. In contrast, conventional artificial neural networks (ANNs) lack a built-in measure of confidence. Typically trained with a large dataset without prior knowledge, these models select a set of parameters based on the best fit to the data. Consequently, when making predictions, the model cannot give a level of confidence associated with its predictions.
Considering the above, it is ideal to marry Bayesian inference with deep learning. It entails assigning multiple values to each connection weight in the neural network with the probabilities estimated through Bayesian inference. In addition, incorporating prior knowledge can enhance the overall learning efficiency, reducing the dependence on extensive training data from the ground up. However, the high dimensionality of parameters and the computationally demanding nature of posterior distribution calculations have become the main obstacles to implementing Bayesian inference in deep neural networks.
While Bayesian inference has proven to be a powerful framework for explaining human perceptions and decision-making, an interesting question arises concerning how biological neurons and neural networks encode posterior probabilities. One of the distinctions between human intelligence and AI lies in energy efficiency, with human brains achieving equivalent or superior intelligence levels using significantly less power. Bayesian inference signifies one area illustrating this substantial difference.
Conclusion
Bayes’ theorem has been widely adopted across disciplines, becoming the rational framework for human reasoning. Its power comes from its illustration of updating previous knowledge, its clarity on the extent of how the data collected supports the hypothesis, its probabilistic base for uncertainty, and its consistency with the human cognition process.
Over the recent decades, Bayesian practitioners have built a wealth of knowledge, techniques, and tools to design and implement models to solve particular problems. While there has been intense interest in applying Bayesian statistics to deep learning, the main obstacle comes from the computational challenges of tackling posterior probability distributions and complex models with increasing dimensionalities. It is an area where mutual inspirations from human and artificial intelligence could be fruitful. While there will be continuous advances in algorithms and techniques, we look forward to further developments of Bayesian intelligence across disciplines to understand and enhance human decision-making.





