
Battle of the Prompts: Unveiling the True Capabilities of Open Source Language Models
Putting LLMs to the Test: Analyzing Performance of Orca-3b, Llama2–7b and Platypus-13b Across Varied Prompts

Large language models have revolutionized the field of natural language processing by demonstrating impressive capabilities in various language-related tasks. These models, such as GPTs, Llama2, T5 and others are trained on massive amounts of text data and can generate coherent and contextually relevant responses.
Even if the context size of the model is increasing every day, there is a limit to the computation power we can access and there is an increase in the generation time. Prompt engineering is certainly one of the strategies to overcame the problem!
However, evaluating and comparing the performance of these models with different prompts is crucial to understand their strengths and limitations.
In this article, we aim to explore the effectiveness of different prompts. We will test three prominent open source large language models, namely Orca, Llama2 and Platypus2: in progression we will use also different sizes (Billion of parameters) to verify if indeed Larger means also better…
The purpose is to see 6 type of prompts in action and assess the open Source LLM performance in generating accurate and insightful responses.
NOTE: if you think some good LLMs are missing, drop me a message
to the article and I will work on it!Methodology
I am not a researcher, so I will use a really basic evaluation metric: I will consider:
- Fluency
- accuracy
- Relevance (prompt understanding)
- User Satisfaction
- Inference time
- Context understanding/generation
Every criteria will get a score from 0 to 3: 0 is Very Bad, 1 is Bad, 2 Medium and 3 is Good. So the maximum score for each question is 18 and will be evaluated for every single LLM on the same prompt type.
The Art of Prompting
Prompting is like an art form, you know? It’s all about getting the context, understanding what the AI can do, and knowing what you want out of the conversation.
You need to come up with a question or statement that guides the AI down the path you want it to take. That way, the AI can give you a response that’s more personalized and spot-on.
Basically, prompting is like turning the key in the right direction to unlock all the amazing stuff that AI can do. It’s about taking a simple question and turning it into a cool exploration, turning a vague idea into a solid plan, or even turning a problem into a legit solution. It’s about making AI not just a tool, but a true partner in our search for knowledge, creativity, and problem-solving.
For us this means that Prompts are the key to unlocking the full potential of Orca, Llama and Platypus: we are going to do it with 6 different types of prompts (informational, creative, problem-solving, instructional, reflective, and predictive) serving different purposes.

Prompt Types
By utilizing these different prompt types, we can leverage the AI’s capabilities to suit our specific needs, whether it’s seeking information, fostering creativity, problem-solving, learning, philosophical exploration, or predictive analysis. It enhances the versatility and usefulness of AI as a tool in various aspects of our lives. Here’s an explanation of the six types of AI prompt categories:
- Informational: In this category, the prompts are designed to extract specific information or facts from the AI. It could involve asking questions like “What is the capital of France?” or “When was the Eiffel Tower built?” The goal is to obtain accurate and concise information from the AI.
- Creative: Creative prompts aim to inspire the AI to generate imaginative and artistic content. These prompts encourage the AI to create stories, poems, song lyrics, or even visual art. For example, you could ask the AI to “Write a short story about a magical adventure in a hidden forest.”
- Problem-Solving: Problem-solving prompts focus on utilizing the AI’s capabilities to find solutions to specific problems or challenges. These prompts can involve asking for recommendations, strategies, or advice. For instance, you might ask the AI, “How can I improve my time management skills?” or “What are some effective ways to reduce plastic waste?”
- Instructional: Instructional prompts involve requesting step-by-step instructions or guidance from the AI. These prompts are useful for learning new skills or completing tasks. For example, you could ask the AI, “Can you provide a recipe for homemade pizza dough?” or “How do I change the oil in my car?”
- Reflective: Reflective prompts encourage the AI to provide thoughtful insights or engage in philosophical discussions. These prompts involve asking open-ended questions that prompt the AI to reflect on abstract concepts or offer personal opinions. You might ask the AI, “What is the meaning of life?” or “What are your thoughts on the nature of consciousness?”
- Predictive: Predictive prompts involve requesting the AI to make predictions or projections based on available data or patterns. These prompts can be used for forecasting trends, analyzing data, or making informed decisions. An example of a predictive prompt could be, “What will be the global population by the year 2050 based on current growth rates?”
By understanding these different prompt categories, we can tailor our questions and statements to direct the AI’s responses effectively and get the desired outcomes. Here the questions I picked up:
- informational: “How was Anne Frank’s diary discovered?”
- creative: “Write dialogue between a detective and a suspect”
- problem solving: “Suggest a daily schedule for a busy professional”
- instructional: “Extract the main points of this text: {long text here}”
- reflective: “How can I improve my romance life?”
- predictive: “Predict the impact of artificial intelligence on human learning”
AI python setup
I made it as easier as possible. Since I have a Mac Intel, no special GPU, and 16 Gb RAM I decided to go for quantized GGML models and run the inference only on my CPU. Python version 3.10.
I downloaded from Hugging face from the TheBloke repo the following models:
- orca-mini-3b.ggmlv3.q4_1.bin
- llama-2–7b-chat.ggmlv3.q2_K.bin
- platypus2–13b.ggmlv3.q2_K.bin
NOTE about the Licences:
- Platypus is Non-Commercial Creative Commons license (CC BY-NC-4.0)
- Llama2-7b-chat A custom commercial license is available
at: https://ai.meta.com/resources/models-and-libraries/llama-downloads/
- Orca-3b: The license on this model does not constitute legal advice.
We are not responsible for the actions of third parties who use this model.
Please cosult an attorney before using this model for commercial purposes.If you have some suggestions or tests that are interesting on free for commercial use models, leave a comment in the article
The Orca-min model is the smaller one, so I gave it some slacks and used a q4 quantized version: for the bigger ones I downloaded the 2-bit quantized version.
After that I simply created a loop over the list of questions and logged the questions and results in a txt file (python is amazing for automating these kind of stuff…).
Hyper-parameters used
I decided to use the same configuration setup for all the models:
n_ctx=1024
n_batch=128
temperature = 0.7,
max_tokens=1024,
top_k=20,
top_p=0.9,
repeat_penalty=1.15So I did not want to have too long waits: the context window is set to 1024 even though we could have set it to 4096 (at least for the Llama2 model and for Platypus2)
Let’s check some of the results
LLMs in action
I wanted to give a clear picture of the outcomes and show to you all at a glance what happened. The best way for the overall is like this.

To be fair none of the models gave back the correct answer: here a RAG strategy would have worked better. I tried myself llama2–13b and it did it right. To be noted, though, that Platypus-13b was not more accurate or informative than the Orca-mini-3b. In this case bigger does not mean better…
NOTE: all the generated texts are available on my github repo

Also for the creative prompt Llama2–7b perform certainly better than the others: again the quality of Orca-3b is better than the 13b parameter model.
The Instructional prompt is a key point: here we can tell the LLM to perform a task that usually come into pipelines. In this example I did not ask to summarize, but to extract the relevant and main points of a long text (article How to write articles that people want to read | by Sunil Sandhu | JavaScript in Plain English). If by mistake you ask “Extract the main point of this text” you will get only one point!

Here the Orca-3b did a wonderful job! I mean it followed the instructions clearly and provided an unsorted list with correct information. Platypus2–13b instead gave us a summary, not even so concise…



Evaluations
A detail for each prompt scores are collected in the GitHub repo in a pdf file. Here the Overall one:
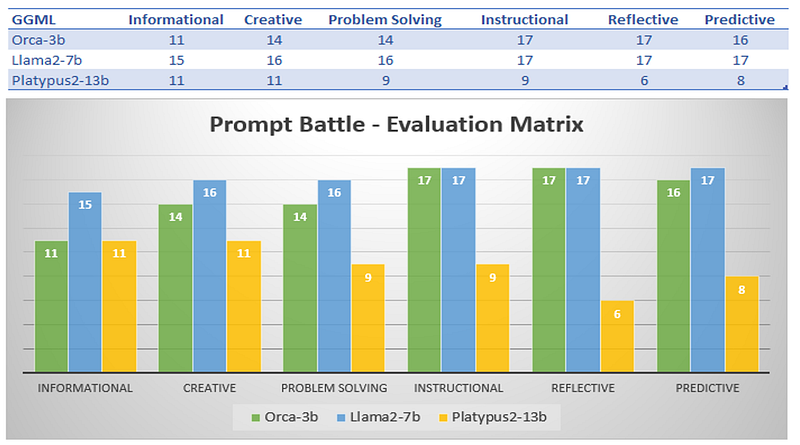
It is arguable, I know. I applied a qualitative Matrix score, not a quantitative one. This is mainly for lack of knowledge (yet to be acquired) and also due to the fact that is not an Academic Paper. I put myself in the readers shoes and react to what I see.
The takeaways are following up.
Key Takeaways
It is time to collect and see what we have learned.
First of all it was really interesting seeing the capabilities of all these LLMs: I was also surprised by some of the outcomes, but I also believe that with better prompting skill the models may have performed much better.
If are of the same opinion, leave a comment: I will be glad to learn more!
Back to the topic here is what I could see:
Informational prompts
Llama2–7b-Chat is the winner here. Anyway the information given is not fully correct, even if it not hallucinating names. (I tested with llama2–13b and it was a good job). For specific information prompts a RAG strategy is always recommended.
Creative prompts
Llama2–7b-Chat is the winner here too. Anyway the tiny Orca-3b did a good job as well. To be noted that Llama2 here includes also emotions for each character of the dialogue, coming up with a script. The inference time on CPU is 1 minute and 18 seconds 😕.
Problem Solving prompts
Llama2–7b-Chat is the winner here. Anyway the tiny Orca-3b did a good job as well with a fast 21 seconds inference time. To be noted that Llama2 here includes also further comments giving advices after every schedule point. The inference time on CPU though is 2 minute and 43 seconds. Platypus2 here did not even understood to create a schedule in a list format.
Instructional prompts
Llama2–7b-Chat and Orca-3b are both winners here! In terms of inference time Orca was faster delivering anyway a good generation and following the instructions. To be noted that Llama2 created and ordered list, Orca instead an unsorted one: this is more in line with the request. For Summarization and text extraction Orca-3b is lighter and faster.
Reflective prompts
Llama2–7b-Chat and Orca-3b are both winners here! In terms of inference time Orca was faster delivering anyway a good generation and following the instructions. Llama2–7b is 3 times slower than Orca, but the complexity of the reply is certainly appreciated. Platypus2 falls behind in all the evaluation matrix If you need to use these kind of prompts in your chatbot certainly Orca-3b is lighter and faster.
Predictive prompts
Llama2–7b-Chat is the winner but Orca-3b is almost there! In terms of inference time Orca was faster delivering anyway a good generation and following the instructions. Platypus has a Medium quality reply and not in a list format. Llama2–7b is 4 times slower than Orca, but the complexity of the reply is certainly appreciated and it supports the statements with further explanations. If you need to use these kind of prompts in your chatbot certainly Orca-3b is lighter and faster
I hope you liked the article. My curiosity won against any kind of workflow and structures. Here below the gitHub repo link.
If this story provided value and you wish to show a little support, you could:
- Sign up for a Medium membership using my link — ($5/month to read unlimited Medium stories)
- Follow me on Medium
- Read my latest articles https://medium.com/@fabio.matricardi
Meantime you can check:





