
Azure Synapse Analytics as a Cloud Lakehouse: A New Data Management Paradigm
Will enterprise data lake & enterprise data warehouse (EDW) coexist?

In the early days of data repository, a data warehouse (DW or DWH), also known as an enterprise data warehouse (EDW), is a commonly known system used for reporting and data analysis, and is considered a core component of business intelligence. Extract, transform, load (ETL) and extract, load, transform (E-LT) are the two main approaches used to build a data warehouse system. DWs are central repositories of integrated data from one or more disparate sources. They store current and historical data in one single place. It may sound remarkably similar to the definition of a data lake. In particular, data lake can store both structured and unstructured data in whatever form the data source provides. See Data Lakes compared to Data Warehouses — Two Different Approaches (AWS) for the detailed characteristics of the two.
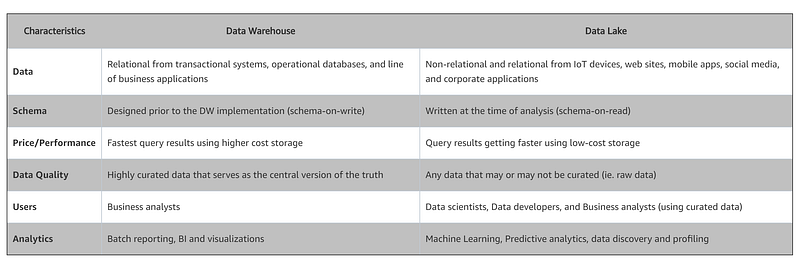
Many cloud solution providers often bundle the two offerings in their proposed big data architecture, positioning data lake as a storage layer and data warehouse as a model & serve layer.
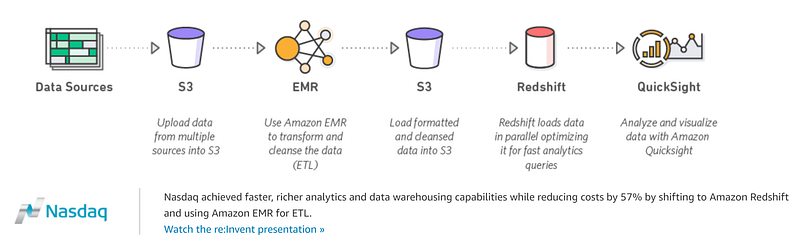
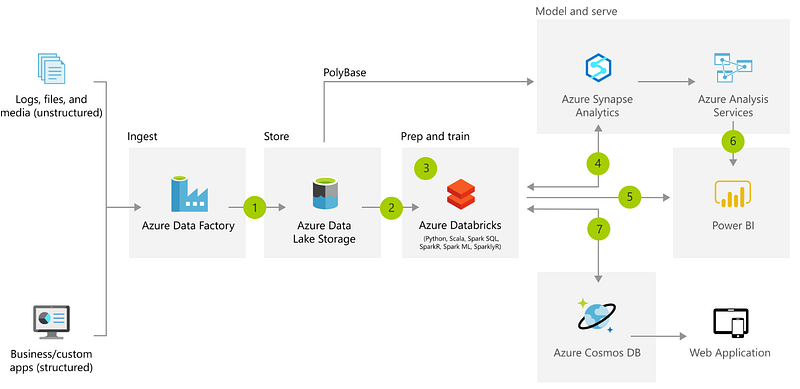
The question now becomes will Data Lake & Enterprise Data Warehouse (EDW) coexist? The answer is yes! We call this new emerging pattern as a cloud lakehouse, bringing the best of data warehouse and data lake altogether and simplifying the big data architecture. Some highlighted benefits include:
- AI + BI support.
- Support for both structured and unstructured.
- End-to-end streaming.
- Schema enforcement and governance.
- Drive greater productivity and efficiency.
- Reduce risks and costs of data warehouse and data lake consolidation and modernization.
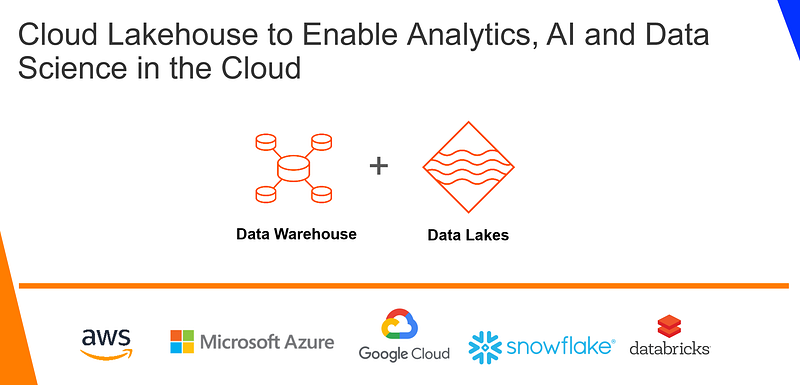
Unlike AWS Redshift or GCP BigQuery, Azure Synapse Analytics is considered an example of a cloud lakehouse. “Azure Synapse uses the concept of workspace to organize data and code or query artifacts. And the workspace can surface as a low code/no code tool for business analysts or a Jupyter-like notebook for data engineers and data scientists to work in Spark or apply machine learning models. In the demos, Microsoft showed how the same data transformation task could be developed using both paths. There will be some differences in the experience — for instance, while Synapse inherits the Azure SQL Data Warehouse capability to support high concurrency, Spark environments have typically involved lone wolf data scientists or data engineers. There’s also differences in levels of data security — practice is far more mature on the relational database side with table, column, and native row-level security, but not as mature on the data lake side. That’s an area where Cloudera differentiates with SDX, which is available as part of its platform offerings.” (A closer look at Microsoft Azure Synapse Analytics, Tony Baer (dbInsight) for Big on Data, April 14, 2020). “The Databricks Platform has the architectural features of a lakehouse”. As Microsoft is setting forth in the trend of integrated singular data platform, other managed services are likely to go in the similar pattern in the future.
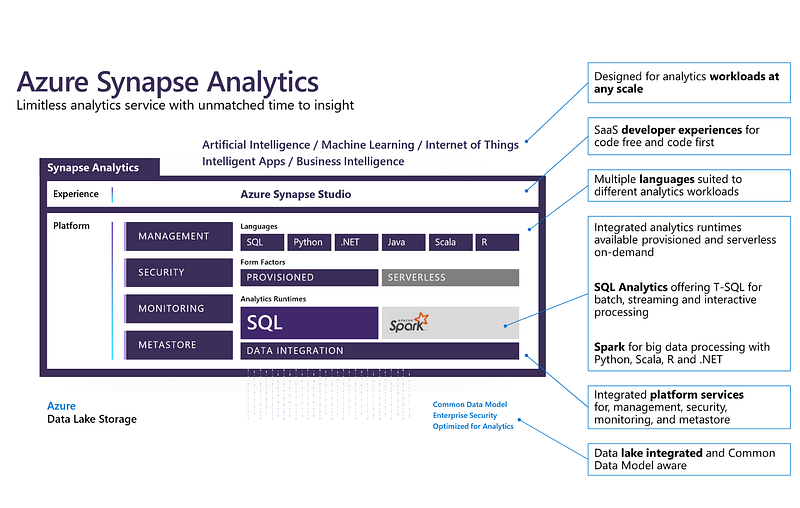

Find more details here.
References
- What is a Lakehouse?
- Intelligent Cloud Lakehouse Data Management for Cloud Analytics (Informatica)
- Data Lakes compared to Data Warehouses — two different approaches
- Azure Synapse is Azure SQL Data Warehouse evolved
Disclaimer: The following content is not officially endorsed by my employer. The views and opinions expressed in this article are those of the author’s and do not necessarily reflect the official policy or position of current or previous employer, organization, committee, other group or individual. Analysis performed within this article is based on limited dated open source information. Assumptions made within the analysis are not reflective of the position of any previous or current employer.



