
AWS Glue in 30s — A Beginner’s Guide to Simplified Data Integration and Analysis
Welcome to our beginner’s guide to AWS Glue, where we’ll demystify the world of data integration and analysis using Amazon’s powerful service. Whether you’re just starting out or looking to refresh your understanding, we’ll cover everything you need to know in simplest terms.
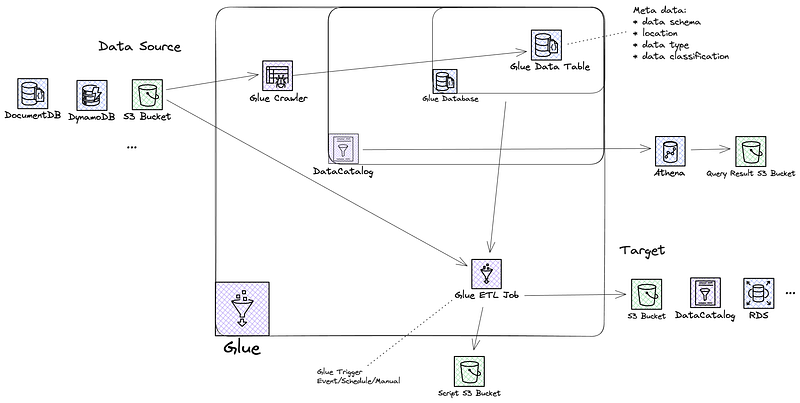
1. Data Source:
- Imagine your data source as a treasure trove of information waiting to be unlocked. This could be anything from databases, data lakes, or even streaming data.
- AWS Glue works seamlessly with various data sources, ensuring compatibility and easy access to your data.
2. Glue Crawler:
- Think of the Glue Crawler as your data detective. It automatically discovers and catalogs data from your various sources.
- By connecting to your data source, the Glue Crawler extracts metadata and creates a data catalog, making it easy to search and query your data.
3. Glue Catalog:
- The Glue Catalog acts as a centralized repository for all your data assets, including databases and tables.
- It organizes your data in a logical structure, making it accessible and manageable for analysis.
4. Glue ETL Jobs:
- ETL (Extract, Transform, Load) is the process of moving data from one place to another while transforming it along the way.
- With Glue ETL jobs, you can easily extract data from your source, apply transformations, and load it into a target destination, such as Amazon S3 or Redshift.
5. Analytics with Athena and Redshift:
- Athena allows you to query data directly from your S3 data lake using standard SQL queries. It’s perfect for ad-hoc analysis and exploration.
- Redshift, on the other hand, is a fully managed data warehouse service that allows you to run complex SQL queries at lightning speed. It’s ideal for large-scale analytics and reporting.
AWS Glue simplifies the complex process of data integration and analysis, allowing you to unlock the full potential of your data with ease. By leveraging its powerful features like data discovery, ETL, and analytics, you can gain valuable insights and drive informed decision-making for your business. So, why wait? Dive into the world of AWS Glue and take your data to new heights!





