

AWS Elastic Disaster Recovery (DR) Strategies
Building resilience against outages is crucial for any organization relying on cloud-based systems and applications. Disasters whether caused by human errors, software failures, cyber attacks or natural catastrophes can deal devastating blows leading to prolonged downtimes and massive financial losses. However, through proper disaster recovery (DR) planning, companies can minimize both recovery time and data loss to keep business functioning smoothly.
AWS provides a flexible array of managed DR services and infrastructure covering a spectrum of recovery objectives. Backup and restore capabilities act as a baseline level of protection while pilot light and warm standby environments enable faster system reconstitution. For the most critical applications demanding high availability, multi-region active-active architectures provide the greatest resilience to minimize disruption across even worst-case regional outages.
This tutorial offers best practices for implementing DR processes on AWS across the availability spectrum. We cover how to leverage native automated backups, maintain miniature pilot light environments and configure latency-based DNS routing. Following these designs allows tuning recovery time and data loss to meet application requirements while balancing infrastructure overhead costs. Additional considerations like periodic testing, encryption and offline data archiving further bolster overall disaster preparedness. With diligent planning, companies can feel reassured that critical cloud-based systems have coverage to remain operating optimally across likely failure scenarios.
By the end, you will have actionable patterns for instituting redundancy suitable to your risk tolerance and budget. Testing and iterating on DR capabilities institutes organizational learning to master resilience in the face of uncertainty. Having disaster recovery blueprints tailored to system criticality demonstrates due diligence in safeguarding against disruptions that will inevitably strike amid the cloud adoption journey.
Overview
Disaster recovery (DR) refers to the policies, procedures and infrastructure in place to enable the recovery of IT systems and data after a disruption. The goal of DR is to minimize downtime and data loss in the event of outages caused by factors such as natural disasters, cyber attacks, human errors or service disruptions. Having a robust DR strategy is crucial for any organization to protect business operations and continuity.
When designing a DR strategy, two key metrics to consider are the Recovery Time Objective (RTO) and the Recovery Point Objective (RPO). The RTO is the maximum acceptable time to restore systems after an outage or disruption occurs. The RPO indicates the maximum tolerable period of potential data loss when recovering from an incident. For example, an RTO of 4 hours and an RPO of 1 hour means the systems and data must be recovered within 4 hours, and a maximum of 1 hour of data updates may be lost in the process.
AWS provides a suite of managed DR services and infrastructure to help meet various RTO and RPO requirements. Options range from simple backups and restores, to warm standby servers, all the way to full multi-region active-active redundancy. Backups provide a baseline level of recoverability, though RTO may be longer. Warm standby and pilot light DR solutions improve RTO by maintaining partial environments in alternate regions that can be quickly scaled up. A multi-region active-active deployment offers the highest level of resiliency by running the full application in multiple regions concurrently.
The choice of DR strategy should align with the criticality of systems and acceptable risks. Testing DR capabilities regularly also gives confidence that recovery procedures work as expected. Utilizing the range of DR services and infrastructure available in AWS can help strengthen an organization’s ability to withstand and recover from disruptions with minimal impact.
Backup and Restore
Implementing regular backups and validating restore processes are fundamental elements of any disaster recovery strategy. AWS provides automated backup capabilities for several database, storage and application services.
It is a best practice to enable automatic backups across your AWS infrastructure including relational databases, object storage, file storage systems and block storage volumes. The backup frequency and retention periods should align with recovery objectives as well as regulatory compliance rules. AWS backups are stored redundantly across availability zones and allow restoring data up to the timestamp of the last backup.
In addition to native AWS backups, organizations should ideally maintain offline or cold backups stored in a different region or cloud provider. This guards against the rare scenario where an entire AWS region experiences a major failure. Encrypt backups end-to-end before transferring across networks and store encrypted copies in secure long-term archives.
Recovery testing is imperative to provide confidence in meeting recovery time objectives. Periodically initiate mock recovery drills by restoring backups into isolated test environments. Verify that the quantity and integrity of data meets expectations. Test the change management procedures in coordinating large-scale restores. Such testing uncovers gaps, reduces uncertainties and familiarizes teams with recovery workflows.
Having both backup capabilities and established restore processes lays the foundation for recovering from incidents like accidental data deletion, storage failures, ransomware attacks or infrastructure outages. However, larger disaster events may require rebuilding entire platforms which can prolong recovery timelines. Additional resilience can be attained by maintaining replicated standby environments or pursuing multi-region active deployments.
Pilot Light
The Pilot Light strategy is a method of maintaining a baseline DR environment that can be rapidly scaled up to take over production workloads. This approach provides faster recovery time compared to restoring backups from scratch or redeploying an entire infrastructure.
A Pilot Light consists of a minimal version of the production application stack running in a secondary region. It includes critical core components like servers, databases and caches to mirror the topology of production. A small replica dataset is synchronized from the main environment to the pilot servers. Compute resources can be scaled down to save costs, as the standby environment does not need to support production traffic levels.
In addition to infrastructure, the pilot should pre-stage application deployments, configs and resource templates to avoid time-consuming setup tasks. Scripts for rapidly scaling and cutting over DNS are also prepared upfront. Data synchronization establishes a viable recovery point, though some data loss is expected vs fully redundant production systems. Transaction logs may further enable point-in-time recovery.
When disaster strikes, the goal is to swiftly scale up the pilot to assume the production application footprint. Engineers launch the necessary compute resources, storage, networks based on pre-made templates. Parallel tasks deploy application code, load data and shift DNS routing to direct traffic over. The streamlined activation steps minimize delays compared to launching fresh infrastructure.
Pilot Light targets critical systems with low tolerance for downtime and data loss. The rapid recovery capabilities balance cost savings from running minimal standby resources. For supporting the highest availability across extended outages, a multi-region active deployment can be preferable.
Warm Standby
A Warm Standby strategy maintains a scaled-down version of the production environment continuously running in a secondary region. Keeping the standby infrastructure minimally warm provides faster recovery time over cold backups or pilot lights.
The warm standby comprises key production components like servers, databases, networks and storage to mirror the main environment. The capacity of the standby fleet and databases is sized to support a small subset of the production workload. Warm servers process transactions from replicated data to better validate integrity.
Using auto scaling capabilities, the warm standby can dynamically adjust to maintain just enough resources to stay synchronized with production data flows. Scheduling regular failover tests to the warm environment uncovers gaps before true disasters strike.
In a real outage scenario, the warm site is rapidly scaled up to production scale to take over customer traffic. DNS cutovers get initiated to redirect requests, while pre-staged capacity lets resources scale smoothly. Some data loss may occur since replication lags behind production, depending on RPO objectives.
The warming approach delivers low recovery time objectives while utilizing lower compute resources versus full multi-region active redundancy. The trade-off is additional replication and networking costs for keeping infrastructure minimally ready. For true high availability across regional failures, active-active deployments provide higher redundancy across sites.
Overall, warm standby delivers robust recovery point objectives for critical systems that mandate continuously running DR sites. The standby can activate faster than restoring backups cold or spawning new fleets. Warm facilities help strengthen resilience for mission-critical applications.
Multi-Region Active-Active
A multi-region active-active deployment represents the highest level of disaster recovery resilience in AWS. With this model, the full application stack runs concurrently in two or more geographic regions.
Leveraging multiple active sites provides continuous availability even when one entire region goes offline. Route 53 latency-based routing seamlessly directs incoming requests to the nearest available application site. Data replicates closely to real-time across regional database instances to minimize data loss.
The active sites scale fully to handle 100% of typical production workloads independently. Multi-region deployment and testing enables resolving any hidden single points of failure within the architecture. Storage systems like S3 or EFS maintain data durability across availability zones and regions automatically.
Cutting over production traffic away from a failed region triggers faster using active redundancy than pilot lights or warm standbys. However, running multiple full-scale environments continuously demands higher resource overhead. The trade-off for true high availability is justified for the most critical applications.
For on-premises legacy applications being migrated to the cloud, multi-region active deployment allows retiring old DR infrastructure in favor of AWS-managed replication and redundancy. Testing overall resilience through simulated regional failures provides confidence in recovery capabilities.
In summary, leveraging multiple active AWS regions removes single points of failure and provides the strongest recovery objectives for ultra-high system availability. While requiring greater upfront investment, the developer productivity and disaster resilience gains make multi-region strategies valuable for top-tier mission critical applications.
AWS CLI Commands for DR Strategies
Here are some AWS CLI commands that can be useful for disaster recovery strategies:
Backups
Create an Amazon RDS database snapshot:

List all RDS database snapshots:

Restore RDS instance from DB snapshot:

Cross-Region Replication
Enable cross-region replication for DynamoDB table:

Enable automatic EBS snapshot copy to secondary region:

Pilot Light
Pilot Light

Launch 1 instance of pilot light standby environment:

Warm Standby
Warm Standby

Scale warm standby autoscaling group from 1 instance to 3:

Route 53
Create latency-based Route 53 record set:

Configure Route 53 health checks for multi-region deployment:

Active-Active
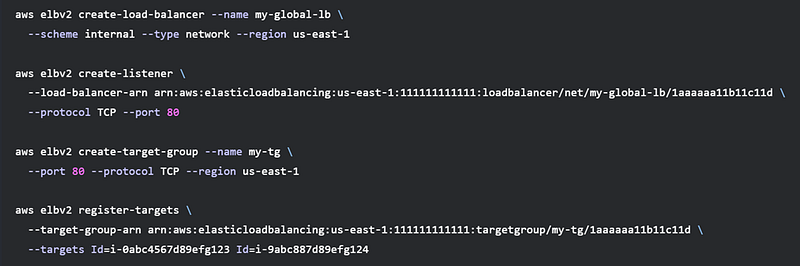
Provision a load balancer across two regions:
Conclusion
Building comprehensive disaster recovery protocols is essential for every organization embracing cloud platforms like AWS for critical systems. When outages strike from hardware failures, human errors or natural disasters, having solid resiliency principles in place will minimize downtime and data loss.
We covered a spectrum of AWS capabilities like automated backup, pilot lights, warm standby and multi-region deployment to match recovery objectives with application needs. Testing and refining these DR facilities periodically helps develop organizational readiness to handle real scenarios smoothly. Keeping encrypted offsite data archives adds an extra layer of protection against regional-level disruptions.
While no DR strategy can prevent all disasters given uncertainty, applying the right blend of resilience patterns suits most risk profiles. Even greater than any specific tactic, developing the institutional knowledge on response coordination equips teams to adapt more effectively. Treat disaster recovery planning as an ongoing journey to harden cloud architectures in the face of random acts.
By leveraging native AWS availability tools complemented with custom redundancies, enterprises can confidently migrate mission-critical workloads. Strike the right balance between recovery objectives and cost overhead specific to organizational needs. With cloud-based resilience capabilities maturing rapidly, future innovation promises even stronger protections through AI-based pattern recognition and automated healing. Maintain an openness to emerging techniques while instituting foundational DR lifecycles proven through testing over time.
Staying the course on business continuity planning builds lasting value ensuring AWS systems withstand inevitable turbulence ahead. Through sustained willingness to learn, plan and test at larger scales, modern cloud architectures can deliver both productivity and resilience simultaneously.




