
Are Singaporeans negative Nancies? A sentiment analysis of social media comments using BERT
Complaining is an undisputed national past time for many Singaporeans. But exactly how negative are we? And do we loathe all topic matters equally?
Wow, I get that this was maybe written from the perspective of the World Toilet Organization but what a load of — oh crap, am I perhaps also complicit in this complaining culture?
In order to prevent my innately-Singaporean negativity from clouding my judgement, I guess I’ll have to use some good old data science to conduct this study.
In the next section, I’ll be explaining the deep learning technique used to perform sentiment analysis — skip ahead to the end if you want to find out what the results are.
What is sentiment analysis?
Sentiment analysis is a technique to study the opinions or emotions expressed in a given text.
Many companies use sentiment analysis to track how their brands are being perceived by people through online platforms like the app store or Amazon reviews.
For our use case, we want to use sentiment analysis to measure how Singaporeans perceive specific news articles.
Computers struggle at sentiment analysis
Sentiment analysis is difficult for machines because human languages are highly complex. And so machines find it really hard to understand if the emotion behind a sentence is positive, negative, or neutral.
For example, the English language has many words that while seemingly identical, can have drastically different meanings when used in different contexts.
Take the use of the word wound in the following sentences:
John wound the clock. The arrow inflicted a wound onto her arm.
Traditional NLP techniques like static word embeddings are only able to ascribe one single meaning to each word. So in traditional techniques, the word wound would have the same meaning to a computer regardless of the way it was being used in a sentence.
But thankfully, the field of NLP has started seeing more advanced language modeling techniques such as BERT, which we will use in this study.
BERT from Sesame Street saves the day
BERT, or Bidirectional Encoder Representations with Transformers, is a state-of-the-art natural language understanding model. When Google released BERT in 2018, it broke all existing records for gold-standard natural language understanding tasks.
The reason BERT outperforms previous NLP techniques at understanding language is because it tries to learn the context in which a word is used.
BERT was trained by studying billions of sentences from Wikipedia and other text sources, and then made to predict a bunch of words that was hidden from these sentences. In doing so, BERT gets a better understanding of the context in which words appear compared to traditional static word embedding techniques!
Sorry did I sound too excited? What I really meant was, oh BERT’s just alright. Like, what a dumb name. I mean they only named it BERT because its predecessor was named ELMO.
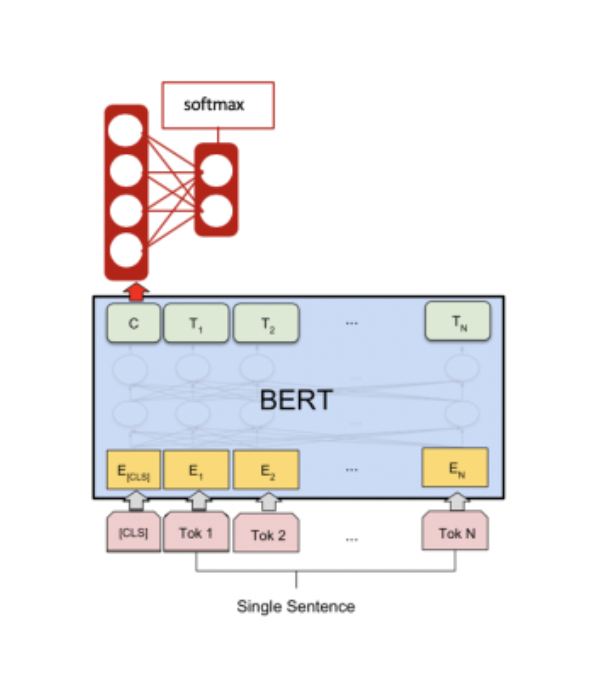
For our specific sentiment analysis use case, we fine-tune a BERT model to perform a classification step of 3 possible classes: positive, negative, and neutral. What this means is that we need to take the pre-trained BERT model from Google and teach it how to analyze sentiments from sentences.
In short, the model needs to do the following steps:
- take in a sentence — in our case an English sentence — and produce a contextual word embeddings representation for the sentence (specifically for the [CLS] token)
- pass the [CLS] contextual word embedding vector into a 3-dimension output vector (each dimension corresponds to the 3 classes)
- perform a softmax on the 3-dimension output vector to determine whether the sentiment is positive, negative, or neutral.
What this means is that BERT takes a sentence and converts it to a mathematical representation that machines can understand and work with.
Here’s one way to think about it
BERT is an English-as-a-second-language student trying to understand English. He could read a sentence in English but it would be way easier if he translates it into a language that BERT is fluent in — let’s say, BERT-lish.
So BERT does just that — he translates the input sentence to BERT-lish. And finally, BERT determines if the BERT-lish sentence is positive, negative, or neutral.
This is of course a gross simplification of the BERT model, but hey, I don’t want to get more complaints about how long the article would have been if I tried to fully explain it. Here are some good resources if you want to learn more about BERT.
Fine-tuning BERT for sentiment analysis
I fine-tuned BERT, specifically, BertForSequenceClassification using thebert-base-uncased model from the huggingface transformers library.
The fine-tuning process was conducted on the Twitter airline sentiment dataset — my training code can be found in this repo: bert-sentiment-analysis-straits-times

The dataset contains 14,640 tweets that were manually classified as negative, positive, or neutral. I created a training set with 80% of the dataset and kept the other 20% for validation.
I ran the training on a Google Colab notebook with a GPU and obtained the following validation results. The entire training process took approximately 20 minutes to complete.
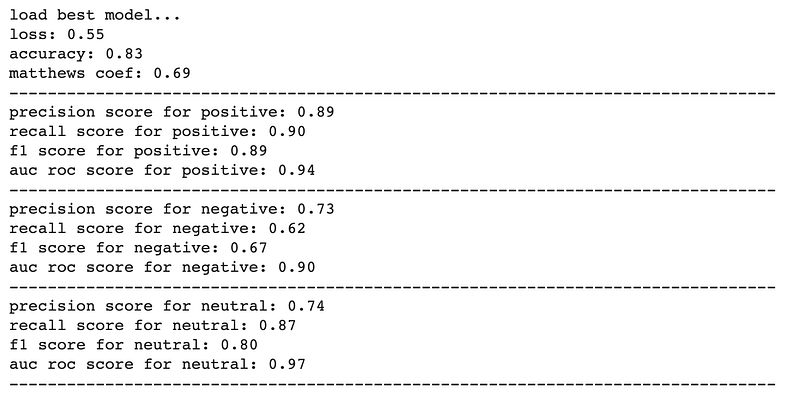
The results show that the model has an 83% accuracy — that is, it is able to accurately predict the correct sentiment given an input sentence 83% of the time.
It also appears that the model is better at predicting comments that are positive than negative or neutral.
Great, now that we have a decent model that can predict sentiments, let’s test it out on a bunch of comments made by Singaporeans!
A random Sesame Street aside. I’ve been obsessively binging the incredible podcast The Weirdest Thing I Learned This Week and discovered that according to folklore, vampires are obsessive counters.
That is, they feel compelled to count every single object around them — which is why people threw poppy seeds on the burial grounds of suspected vampires so that they would be so preoccupied with counting them that they wouldn’t attack humans. So perhaps Sesame Street was actually on point with the characterization of Count Dracula. Anyway, on to the results.
Results: Sentiment analysis of comments on The Straits Times articles
The Straits Times is my favorite national newspaper. And judging from how fervently Singaporeans from all walks of life comment on the news articles, I’m sure it is also the beloved source of #realnews for many Singaporeans.
And so, to answer the two questions I posed earlier about (i) exactly how negative are Singaporeans, and (ii) do we dislike all topics equally, I collected a bunch of Facebook comments from 5 randomly selected articles on The Straits Times to run the analysis on.
The 5 articles I chose to study were:
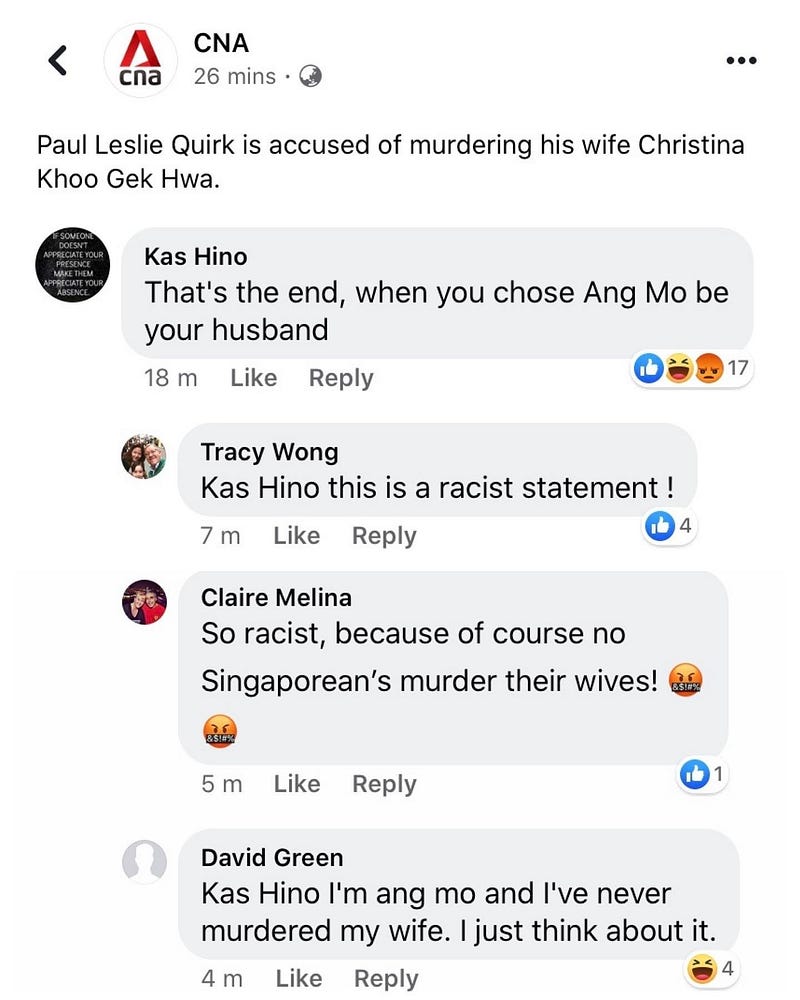
- Husband runs off when wife is pregnant and defaults on paying maintenance
- China launches gigantic telescope in hunt for life beyond earth
- Tsai Ing-wen re-elected Taiwan President; KMT’s Han Kuo-yu concedes defeat
- Forum: Promote plant-based diet to cut Singaporean’s carbon footprint
- Menacing mynas, pigeons and crows: Complaints about nuisance birds rising
There were 257 comments in total across the 5 articles.
How good is BERT at analyzing the sentiments of Straits Times comments?
In the previous step, we fine-tuned the BERT model on the Twitter airline sentiments dataset, and verified that it works well. Typically, a good computer scientist would verify that this model also works well on a test dataset of interest — in our case the Straits Times comments.
What this means is that we should collect a bunch of comments from The Straits Times’ posts and manually label them as positive, negative, or neutral. However, I’m doing this in my spare time on a Sunday, so ain’t nobody got time for that.

Instead, I’m going to take the short-cut of using the model to predict the sentiments in The Straits Times’ comments and then looking through the predictions to see if they make sense.
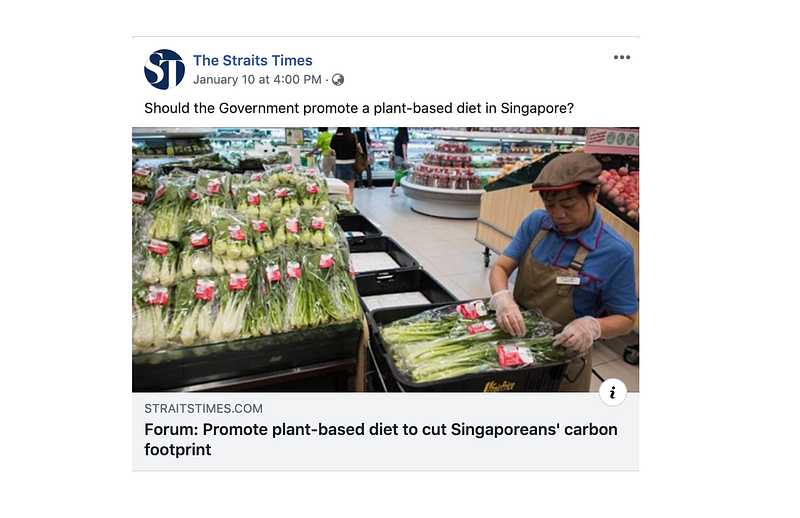
Let’s take a look at the comments on any article — for example this one: Forum: Promote plant-based diet to cut Singaporeans’ carbon footprint. The article is an opinion letter that asks the government to intervene or “nudge” Singaporeans towards plant-based diets.
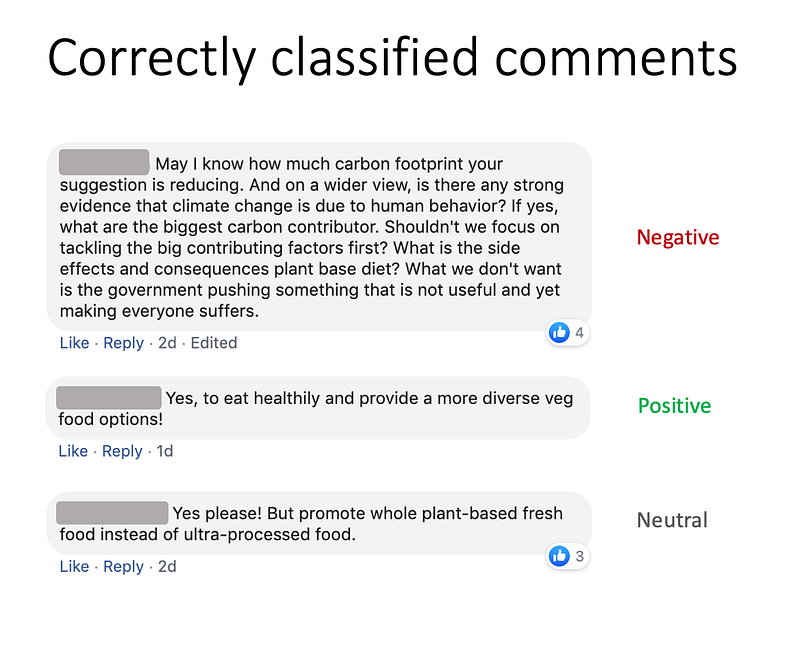
Correctly classified comments
The model does a pretty good job identifying the correct classes of many comments, despite some comments having spelling and grammar issues.
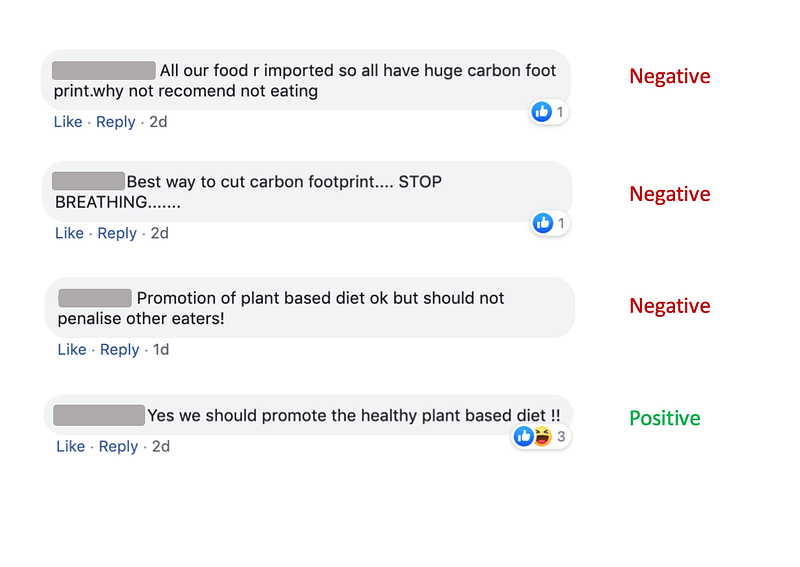
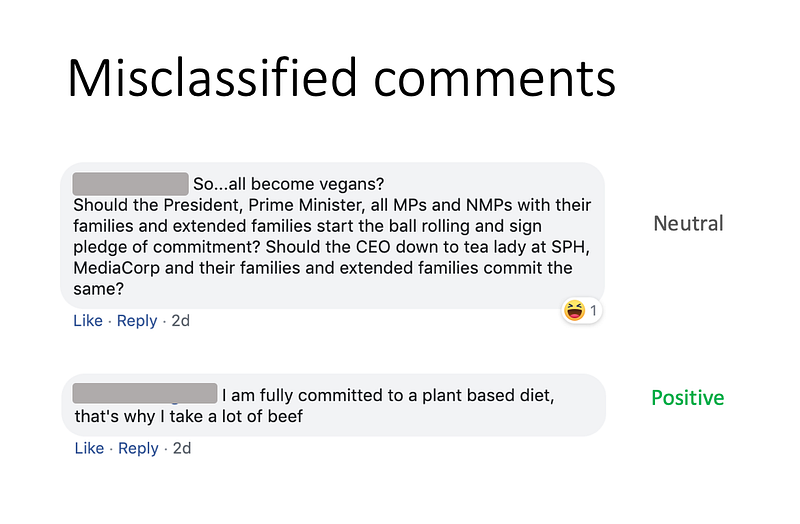
Misclassified comments
However, there were a few comments that were misclassified.
For example the first comment below was classified as neutral, when the user actually had a negative sentiment in the response. The way I interpreted the comment was this: the user demands for political leaders and news organizations to first adopt a vegan diet before shoving veganism down his/her throat. However, this required some inference, which existing NLP models like BERT aren’t very well-versed at doing.
Additionally, in the second comment below, the user was being sarcastic — and BERT, like most state-of-the-art NLP models, struggle to understand sarcasm.
Special shoutout to these comments that are uninterpretable even to humans
Cool, so BERT works pretty well at classifying The Straits Times’ comments! Let’s use it to study all the comments on the 5 articles that we’ve selected above.
Good news! Not all of our comments are negative!
Maybe Singaporeans aren’t negative Nancies after all. As it turns out, only 52.9% of our comments were negative.

And if I were to be optimistic about the situation, what this means is at 48.1% of the comments were positive or neutral!
Which articles get Singaporeans the most riled up?
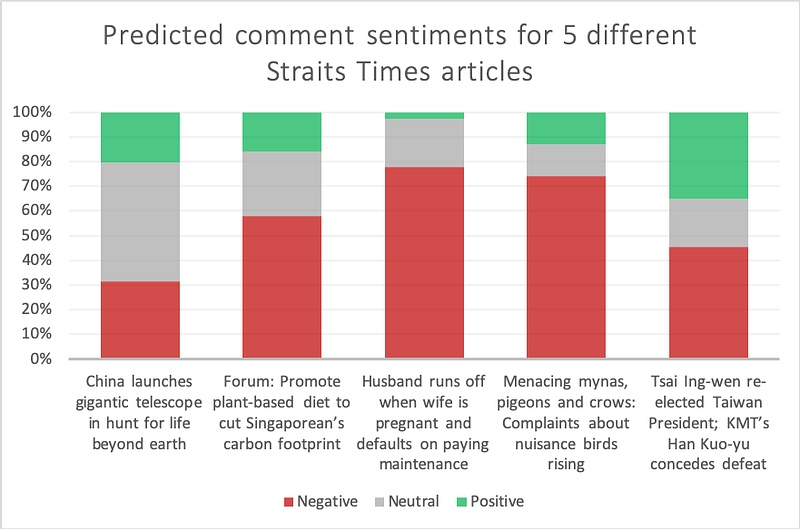
“Husband runs off when wife is pregnant and defaults on paying maintenance” made Singaporeans most upset — with 77.8% negative and 2.8% positive comments.
On the other hand, “Tsai Ing-wen re-elected Taiwan President; KMT’s Han Kuo-yu concedes defeat” made Singaporeans the most happy — with only 45.3% negative and 34.8% positive comments!
My feelings/sentiments on this entire process
BERT is a pretty powerful language model — but while the field of NLP has made significant advancements in recent years, it still has a long way to go before machines can fully comprehend humans.
But then again, I too find it hard to understand humans sometimes.
The views in this article are my own and do not reflect the views of the organizations that I am a part of.
I hope you enjoyed reading this article. If you would like to read some of my other fun and frivolous™ projects, check these out:
Acknowledgements
Special thanks to sebsk for open-sourcing their CS224N project from which I referenced much of the BERT fine-tuning process.