
Apache Spark 3.0 Adaptive Query Execution
Today, Spark SQL is one of the most valuable components of Apache Spark. It powers both SQL queries and the DataFrame API. At its core, the Catalyst optimizer, which leverages advanced Scala features to build an extensible and extremely powerful query optimizer.

In this article, we will try to understand the workflow of the Catalyst Optimizer and then dive deep into the new optimizations that Adaptive Query Execution enables.
Adaptive Query Execution (AQE) is a new feature available in Apache Spark 3.0 that allows it to optimize and adjust query plans based on runtime statistics collected while the query is running. To understand how it works, let’s first have a look at the optimization stages that the Catalyst Optimizer performs.
Catalyst Optimizer 101
The catalyst optimizer applies optimizations during logical and physical planning stages. It optimizes the query logically then generates a range of physical plans and selects the most efficient one based on a cost model.
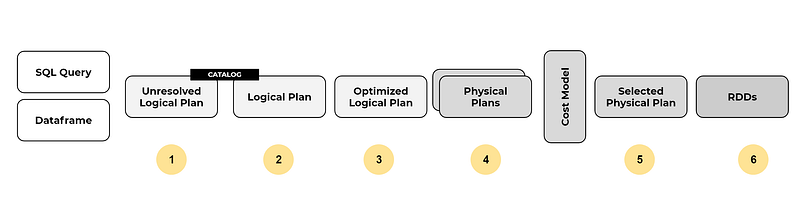
- Unresolved Logical Plan: For a SQL query or a Dataframe, the optimizer accepts the unresolved logical plan and checks against syntax errors.
- Logical Plan: The optimizer uses the catalog to resolve the names that are still unresolved in the unresolved logical plan and then converts it into a logical plan.
- Optimized Logical Plan: The logical plan is enhanced by reorganizing the query order most efficiently.
- Physical Plans: Defines how the logical plan will physically execute across the cluster. In this stage, it produces many physical plans.
- Selected Physical Plan: Physical plans are evaluated using a cost model and the best one is selected.
- RDDs: Finally, the optimizer converts the physical plan to RDDs, and then generates bytecode for the JVM.
In Spark 2.X, all the optimizations were rule-based. They are all based on estimations that are calculated before runtime hence there may be other tuning possibilites that appear as the query runs and also issues that cannot be predicted from before the execution.
Adaptive Query Execution
AQE improves the Catalyst Optimizer workflow adjusting query plans based on runtime statistics collected during query execution.
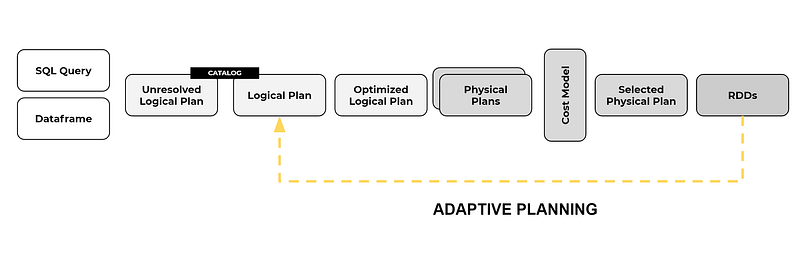
Spark will send statistics about the real size of the data in the shuffle files so that for the next stage, it re-optimizes the logical plan to dynamically switch join strategies, coalesce the number of shuffle partitions, or optimize skew joins.
- Switch join strategies : Broadcast Hash Join (BHJ) is one of the performant join strategies using Spark, it requires broadcasting the join relation. For it to stay optimal, there is a broadcast-size threshold (default 10mb). The issue with Spark 2.X optimizer is that it relies on an estimation of data based on input file sizes, this estimation cannot be always accurate as filters and complex operators can interfere to modify the size meanwhile. When AQE is enabled, it replans the join strategy at runtime based on the most accurate join relation size.
- Coalse shuffle partitions: If you did any dirty hands-on with Spark, you know that you have to tune the shuffle partitions at one time or another. The main issue with shuffle partitions is that the best number to choose is relevant to data size. Coming up with a number is not an easy task, so people generally use several trials and then choose the best one. But if they got it wrong, it can lead to spilling data to disk or lots of network data fetches. AQE combines adjacent small partitions into bigger partitions at runtime by looking at the shuffle file statistics, so we can set the number to a big one at first and AQE will do the rest :)
- Optimize skew joins: Data skew is a problem of data distribution. Meaning that you have data skew if your partitions vary largly in size in the cluster. It can downgrade query performance, especially with joins. AQE detects such skew automatically from shuffle files statistics. It then splits the skewed partitions into smaller subpartitions, which will be joined to the corresponding partition from the other side respectively.
Conclusion
AQE is a great addition to the Apache Spark optimize. It can dramatically speed up your queries. Under the hood, It improves your query plan as your query runs, eliminating the need to collect statistics or worry about inaccurate estimations and hard-core spark config tuning.
Note that It is turned off by default, but you can enable it by setting spark.sql.adaptive.enabled to true. Please check the documentation for details on the configuration options.




