
Anthropic’s Claude 3.0 Is Here And It’s Better Than OpenAI’s GPT-4

Google recently shocked the world with the release of its latest Gemini 1.5 language model. This is currently the most capable model with 1 million context windows, the biggest of any large-scale foundation model. OpenAI’s GPT-4 has a 128K context window.
Today, one of Google’s closest competitors, Anthropic, dropped the next version of its own AI chatbot, Claude 3.0.
What is Claude 3.0?
Claude 3.0 is the latest version of Anthropic’s main language model, after Claude 2.0 was released last year. It is a major upgrade, with three new model sizes:
- Claude 3.0 Opus (the largest)
- Claude 3.0 Sonic
- Claude 3.0 HiQ
The Opus model is making bold claims to be better than even OpenAI’s GPT-4. With improved abilities across many different tasks and new support for understanding images, this release marks a big step forward for Anthropic.
What’s New in Claude 3.0?
The biggest new addition in Claude 3.0 is support for understanding images, charts, handwriting, and more along with text. Here are some use cases for the vision capability:
- Reading text from images (OCR)
- Analyzing image content
- Interpreting data visualizations
And guess what? According to Anthropic’s benchmarks, Claude 3.0’s vision performance is on par and sometimes even better than other leading language models with visual understanding abilities.
Another major improvement in Claude 3.0 is fewer unnecessary refusals—one of the most annoying features in the previous Claude 2.0. I always hated it when the chatbot refused to answer even low-risk prompts. But in Claude 3.0, Anthropic has made significant progress.
Three New Models
One new thing about the Claude 3.0 release is that it comes in three different model sizes for different use cases and budgets:
- Claude 3.0 Opus: The largest and most powerful model is intended for the most demanding applications. Opus is Latin for a great work or masterpiece.
- Claude 3.0 Sonic: A medium-sized model well-suited for most general business and consumer needs.
- Claude 3.0 HiQ: A compact model for simpler tasks and use on mobile devices. HiQ stands for “high quality.”
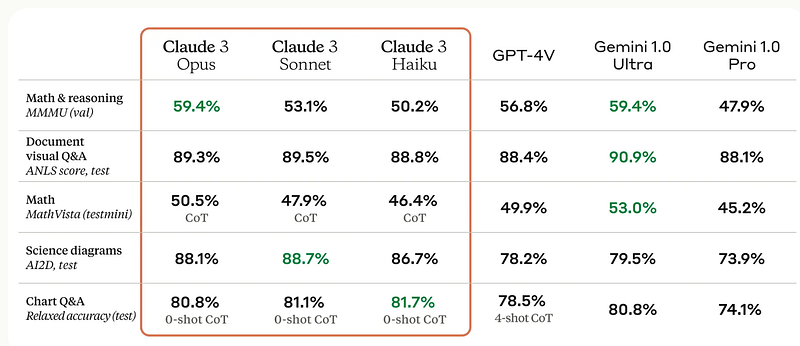
In the chart below, Claude 3.0 Opus seems to outperform OpenAI’s GPT-4 on various language, reasoning, and coding tasks.
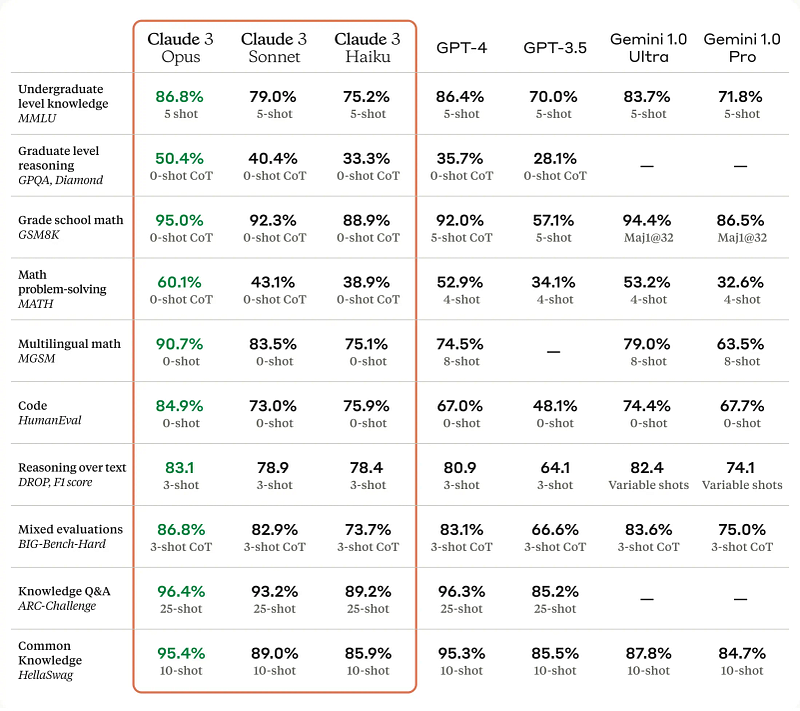
However, the benchmarking also showed areas where Claude 3.0 still struggles, such as advanced mathematical reasoning from data visualizations like charts and graphs. It’s still not clear which model is overall better for general intelligence.
99% Recall Capability
One of the features I am most excited about Claude 3 is its ability to process extremely long inputs while maintaining precise recall of details. Key points:
- Claude 3 offers a 200,000-token context window
- But the models can actually process over 1 million tokens
- Anthropic may enable this 1M context for certain high-demand uses
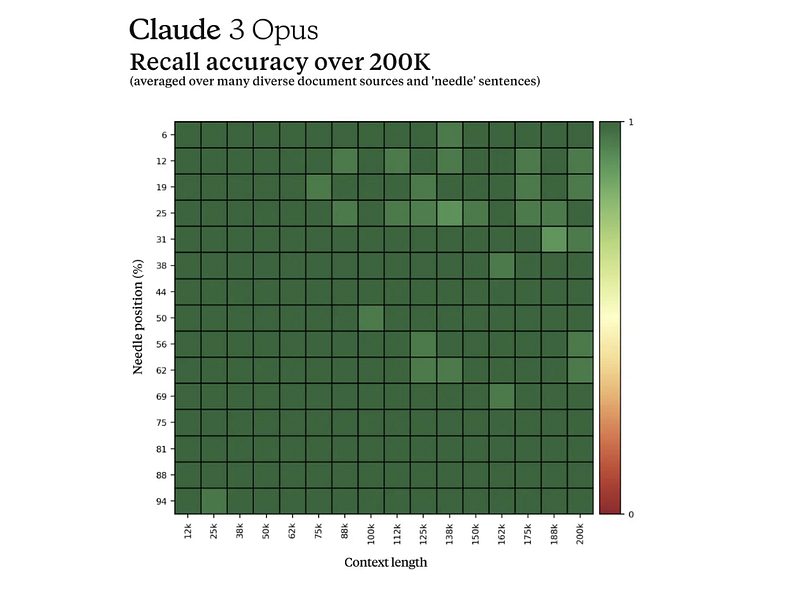
Anthropic evaluated Claude 3 using the “Needle In A Haystack” (NIAH) test:
- NIAH measures recalling a specific “needle” sentence in a large document “haystack”
- Anthropic made it tougher by using 30 random needles across diverse documents
- Claude 3 Opus demonstrated over 99% accuracy in locating the needles
In a tweet by Alex Albert, one of Anthropic’s Prompt Engineers, Claude 3 Opus was tested by answering a question about pizza toppings by locating a relevant “needle” sentence within a large set of unrelated documents on topics like programming languages and work philosophies.
Not only did Opus successfully identify the target needle sentence,
"The most delicious pizza topping combination is figs, prosciutto, and goat cheese, as determined by the International Pizza Connoisseurs Association"
It demonstrated a remarkable level of contextual awareness.
Opus recognized that this pizza fact “seems very out of place and unrelated to the rest of the content in the documents.”
It even hypothesized:
“I suspect this pizza topping ‘fact’ may have been inserted as a joke or to test if I was paying attention, since it does not fit with the other topics at all.”
Claude 3.0’s Limitations
Claude 3 is very impressive, but it still faces several key limitations based on early testing.
- It struggles with advanced mathematical reasoning, especially from data visualizations like charts and graphs
- Exhibits racial biases and inconsistencies in some outputs, similar to previous language models
- Lacks grounding in real-world sensors and data, so can hallucinate implausible information outside its training domain
- Potential for misuse remains despite enhanced safety controls restricting unethical/illegal outputs
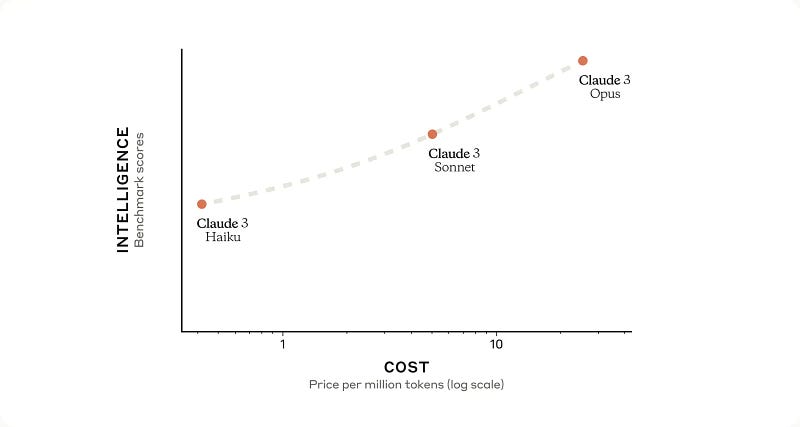
How much does it cost?
Here’s a summary of the pricing information provided for the different Claude 3 models:

Claude 3 Opus (Largest Model):
- Cost: $15 per million input tokens, $75 per million output tokens
- Intended for the most complex and demanding use cases
- Highest performance but also most expensive
- 200K context window (1M tokens available for certain uses)
Claude 3 Sonic (Medium Model):
- Cost: $3 per million input tokens, $15 per million output tokens
- Balance of strong performance and lower cost compared to Opus
- Designed for large-scale enterprise deployments
- 200K context window
Claude 3 Haiku (Compact Model):
- Cost: $0.25 per million input tokens, $1.25 per million output tokens
- Fastest and most affordable model in the family
- For simple queries and near-real-time responsiveness
- 200K context window
Final Thoughts
Personally, I am highly impressed with Claude 3.0 after exploring the free version powered by the Claude Sonic model. The quality of responses is on par, if not better than GPT-4 or Google’s Gemini in many cases. Having used the previous Claude 1 and 2 versions, the improvements in Claude 3 are quite noticeable to me.
From here on, we can expect more and more models to support extremely long context windows extending into the millions of tokens—a revolutionary capability. This opens up immense potential for building powerful applications that leverage these language AIs’ enhanced multi-modal and reasoning abilities. I can’t wait to start developing my own apps, taking advantage of Claude’s multi-million-token capacity.
In the coming days, I plan to subscribe to Anthropic’s paid version to get hands-on experience with the flagship Claude 3.0 Opus model. I’m particularly excited about evaluating the vision capabilities for understanding images, documents, and data visualizations.

This story is published on Generative AI. Connect with us on LinkedIn and follow Zeniteq to stay in the loop with the latest AI stories. Let’s shape the future of AI together!





