
An introduction to Probability Sampling Methods
Why sampling methods are essentials for your Data Science’s journey
I met the sampling techniques when I was still studying statistics. I remember that it was one of the topics I liked more since the professor explained them deeply and made me understand how they are fundamental for many survey studies, but in that period I was so full of other courses and other thoughts that I forgot these useful concepts as soon as I passed the exam.
However, during my Data Science master and in my actual research work, I indirectly saw sampling methods involved in many Machine Learning models, such as Decision Forest, Random Forest, Isolation Forest, and many others. They are also employed to solve problems, like the imbalanced class distribution in the dataset, and improve the evaluation of the model’s performance by using a resampling procedure, called K-fold Cross-Validation.
For this reason, I decided to investigate further this amazing topic, which has a key role when dealing with a huge amount of data. I will begin by defining what is sampling. Once the principal concepts are clear, the next step is to explain different sampling techniques, focusing on the Probabilistic sampling methods.
Introduction
In a statistical study, it’s not always possible to get access to the data from all the cases. For this reason, the most practical way is to include a part of the whole population, called sample.
When conducting sampling, we need to define some relevant terms. First, Target Population includes the whole set of items we are theoretically interested in. We need to distinguish the Target Population from the Study Population, sometimes also called the Sample Population, which is a subset of the target population we can obtain.
Sampling is essentially the process of selecting a sample from the Study Population. An important requirement is that the sample needs to be representative of the population, as much as possible, in order to generalize the characteristics of the entire population.
This is possible by employing different sampling methods, that can be divided into two main groups:
- Probabilistic Sampling Methods: the probability that every unit in the population of being selected is known.
- Non-Probabilistic Sampling Methods: the probability that every unit in the population of being selected is NOT known and is more related to the subjectivity of the researcher that is collecting the data.
In this post, I am going to focus on Probabilistic Sampling Methods. This type of method can be further split into different categories, shown below.
Probabilistic Sampling Methods:
- Simple Random Sampling
- Systematic Sampling
- Stratified Sampling
- Cluster Sampling
- Multi-Stage Sampling
1. Simple Random Sampling
Simple Random Sampling (SRS) is the simplest method to sample a population, which is simply a collection of items [1]. If check the definition of Simple Random Sampling, you probably found this somewhere:
Simple Random Sampling ensures that each element of the population has an equal probability of selection
It’s not totally wrong, but it depends on the way on type of extraction process:
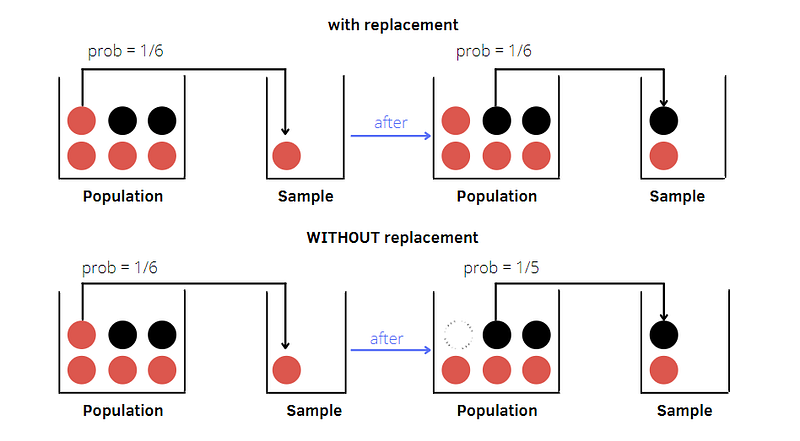
- SRS with Replacement: all the units of the population will have the same probability of being selected 1/N. For example, let’s consider an urn containing 4 red balls and two black balls. In the first extraction, the red ball is drawn randomly from the urn. All the balls will always have 1/6 of probability of being sampled.
- SRS WITHOUT Replacement: At the first extraction, each one of the population units will have an equal probability of selection 1/N. At the second extraction, the remaining N-1 units will have a selection probability equal to 1/(N-1). In the example, we observe that the selection probability changes in the second extraction. This violates the definition shown at the top!
Advantages:
- It’s simple and doesn’t use auxiliary information on the population
- the selection is random and, then, any unit is favored
- the sample is representative
Disadvantages:
- the choice of the element is completely random
- a complete list of the population units is necessary
- it’s time and cost consuming
2. Systematic Sampling
The Systematic Samplings can be summarized into two steps:
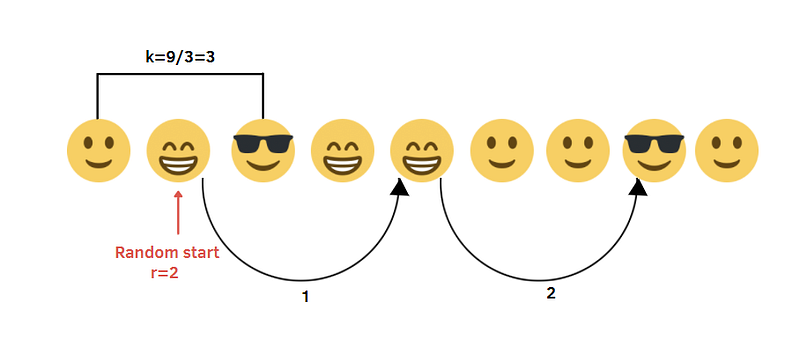
- Calculate the sampling interval k=N/n. In the illustration, we have 9 smiles and we want to obtain a sample of 3 units, then N=9, n=3, and k=9/3=3.
- Select a random integer r between 1 and k: 1≤r≤k. In the example, I selected randomly r=2, where 1≤r≤3.
- Once the first unit is selected, we take every following k-th item to build the sample: r, r+k,r+2k,…,r+(n-1)k.
Advantages:
- the random selection is applied only to the first item, while the rest of the items selected depend on the position of the first item and a fixed interval at which items are picked.
Disadvantages:
- if the list of the population elements presents a determined order, there is the risk of obtaining a not representing sample
3. Stratified Sampling

The population is classified into subpopulations, called strata, based on some categorical characteristics, such as age, gender, and education. The Stratified Sampling is efficient if the groups are internally homogenous and heterogenous among themselves. From each stratum, we extract a simple random sample. The aggregation of these samples produces a stratified sample.
To calculate the stratum sample size, there are two common allocation techniques:
- Proportional Allocation is the most simple and widely used scheme in practice. It provides the same sampling fraction within each stratum nₕ/Nₕ, which corresponds to the global sampling fraction n/N: fₕ=nₕ/Nₕ=f=n/N. In the illustration, we have two groups, based on the type of fruit. The strata populations are respectively N₁=6 and N₂=9. By proportional allocation, we select samples with a total sample size of n=5. According to the theory, we want the same sampling fraction equal to 5/15=1/3. As you can observe, this criterion is respected: n₁/N₁=2/6=1/3 as a sample fraction in the group of apples and n₂/N₂=3/9=1/3 in the group of oranges.
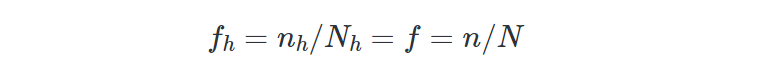
- Optimal or Neyman Allocation is based on the idea that the sampling fractions should be different in each stratum and assumes that the strata sampling size nₕ is directly proportional to the standard deviation of stratum Sₕ. This allocation is more effective and precise than the Proportional Allocation when the stratum variances are different between them.
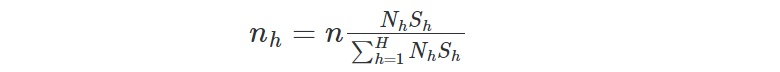
Advantages:
- it can be more efficient than simple random sampling
- there is less risk of obtaining non-representative samples
Disadvantages:
- It needs the availability of auxiliary information on the population.
- there are strict conditions for the strata, which need to be exhaustive and mutually exclusive.
4. Cluster Sampling
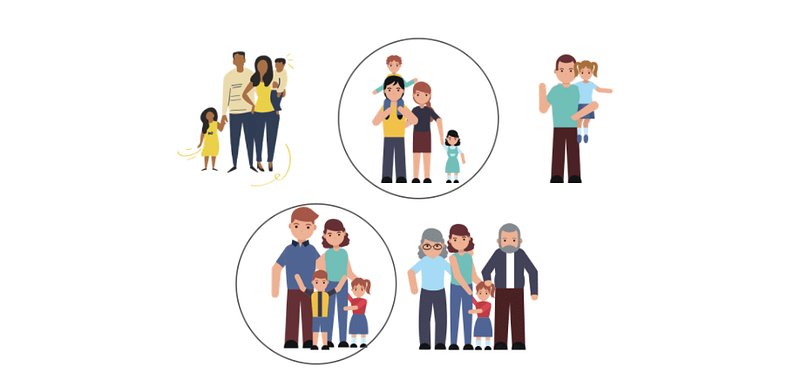
Cluster Sampling assumes that the population can be constituted by subsets of elementary units, called clusters. Apparently, it may seem similar to Stratified Sampling, but the principles are completely different.
In Stratified Sampling, the groups are internally homogenous and heterogenous among themselves. Differently from Stratified Sampling, the clusters are similar among themselves and each cluster contains elements with different characteristics.
For example, if we are interested to study the residents of New York, we may consider the population constituted by people belonging to families in the same city. A family is a classic example of a cluster, which contains different members among themselves.
Instead of extracting some elements from the groups, Cluster Sampling permits to draw randomly some clusters from the population. If we considered the population divided into families, we may extract randomly some families, like in the illustration.
Advantages:
- it’s efficient when the clusters constitute naturally formed subgroups, for which we don’t possess the list of the population
- if the units are characterized by dispersion on the territory and direct contact is necessary, studying only some clusters can be less expensive than simple random sampling.
Disadvantages:
- the conditions of the clusters aren’t always respected. The clusters may contain similar elements.
5. Multi-Stage Sampling
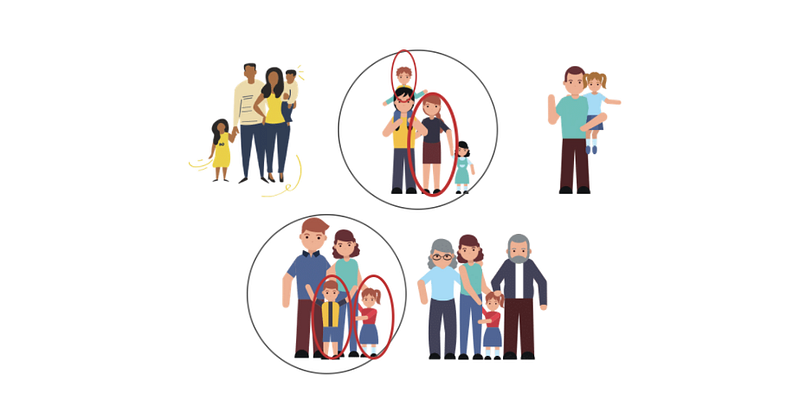
In reality, the naturally formed subgroups of the population, clusters, may contain similar units if the cluster size is small and the clusters are identified based on the territory’s characteristics.
It may more convenient to analyze some units for each cluster, instead of taking into account all the elements. This type of design is called two-stage cluster sampling. If we consider again the families with residence in New York, we may extract randomly two people from the already selected clusters.
So, the multi-stage sampling split up a large population into “stages” to make the sampling process more efficient.
Advantages:
- multi-stage sampling can be more efficient than cluster sampling when the clusters are homogenous among themselves and internally heterogeneous.
- the sampling size decreases
- it’s less complex to organize and cost-efficient
Disadvantages:
- In case, the conditions of the clusters are not respected, the multi-stage sampling results are less efficient than simple random sampling.
Final thoughts:
I hope you found useful this tutorial to learn more about Probabilistic Sampling Methods. It can be challenging to study this topic without looking at the examples. In the field of Machine Learning, simple random sampling and stratified sampling are the most widely used to evaluate the performance of the model. There are surely other sampling methods I didn’t cover here. My goal was to focus on the most relevant techniques. I am covering the Non-Probabilist Sampling methods in the next post. Thanks for reading! Have a nice day.
[1] “Survey sampling reference guidelines, Introduction to sample design and estimation techniques”, Eurostat
Did you like my article? Become a member and get unlimited access to new data science posts every day! It’s an indirect way of supporting me without any extra cost to you. If you are already a member, subscribe to get emails whenever I publish new data science and python guides!





