
Fixing Imbalanced Datasets: An Introduction to ADASYN (with code!)
Introduction
Any real-life data set used for classification is most likely imbalanced, with the event that you are interested in being very rare (minority examples) while non-interesting events dominate the data set (majority examples). Because of this, machine learning models that we build to identify for the rare cases will perform terribly.
An intuitive example: Imagine classifying for credit card fraud. If there are only 5 fraudulent transactions per 1,000,000 transactions, then all our model has to do is predict negative for all data, and the model will be 99.9995% accurate! Thus, the model will most likely learn to “predict negative” no matter what the input data is, and is completely useless! To combat this problem, the data set must be balanced with similar amounts of positive and negative examples.
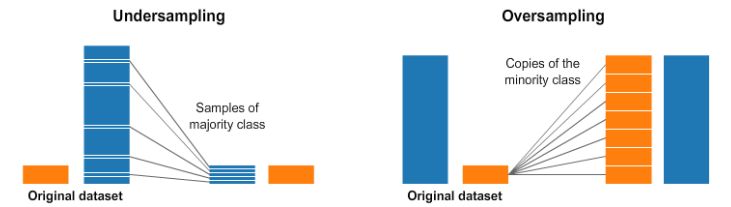
Some traditional methods to solve this problem are under-sampling and over-sampling. Under-sampling is where the majority class is down sampled to the same amount of data as the minority class. However, this is extremely data inefficient! The discarded data has important information regarding the negative examples.
Imagine building a house cat classifier, and having 1,000,000 images of different species of animals. But only 50 are cat images (positive examples). After down sampling to about 50 negative example images for a balanced data set, we deleted all pictures of tigers and lions in the original data set. Since tigers and lions look similar to house cats, the classifier will mistake them for house cats! We had examples of tigers and lions, but the model was not trained on them because they were deleted! To avoid this problem of data inefficiency, over-sampling is used. In over-sampling, the minority class is copied x times, until its size is similar to the majority class. The greatest flaw here is our model will overfit to the minority data because the same examples appear so many times.
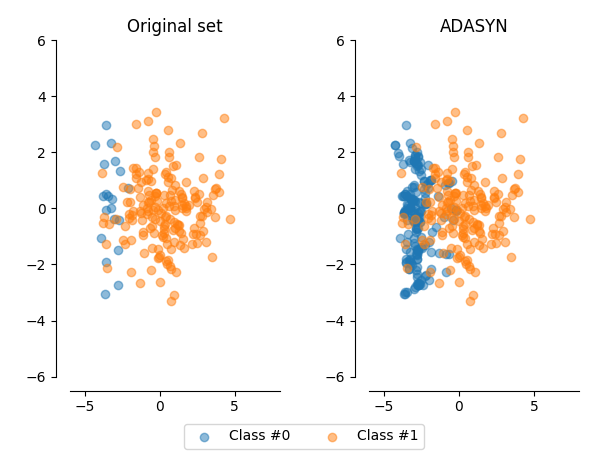
To avoid all of the above problems, ADASYN can be used! ADASYN (Adaptive Synthetic) is an algorithm that generates synthetic data, and its greatest advantages are not copying the same minority data, and generating more data for “harder to learn” examples. How does it work? Let’s find out! Throughout the blog, I will also provide the code for each part of the ADASYN algorithm.
The full code can be found here: https://github.com/RuiNian7319/Machine_learning_toolbox/blob/master/ADASYN.py
A link to the original paper can be found here https://sci2s.ugr.es/keel/pdf/algorithm/congreso/2008-He-ieee.pdf
ADASYN Algorithm
Step 1
Calculate the ratio of minority to majority examples using:
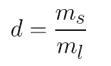
where mₛ and mₗ are the # of minority and majority class examples respectively. If d is lower than a certain threshold, initialize the algorithm.
Step 2
Calculate the total number of synthetic minority data to generate.
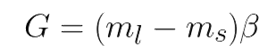
Here, G is the total number of minority data to generate. ß is the ratio of minority:majority data desired after ADASYN. ß =1 means a perfectly balanced data set after ADASYN.
Step 3
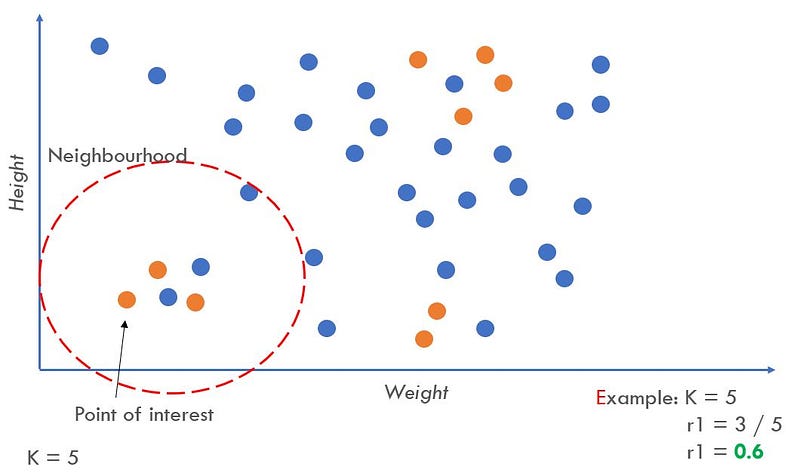
Find the k-Nearest Neighbours of each minority example and calculate the rᵢ value. After this step, each minority example should be associated with a different neighbourhood.
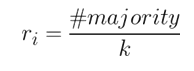
The rᵢ value indicates the dominance of the majority class in each specific neighbourhood. Higher rᵢ neighbourhoods contain more majority class examples and are more difficult to learn. See below for a visualization of this step. In the example, K = 5 (looking for the 5 nearest neighbours).
Step 4
Normalize the rᵢ values so that the sum of all rᵢ values equals to 1.
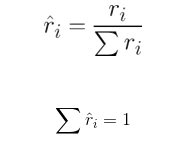
This step is mainly a precursor to make step 5 easier.
Step 5
Calculate the amount of synthetic examples to generate per neighbourhood.
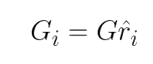
Because rᵢ is higher for neighbourhoods dominated by majority class examples, more synthetic minority class examples will be generated for those neighbourhoods. Hence, this gives the ADASYN algorithm its adaptive nature; more data is generated for “harder-to-learn” neighbourhoods.
Step 6
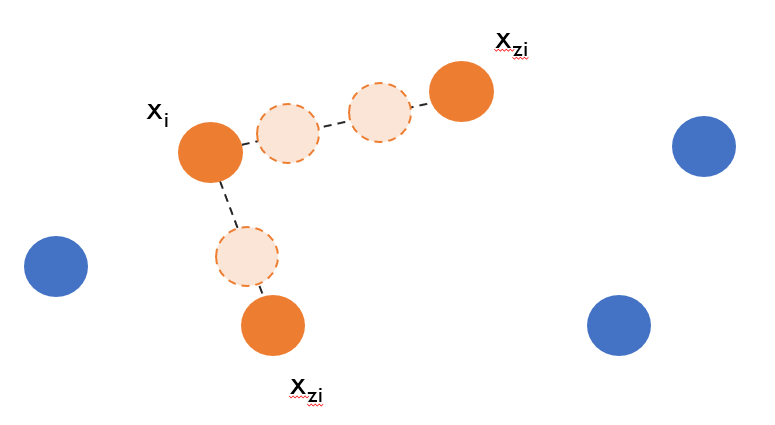
Generate Gᵢ data for each neighbourhood. First, take the minority example for the neighbourhood, xᵢ. Then, randomly select another minority example within that neighbourhood, xzᵢ. The new synthetic example can be calculated using:
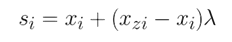
In the above equation, λ is a random number between 0–1, sᵢ is the new synthetic example, xᵢ and xzᵢ are two minority examples within a same neighbourhood. A visualization of this step is provided below. Intuitively, synthetic examples are created based on a linear combination of xᵢ and xzᵢ.
White noise can be added to the synthetic examples to make the new data even more realistic. Also, instead of linear interpolation, planes can be drawn between 3 minority examples, and points can be generated on the plane instead.
And that’s it! With the above steps, any imbalanced data set can now be fixed, and the models built using the new data set should be much more effective.
Weaknesses to ADASYN
There are two major weaknesses of ADASYN:
- For minority examples that are sparsely distributed, each neighbourhood may only contain 1 minority example.
- Precision of ADASYN may suffer due to adaptability nature.
To solve the first issue, neighbourhoods with only 1 minority example can have its value duplicated Gi times. A second way is to simply ignore producing synthetic data for such neighbourhoods. Lastly, we can also increase the neighbourhood size.
The second issue arises because more data is generated in neighbourhoods with high amounts of majority class examples. Because of this, the synthetic data generated might be very similar to the majority class data, potentially generating many false positives. One solution is to cap Gi to a maximum amount, so not too many examples are made for these neighbourhoods.
Conclusion
That wraps up the ADASYN algorithm. The biggest advantages of ADASYN are it’s adaptive nature of creating more data for “harder-to-learn” examples and allowing you to sample more negative data for your model. Using ADASYN, you can ultimately synthetically balance your data set!
The full code is available on my GitHub: https://github.com/RuiNian7319/Machine_learning_toolbox/blob/master/ADASYN.py
Thanks for reading, let me know if you have any questions on comments!





