
Natural Language Processing
An In-depth Look At How Rasa Featurizes User Input For Dialogue Prediction
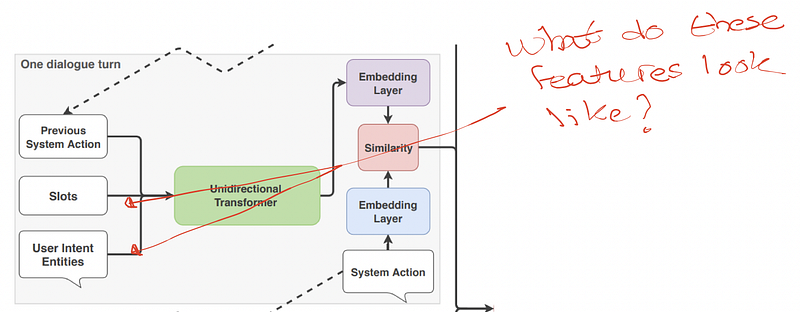
Introduction
In this article, we will look at how the extracted intent, entities, and slots get featurized by Rasa’s TED Policy to predict what the bot should do next.
The code to reproduce the results described in this article is here.
Intent
Suppose we have defined the following intents in our domain.yml:

The intents defined in Figure 1 will be internally represented as a lookup table like this:

Note that we have defined 8 intents in our bot’s domain.yml.
So, given the utterance “I am feeling happy” which Rasa’s NLU model classifies as mood_great :

The TED Policy will take the string mood_great and transform it into an 8-dimensional binary vector that looks like this:
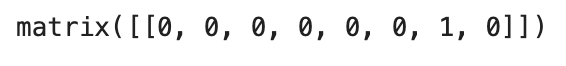
Notice that all elements in the binary vector in Figure 4 are 0 except for the 6th element (counting from 0). This position has the value of 1 because the 6th element corresponds to the value of the intent mood_great according to Figure 2.
Therefore, we can conclude that intents are represented as a one-hot encoded vector.
Entities
Overview
Suppose we’ve defined the following entities in our domain.yml:
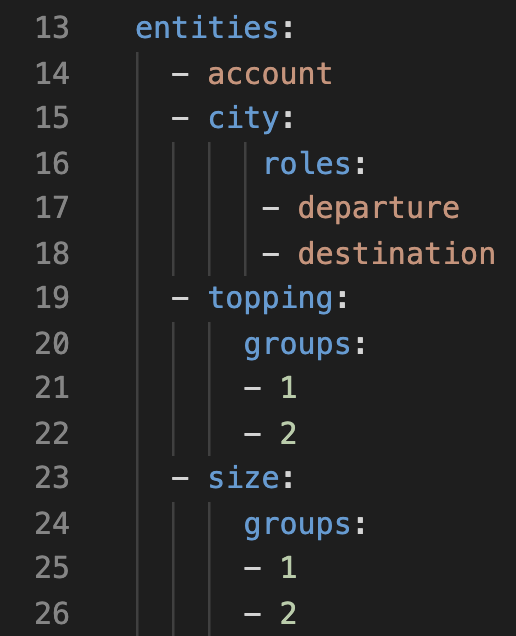
This will get translated into the following internal lookup table:

Notice that we’ve defined only 4 entities but the lookup table has 10 entries.
The reason for this is that entities with roles and groups are considered as separate entities and so are given additional entries for each value defined in their role and group.
Utterances With Only One Entity
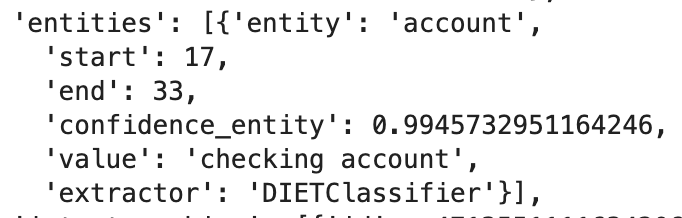
Given the utterance “I want to open a checking account”, the NLU model will extract the entity “account” with the value “checking account”:
TED Policy will use this information to construct the following vector:
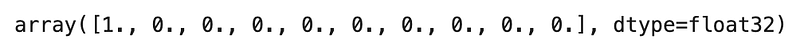
It should be clear that the value 1 in Figure 8 corresponds to the entity “account” based on Figure 6.
Utterances With Repeated Entities
What happens when an utterance contains multiple mentions of the same entity type?
For example, the utterance “I want to transfer money from my checking account to my savings account” contains the following entities:
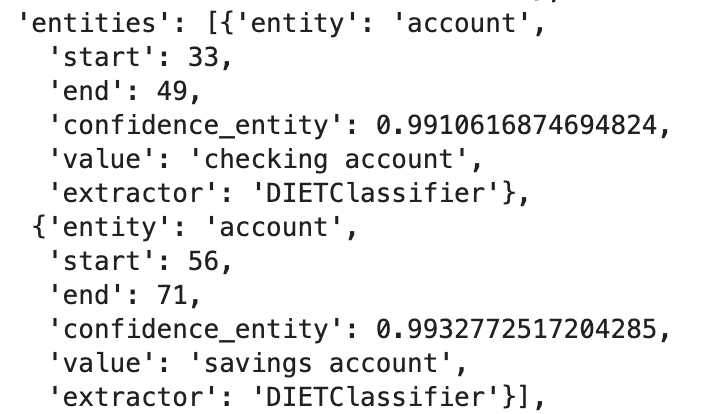
Figure 9 shows that we have two entities with the same type i.e. “account” but different values i.e. “checking_account” and “savings account”.
TED Policy will use this information to generate the following vector representation:
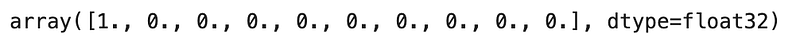
Notice that this is identical to the vector representation in Figure 8.
Therefore, we conclude that we cannot influence a conversation based on the number of entities mentions.
Utterances With Different Entities
The utterance “I want to open a savings account and travel to Berlin” will have the following entities extracted:
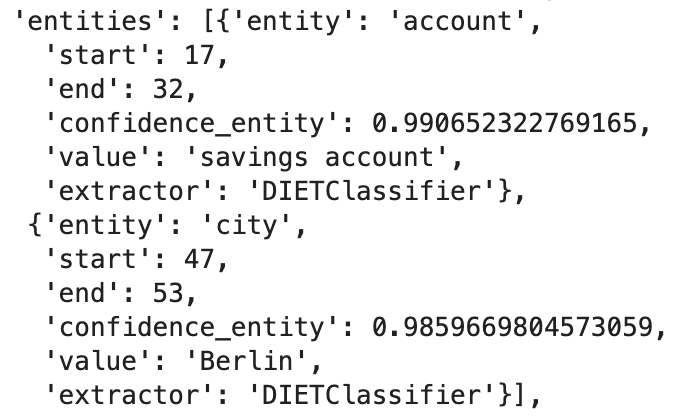
In this case, TED Policy will generate the following feature vector:
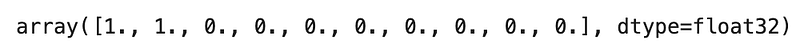
Therefore, we can conclude that the vector representation for extracted entities is a binary vector where a 1 indicates only the presence of the entity mapped to that position according to the internal lookup table.
Entities With Roles and Groups
The case of utterances containing entities with roles and groups is interesting.
Consider the case of entities with roles such as the utterance “I want to travel from Berlin to san francisco”. These are the entities extracted by the NLU model:

TED Policy will featurize the results in Figure 13 into the following vector:
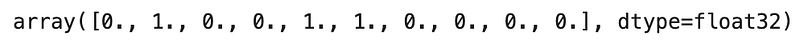
As expected, we see a 1 in the 4th and 5th elements as these elements correspond to the “departure” and “destination” roles for the “city” entity type.
What may not be expected is that there is also a 1 in the 1st element as this element just corresponds to the “city” entity type without any roles.
The same observation applies to entities with groups and with entities with both roles and groups.
Slots
Overview
Slots will have their own lookup table just like the case for intents and entities.
If we have defined the following slots in our domain.yml file:
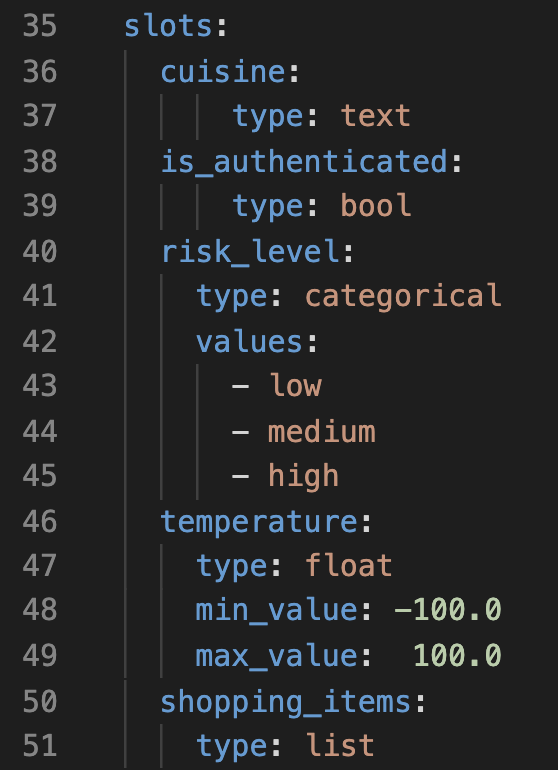
Then, this is how the internal lookup table looks:
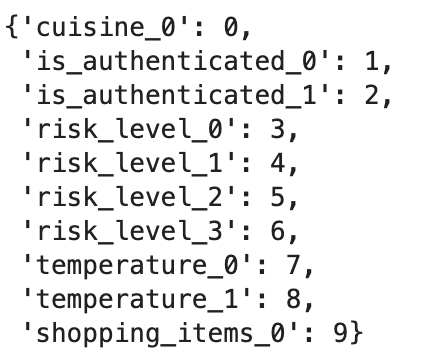
Let’s look at how each slot type gets featurized.
Text Slots
Setting the value of the “cuisine” slot to any value (except None) will result in the following feature vector:
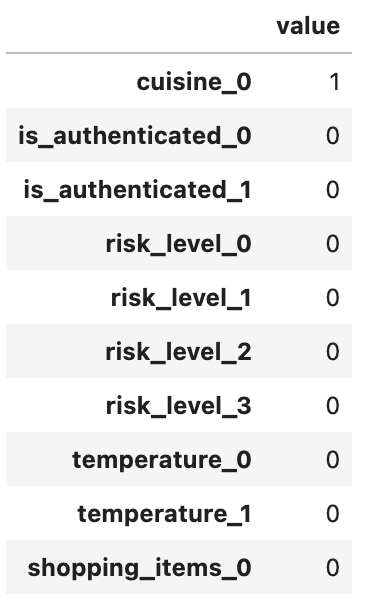
Therefore, although the type of the slot is Text, Rasa does not actually check that the type of value passed to the text slot is a string.
Boolean Slots
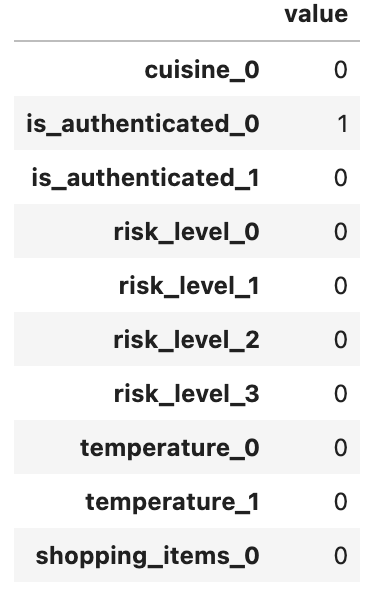
Setting the “is_authenticated” slot to False will produce the following feature vector:
This is what the vector representation looks like then the slot is set to True:
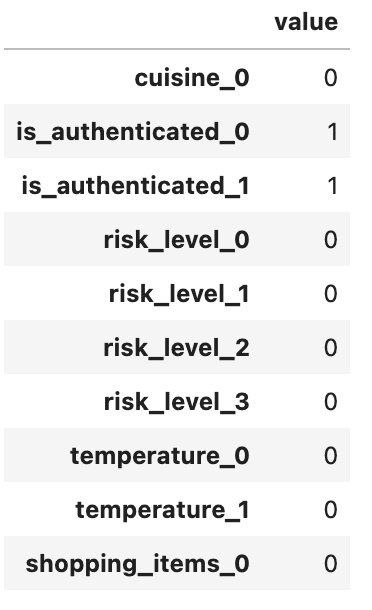
Notice that a boolean slot is represented using a 2-dimensional vector where True and False is represented as (1, 1) and (1, 0) respectively (as opposed to (0, 1) and (1, 0)).
Categorical Slots
The “risk_level” slot is a categorical slot with 3 levels (low, medium, high).
Notice that the lookup table has allocated 4 positions to this slot. The first 3 corresponds to the 3 levels defined in the domain.yml and the last one is for values assigned to this slot that is outside the predefined levels.
For example, if the slot was assigned the value “medium”, the feature vector looks like this:
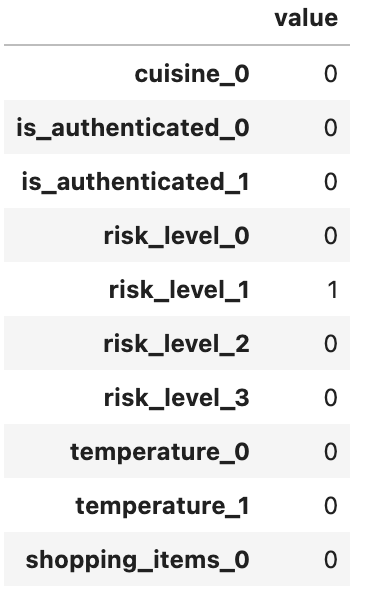
On the other hand, if the value is neither “low”, “medium”, or “high”, then the 4th position will be used. For example, this is the vector representation when the slot was assigned the value “super high”:
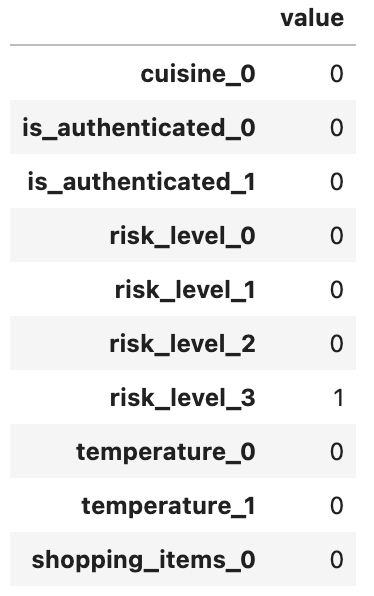
Float Slots
The “temperature” slot is defined to be a float slot with a min value of -100 and max value of 100.
This is the feature vector when “temperature” is set to 0:
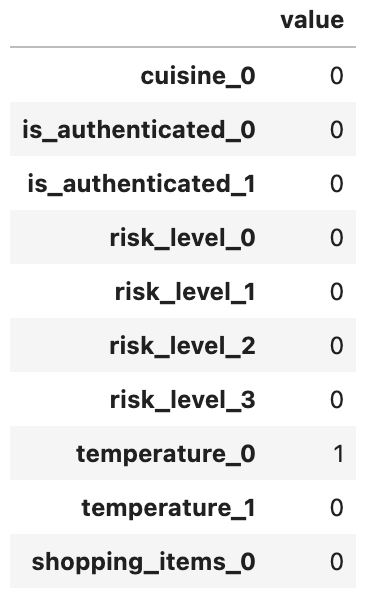
This is the feature vector when “temperature” is set to -200:
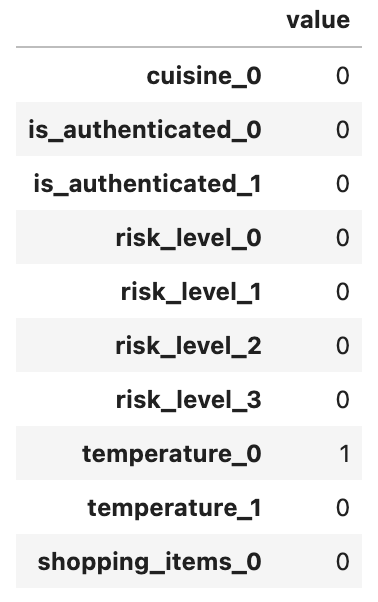
This is the feature vector when “temperature” is set to 200:
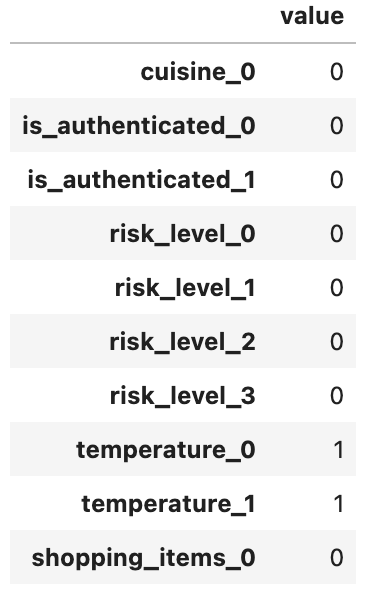
Based on the results in Figure 22, 23, and 24, it should be clear that we can use float slots to build stories that will branch differently when the assigned value is outside the max value but not when it is less than the min value, since it shares the same vector representation as when its value is within the predefined bounds.
List Slots
List slots are similar to Text slots in that any value passed to it (except None) will be considered as valid input for featurization.
For example, assigning any of these values to the “shopping_items” slot:
[“eggs”, “milk”]200“eggs”[None]
will give the same feature vector, namely:
Conclusion
This article has explained how intents, entities, and slots get featurized when using TED Policy to do dialogue predictions. It also identified some idiosyncrasies for certain types. These idiosyncrasies may seem trivial but are worth always keeping in mind because they do influence what stories you can write e.g. you can’t write stories that will branch based on the number of entities extracted (without writing custom code).
I hope you have found this helpful.