
An exploration into Natural Language Processing with the Universal Studios dataset

I have not posted a lot about Natural Language Processing, NLP, because there are not a lot of data science competitions concerning this genre of machine learning. I have, however, discovered that Kaggle, the premier data science website, does have text based datasets in their dataset section of their website. In order to gain some more experience using NLP and experimenting with the various functions that are associated with this type of machine learning.
Whilst studying Udacity’s Introduction to Machine Learning course, I learned that the Naive Bayes algorithm is very good for predicting on text based datasets, so I tried out all of the Naive Bayes estimators in the sklearn until I found the one that produced the highest accuracy. I would like to say that I tried other models, SVC and LinearSVC, and these two estimators did not produce predictions nearly as accurate as Naive Bayes. The trick is to try out several different models and select the best one for that set of data.
In addition to selecting the model that will afford the highest accuracy, it is also important to use the best stemmer in the nltk library. I had previously been using the PorterStemmer because that is the only one I was aware of, but Udacity uses the SnowballStemmer. I researched it and found out the SnowballStemmer is actually better than the PorterStemmer, so decided to use the SnowballStemmer instead. In case the reader does not know, a stemmer attempts to break a work down to its root for ease of computing word vectors.
I created the program using Kaggle’s free online Jupyter Notebook. The nice thing about Kaggle is the fact that the website stores the code a person writes in a separate file, which can be retrieved at a later time. There are two ways this can be achieved. The reader only needs to go to the dataset or competition in question and all of the notebooks pertaining to that particular dataset can be found in that repository. Secondly, there is a code button on the website and if the reader goes to the code section of the site he can find all of the code he has ever written. It is because I can save my code in the Kaggle website that I write my programs there whenever I am working on a dataset that has been loaded up on Kaggle.
After I created the program, I imported the libraries I would need. NLP needs considerably more libraries than other types of data, and I generally only import these libraries as I need them. The main libraries that I would need for practically any project, however, are pandas, numpy, os, sklearn, matplotlib and seaborn. The libraries that are needed specifically for NLP are re, nltk, string, collections, and itertools:-
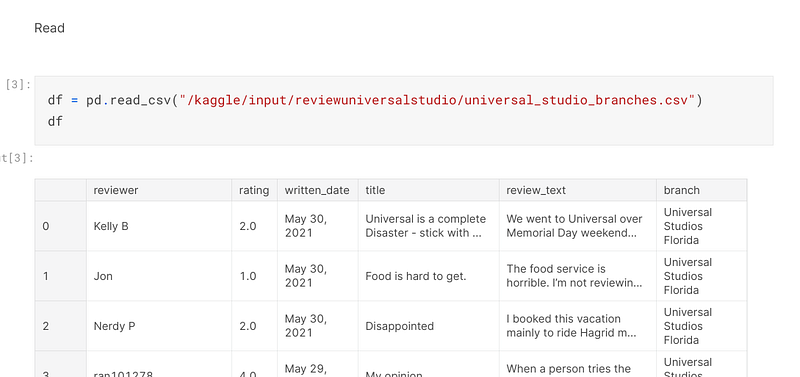
Once the libraries I would need were imported into the program, I read the csv file into it:-
Because this is a project dealing with NLP, I created a new column, test, that was composed of the title and review text:-

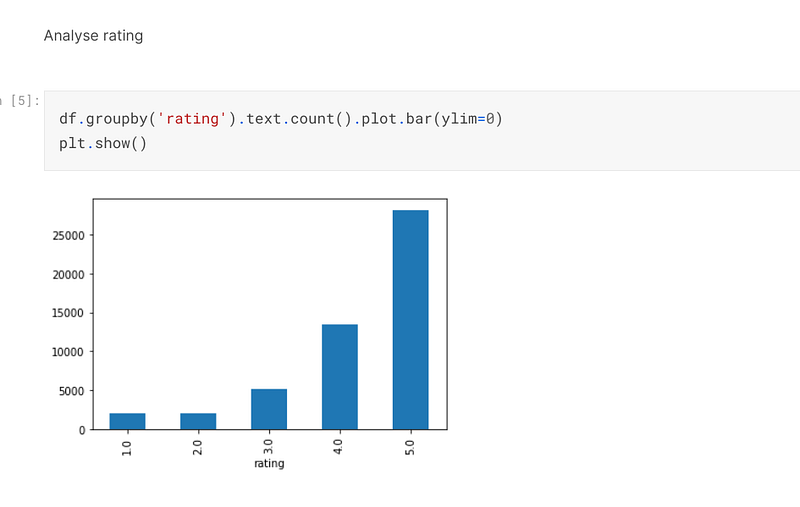
I then analysed the rating, and it can be seen that there is a class imbalance, with most of the reviews being in 4 or 5. I have since researched the matter, and the technique of SMOTE could be used to improve the accuracy of the prediction, so it is certainly worth giving it a try in another project at another time:-
I then began the process of preparing the data for text processing by stemming the words, which is reducing them down to the root word:-
I then carried out further preprocessing of the text by converting the text to lower case, removing punctuation, removing hashtags, and removing all words less than two characters:-

I then inserted code to remove all frequently used words from the text because words that appear often add little meaning to the prediction:-
I then inserted code to remove all rare words from the text because words that appear only once will add little meaning to the prediction:-
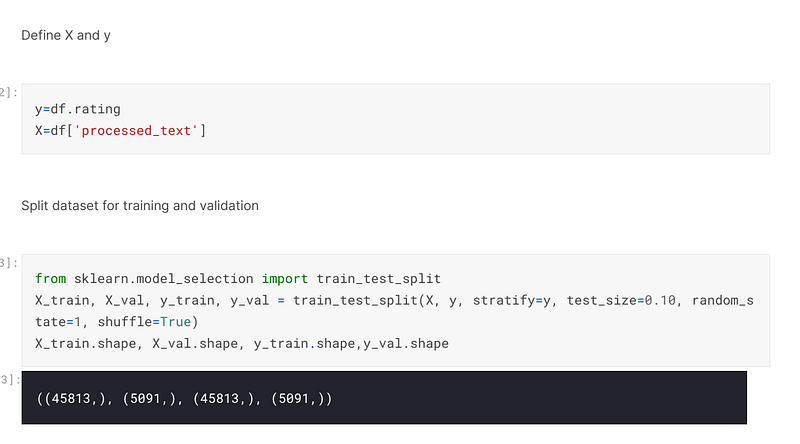
Once the text preprocessing had been accomplished, I defined the independent and dependent variables, which are X and y respectively. The y variable contains the rating column of the dataframe and the X variable contains the processed_text column of the same dataframe. I then used sklearn’s train_test_split to split the dataset up for training and validating:-
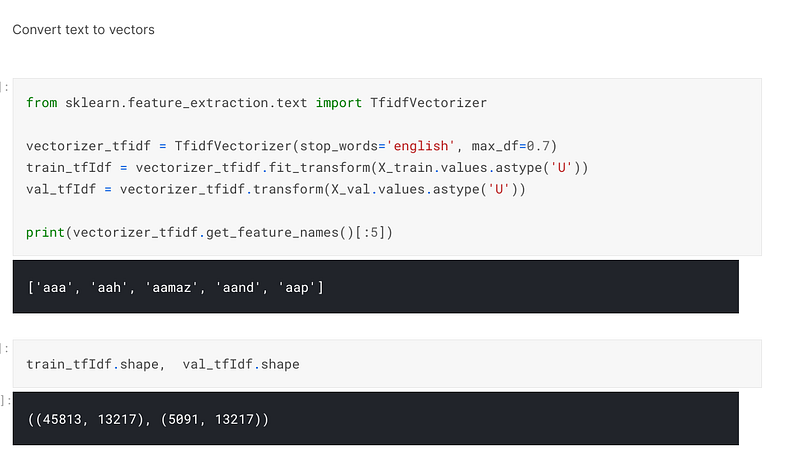
Once the dataset had been split, I used sklearn’s TfudfVectorizer to convert each word into a numerical sequence that will be used to make predictions on the data:-
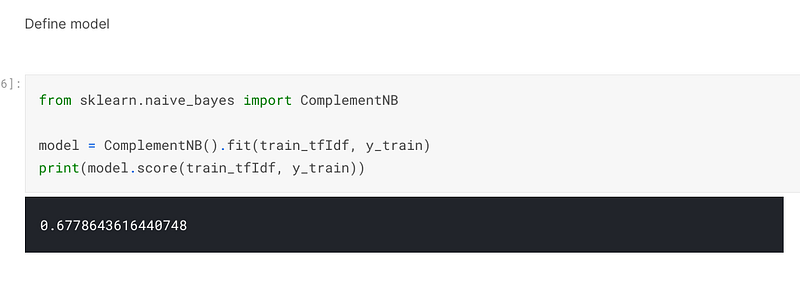
I then defined the model, being sklearn’s ComplementNB, which is part of the Naive Bayes family of estimators. I achieved 67.79% accuracy when I trained and fitted the data into the model:-
I then predicted on the validation set and achieved 59.71% accuracy:-
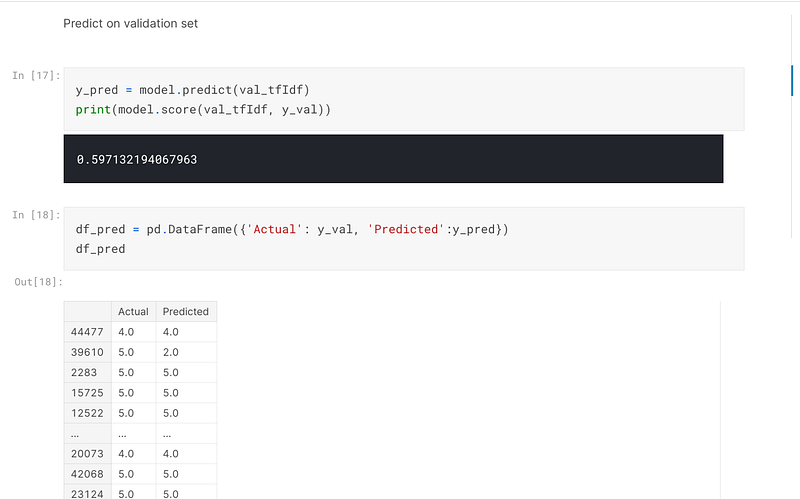
In summary, the accuracy of this dataset was not very high, and there are a few things I could have done to try to improve the accuracy, such as use SMOTE in an attempt to correct the class imbalance. I also could have experimented with different classifiers to try to find one that would give me greater accuracy. And finally, I could have tried to cluster the data to see what the accuracy of the prediction would be in that regard.
The code for this blog post can be found in its entirety in my personal Kaggle account, the link being here:- https://www.kaggle.com/tracyporter/universal-studios-complementnb?scriptVersionId=68866473