
Amazon Has Broken Free Of The Cult Of Encapsulation
So this post has gone viral in developer circles.
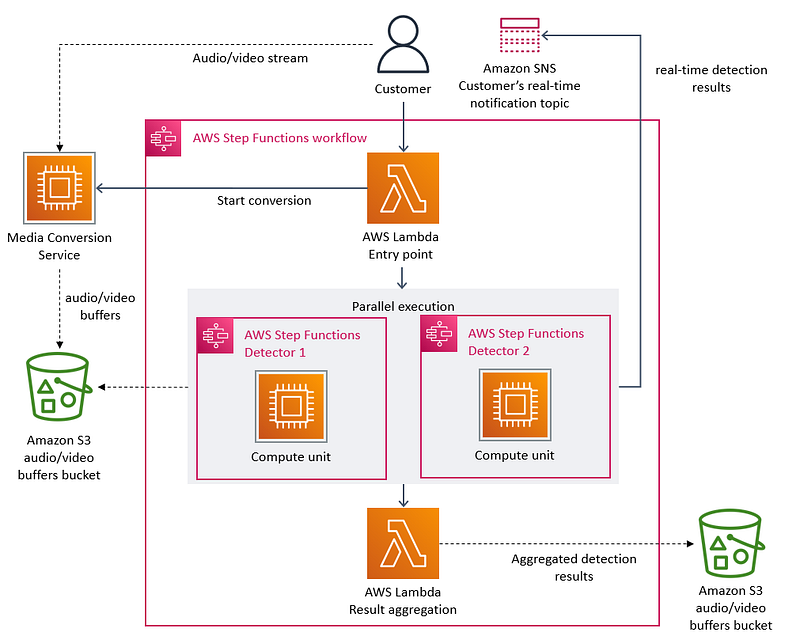
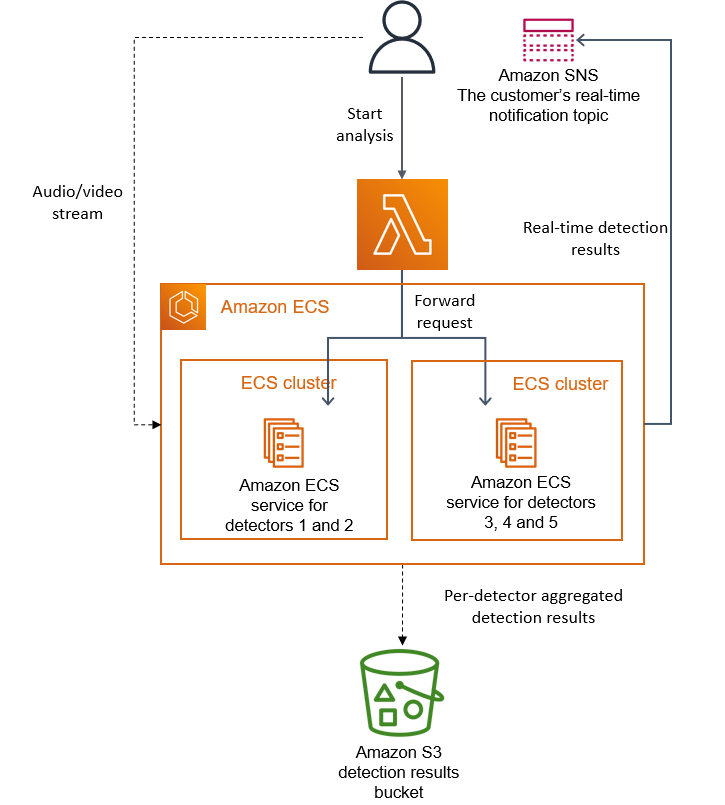
Well, as viral as a post on serverless architecture can go. The article talks about Amazon’s transition from using AWS Lambda communicating with two AWS Step Functions (and a media conversion service) and then back to AWS Lambda to using AWS Lambda communicating with two ECS Clusters.
So they went from this
To this
Not a big change. But apparently this small change had a 90% reduction in costs. I know what you’re thinking: so AWS bills Amazon for their hosting usage? Guess so.
But more importantly it looks like the reason for the ‘90%’ reduction is because Amazon was migrating some old legacy system that were never designed to scale.
Our Video Quality Analysis (VQA) team at Prime Video already owned a tool for audio/video quality inspection, but we never intended nor designed it to run at high scale (our target was to monitor thousands of concurrent streams and grow that number over time). While onboarding more streams to the service, we noticed that running the infrastructure at a high scale was very expensive. We also noticed scaling bottlenecks that prevented us from monitoring thousands of streams. So, we took a step back and revisited the architecture of the existing service, focusing on the cost and scaling bottlenecks.
And they were using a pretty inefficient system.
The main scaling bottleneck in the architecture was the orchestration management that was implemented using AWS Step Functions. Our service performed multiple state transitions for every second of the stream, so we quickly reached account limits. Besides that, AWS Step Functions charges users per state transition.
Multiple state transitions per second. Really? And it gets worse. Amazon was grabbing video frames and sending them to cloud storage.
The second cost problem we discovered was about the way we were passing video frames (images) around different components. To reduce computationally expensive video conversion jobs, we built a microservice that splits videos into frames and temporarily uploads images to an Amazon Simple Storage Service (Amazon S3) bucket. Defect detectors (where each of them also runs as a separate microservice) then download images and processed it concurrently using AWS Lambda. However, the high number of Tier-1 calls to the S3 bucket was expensive.
I mean, you need to do that to test things. But you can see how that can get expensive really fast. So Amazon pivoted from using a microservice approach to a monolith approach.
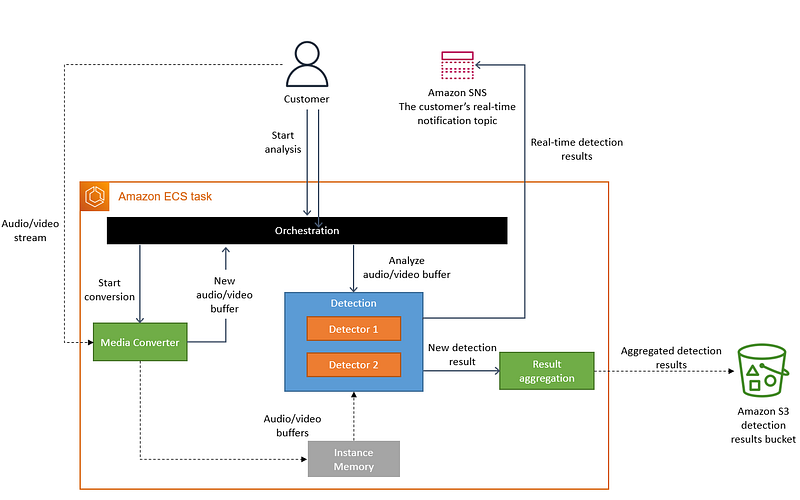
We realized that distributed approach wasn’t bringing a lot of benefits in our specific use case, so we packed all of the components into a single process. This eliminated the need for the S3 bucket as the intermediate storage for video frames because our data transfer now happened in the memory. We also implemented orchestration that controls components within a single instance.
Now you could argue this post is just about upgrading a legacy system. And that was the original plan for this post. I originally wanted to name it, “Well well well, microservices have failed.”

And maybe that would be a better title for this post. But I think Amazon’s experience can tell us much more about programming than ‘upgrade your sh*t!!’.
Microservices Were Flawed From The Start
Let’s begin by asking, “What went wrong in Amazon’s example?” Well the most obvious problem was the very high amount of data going between the various services.
And when I realized this it’s like a lightbulb went off. This is the problem with ‘encapsulation’.
Yeah, sure, if it makes sense, do it. But most of the time it doesn’t make sense and you end up with too many classes constantly ping-ponging data back and forth. This was what happened to me when I tried to implement ‘SRP’. It was a complete debugging nightmare.
And that was on a local system. Amazon is working in the cloud and with ‘microservices’. Now, I’ve read a few takes on the web about this. One clearly written by ChatGPT. But it was pretty convincing. I did not realize it was written by ChatGPT until like halfway through the article. I was like, “Oh yeah, telling the reader what the article is going to be about is a dead ChatGPT giveaway. But humans also do it. I’ll give them the benefit of the doubt.”
Anyways, some people say Amazon wasn’t really using ‘microservices’. But there is very little agreement on what exactly a microservice is. So I’ll just define it here as ‘a component of a serverless architecture that operates as an independent unit and communicates using network calls’.
And network calls are expensive. I should know. I’m using Firebase Firestore. Although for those it’s more the reads and writes that are expensive. But those are simple JSON objects. Amazon was sending screenshots. Probably 4K screenshots, or at least 1080P and they were doing it once per second of video.
Netflix has millions of minutes of video. Amazon probably has a similar amount. So that’s… hundreds of millions of high-quality images. You can see how they had problems. Although a 90% cost reduction is a lot. I guess getting the screenshots must have been a fairly easy process.
Still, 90% of the cost is sending the image? They also mentioned step functions which appears to be some sort of microservice orchestration system. Apparently they had a lot of ‘steps’ or transitions. I guess they had multiple for each second of video. And they also used S3 for an intermediate step in what I can only call, “An incredibly stupid idea for anyone not called Amazon.” I’d suspect this is where the majority of the costs actually went.
Well whatever the case all this encapsulation has blown up in Amazon’s face big time. Because every time you encapsulate some service it has some overhead. Especially on serverless systems.
Conclusion
Amazon’s new system operates entirely in EC2. The way god intended.
This is not to say that splitting services into microservices is always bad. But it usually is, especially with the very high cost of communication on a serverless model.
So what lessons can we draw from this? That apparently Amazon has the need to take a screenshot of every single second of video. Talk about obsessive.
But more importantly whenever you break a system into parts you need to be mindful of the communication costs between the systems.
This differs from some of the previous reasons I’ve disliked an overreliance on encapsulation. That it overly complicates your code and it can make your code unnecessarily complex.
But this is a new reason to dislike encapsulation. That it creates overhead. Switching overhead and communication overhead. And I guess it makes sense in serverless. If you can do everything in one system it’s usually a good idea to do so.
Not always. If Amazon was just sending small JSON messages and not using so many microservices it probably wouldn’t have been a big deal. But then why are you using microservices?
I wouldn’t call microservices a ‘code smell’ because I really hate that term. But it does illustrate a point. The whole point of a microservice is to emulate the service of a component and that means overhead. So they’re sort of a legacy tool. They’re like a, “Yeah, we know it’s inefficient but we don’t have a better way to do it.”
And then one has to wonder: if you can do it without microservices, then what is the point of microservices at all?
If you liked this article consider following me on one of my publications: Lost But Coding (for programming content) or The Rest Of The Story (for everything else). You can do so with my RSS reader available on iOS (and Apple Silicon Macs) and Android.





