
All You Need to Know about Sensitive Data Handling Using Large Language Models
A Step-by-Step Guide to Understand and Implement an LLM-based Sensitive Data Detection Workflow
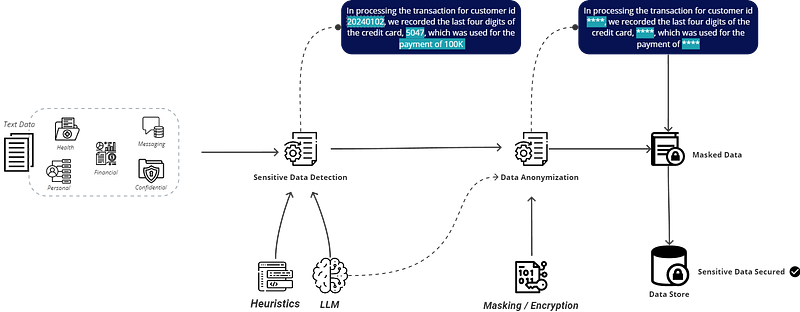
Table of Contents
Introduction
What and who defines the sensitivity of data ? What is data anonymization and pseudonymisation? What is so special about utilizing AI for handling Sensitive Data ?
Hand-On Tutorial — Implementation of an LLM Powered Data Profiler
Local LLM Setup 1. Setting up the model server using Docker 2. Building the Prompt Azure OpenAI Setup
High Level Solution Architecture Conclusion References
An estimated 328.77 million terabytes of data is created daily. Much of that data flows to data-driven applications processing and enriching it every second. The increased adoption and integration of LLMs across mainstream products further intensified the use cases and benefits of utilizing text data.
Organizations processing such data on a large scale face difficulties in adhering to the requirements of sensitive data handling, whether that is regarding its security or compliance with data laws and regulations.
The direct and indirect impact of sensitive data breaches especially when sensitive data is involved can have significant financial consequences on organizations. This extends beyond immediate cost implications but can go to shake the trust and loyalty of their customer base.

What and who defines the sensitivity of data?
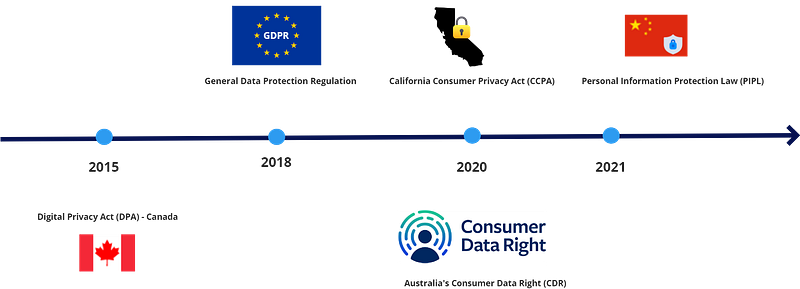
Sensitive data is a critical concept in the context of data protection and privacy. On a high level, sensitive data constitutes information that must be kept confidential and protected against unpermitted access. The importance of sensitive data is highlighted in laws and regulations drafted to secure it, such as the EU’s General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA) and many more across different countries.
Sensitive data includes a wide range of information categories, such as:
- Personal Identifiable Information (General Data Protection Regulation)
- Protected Health Information (Health Insurance Portability and Accountability Act)
- Education Information (Family Educational Rights and Privacy Act)
- Confidential Business Information
- Financial Information
- Employment Information
- Legal Governmental Issued Information
- …
Furthermore, the GDPR specifically states in regards to Personal Identifiable Information (PII) in Article 9 the special categories of sensitive personal data:
- Racial or ethnic origin
- Political opinions
- Religious or philosophical beliefs
- Trade union membership
- Genetic data
- Biometric data
- Health data
- A person’s sex life or sexual orientation
While there exist clear descriptions and boundaries of what sensitive data is according to legal frameworks, depending on the domain or sector an organization is operating in, these could extend to include even more sensitive classified information. This leads organizations to define their custom data confidentiality classifications and integrate them into data sensitivity tools or self-develop custom solutions.
What is data anonymization and pseudonymisation?
Anonymized data is data that cannot be linked to specific individuals, whether by the data itself or through any additional supplementary data. Fully anonymized data no longer falls under the scope of privacy regulations like the GDPR.
Data that can be attributed to a specific individual with additional information, is stated to be pseudonymized. It can be as simple as replacing original data with fake identifiers, which can be mapped back if needed. Encryption, for example, is one method of Data Pseudonymisation.
Data Pseudonymisation is defined within Article 4 of the GDPR:
The processing of personal data in such a manner that the personal data can no longer be attributed to a specific data subject without the use of additional information, provided that such additional information is kept separately and is subject to technical and organisational measures to ensure that the personal data are not attributed to an identified or identifiable natural person.
Data Anonymisation & Pseudonymisation are actions that follow the identification of sensitive data. Whether to anonymize or pseudonymize data depends on the specific use case, and whether it requires reversing the anonymization at some point in the future.
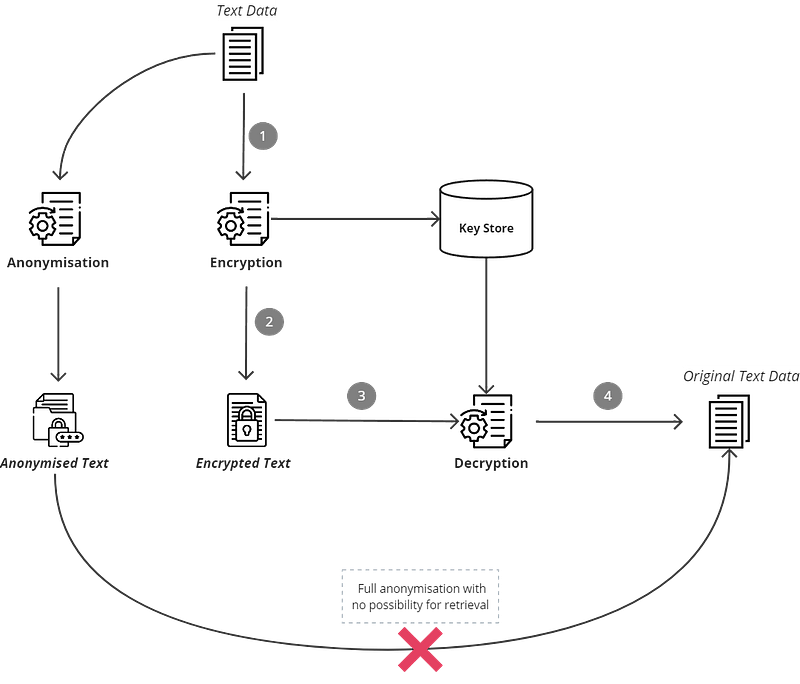
LLMs play a partial role in the context of data anonymization, as they are capable of applying masks on text data but alone without additional complexity, they cannot satisfy all the requirements, specifically those concerning de-identification.
The definitions presented are sufficient to give a short overview as we will reference these terms later in the article. We won’t need to dive deeper into the topic, many articles discuss it in detail, and I explain it on a deeper level in one of my other articles.
What is so special about utilizing AI to handle sensitive data?
Sensitive text data could be indirectly embedded within large text fields and documents making it difficult to detect using heuristic techniques. Such techniques and methods often rely on predefined rules and patterns (e.g. Named Entity Recognition), thus limiting their capabilities.
Often critical sensitive data is not subtly presented within a sentence. Data generated from messaging applications, customer support services, emails, etc.. can potentially contain sensitive data embedded within the context of the entire text. Such a complex setting requires data maskers to remember the parsed text and comprehend the context. This then hinders the usage of heuristic techniques and deems them unfit to satisfy all privacy requirements.

Hand-On Tutorial — Implementation of an LLM-Powered Data Identifier
Given the right prompt, advanced LLM models are capable of using their training data to identify and mask sensitive data within a sentence. For our example, we will test setting up a data sensitivity identifier using Llama2 Model and Azure’s GPT4 Model. LangChain framework will be used to retrieve and prompt the models.
We’ll start by setting up the environment that will be used to load the models and the Python script to run the application.
To do this, first ensure that Python 3.8 or higher is installed.
Local LLM Setup
This section will list the needed steps to prepare the environment and run a local Llama2 model for data sensitivity detection.
1. Setting up the model server using Docker
We will use Docker to set up our model server which LangChain can communicate with. Other methods are available to set up the model locally, you can find more here.
Ensure first that Docker is installed and running, then run the following command to download the image and set up the model server.
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
To make sure that the server is up and running, open the link http://localhost:11434 and the sentence “Ollama is running” should appear in your browser.
Once the container is up and running, install the model. If you’re interested in testing different models, check out the list here.
docker exec -it ollama ollama run llama2After the installation is completed, we will load the model and set up the Python script.
Let’s first install LangChain
pip install langchain pip install langchain-community
Import the needed packages in the script.
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_community.llms import OllamaLoad the model
llm = Ollama(model="llama2")2. Building the prompt
Considering that the LLM is already equipped with comprehending the embedded context of a sentence, it is important to formulate the prompt in a way that guarantees that the task is executed as intended.
For our example, the LLM should ensure the following:
- The capability of identifying sensitive information without solely relying on keyword matching but with an understanding of the context.
- * Detection should conform to the data protection laws and regulations (GDPR, CCPA, etc..)
- Ensure that the model balances between precision and recall
- Ensure that the sentence structure is not altered and that only detected sections are handled.
- Ensure that only data provided is returned with no additional content.
template = """
You are a sensitive data identifier and masker.
You are capable of identifying sensitive information in text and applying a mask using "****".
Sensitive data can also be embedded in the context of the text and is not always explicitly mentioned (such as topics about health, financials, addresses, .. )
Ensure that Personall identifiable data is detected and masked.
Ensure that the detection takes into account the data protection laws and regulations like GDPR, CCPA, and HIPA
Ensure that the input text is not altered or changed in any way and just mask the detected sensitive information.
Ensure high confidence in the information you mask.
The content returned should not include anything other than the text input with the required masking applied.
If no sensitive text is detected, return the input as is with no additional content.
The sentence:
{sentence}
"""
output_parser = StrOutputParser()
# Setup the prompt
prompt = PromptTemplate.from_template(template)
# Create the Chain
chain = prompt | llm | output_parser
The prompt formulates the requirements needed to ensure the model runs the task successfully as instructed. Additional parameterization on specific requirements can be added like
- * * Specifying which laws to adhere to is important depending on the country of origin.
- The confidence to operate with when masking sensitive data
Let’s run the first example
sentence = """
Last week, while discussing our summer plans,
Mike hinted he's finally taking that solo trip to Bali
he saved up for, after his bonus came through.
He received more than 10K as bonus
"""
# Run the detection
response = chain.invoke({'sentence':sentence})
# Print the final response
print(response)
The response from the Llama2 model was capable of identifying sensitive data and masking it as instructed. All names were masked, in addition to the word “bonus” and the amount, indicating that the model was able to detect that the number was linked to sensitive financial information.
Notes
* As data protection laws and regulations are updated regularly, the model will not have access to the latest versions.
** The application can be adapted to utilize RAG (Retrieval-Augmented Generation) to run on specific versions of provided laws and regulations documents.
Azure OpenAI Setup
Using Azure OpenAI’s GPT4 Model requires creating an Azure OpenAI Service. Microsoft provides a clear documentation on steps to create the resource here.
After creating the resource, we navigate to Deployment and deploy a gpt4 Model with the default version.
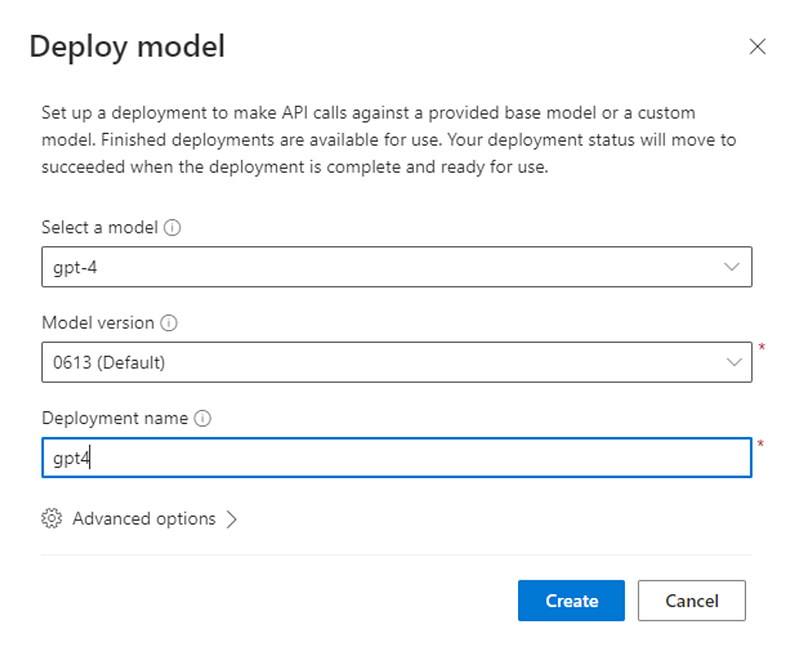
Once the model is successfully deployed, make sure to retrieve the Azure OpenAI Key used to access the API.
Let’s Install the required LangChain package to work with Azure OpenAI
pip install langchain-openai
We follow the same steps as when building the local setup, with a few adjustments to the imports and prompt template used to work with Azure OpenAI.
import os
from langchain_openai import AzureChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
# Add the required environmental variables
os.environ["OPENAI_API_VERSION"] = <API VERSION>
os.environ["AZURE_OPENAI_API_KEY"] = <Your AZURE OPENAI KEY>
os.environ["AZURE_OPENAI_ENDPOINT"] = <Your AZURE OPENAI ENDPOINT>
# Define the prompt template
template = """
You are a sensitive data identifier and masker.
You are capable of identifying sensitive information in text and applying a mask using "****".
Sensitive data can also be embedded in the context of the text and is not always explicitly mentioned (such as topics about health, financials, addresses, .. )
Ensure that Personal identifiable data is detected and masked.
Ensure that the detection takes into account the data protection laws and regulations like GDPR, CCPA, and HIPA
Ensure that the input text is not altered or changed in any way and just mask the detected sensitive information.
Ensure high confidence in the information you mask.
The content returned should not include anything other than the text input with the required masking applied.
If no sensitive text is detected, return the input as is with no additional content.
The sentence:
{sentence}
"""
prompt = ChatPromptTemplate.from_template(template)
# Select the model
llm = AzureChatOpenAI(
azure_deployment="gpt4",
)
# Setup the Chain
chain = prompt | llm
sentence = """
Last week, while discussing our summer plans,
Mike hinted he's finally taking that solo trip to Bali
he saved up for, after his bonus came through.
He received more than 10K as bonus
"""
# Run the LLM
response = chain.invoke({'sentence':sentence})
print(response.content)
After testing the prompt 3 times, the output still shows that the model identified sensitive information and masked it where needed, without altering the sentence’s content.
Let’s try using another example:
sentence = """
During our call with Emma, she casually mentioned that
she's moving because her rent is going up to $3000 next month.
I noticed that she kept this detail private.
It could be due to having some financial concerns.
"""
Both models were able to accurately identify sensitive data within the examples provided, nonetheless this only included examples with relatively short text. Longer texts might have more impact on the results, especially when sensitive data is revealed much later in a longer text, where the model could miss the link between a number and the context it was used in.
The next section will discuss a high-level hybrid solution approach that uses both heuristics and LLMs in sensitivity detection.
High-Level Solution Architecture
Developing an efficient and reliable sensitive data identification LLM application is already a milestone. However, the positioning of such an application in a Data Architecture should be carefully evaluated. Organizations with large volume and velocity of text data could end up incurring enormous costs and effort, rendering their solution inefficient.
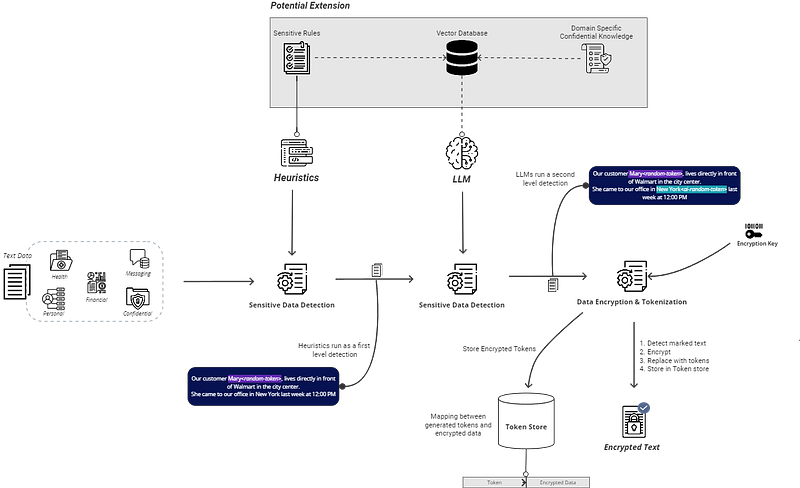
The diagram shows step-by-step how text data is processed at each stage by different components to achieve a fully compliant data state.
Some important questions to take into account when building such solutions:
- Does the use case justify the overhead of deploying and maintaining an LLM? Are heuristic techniques sufficient?
- Are there existing solutions in the market for the use case ?
- Will the latency and availability requirements of the data be met?
- Does the data comes with sensitive data embedded in its context?
Conclusion
Utilizing existing heuristic approaches can indeed support detecting sensitive data, however, in situations where sensitive data appears indirectly within the context of the sentence, it becomes difficult to detect by standard methods. LLMs with their build-in capabilities in comprehending large amount of text can serve as the next generation tools for tackling the issue of sensitive data detection and classification.
In this article, we showed examples of how LLMs can be prompted to target the issue. The prompts in the examples listed proved that LLMs are capable of satisfying the general requirements of the task. Introducing hybrid approaches between heuristics and LLMs, as shown in the data solution architecture, could potentially ensure better results and provide additional safeguards. The article showed a sneak peek on the possibilities of using LLMs for handling sensitive data, some additional use cases and possibilities include:
- Incorporating data catalog metadata to be used in RAG for LLMs
- Introducing classifications on sensitivity levels
- Integration of domain-specific sensitive data knowledge
- …
Enjoyed the Story ?
If you’re interested in more detailed architectures for sensitive data handling — feel free to check out my other articles here
References
Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation) (Text with EEA relevance). Available at: General Data Protection Regulation (GDPR) — Official Legal Text (gdpr-info.eu)
Cost of a data breach 2023 IBM. Available at: https://www.ibm.com/security/data-breach (Accessed: 1 March 2024).
LangChain, https://www.langchain.com
California Consumer Privacy Act (CCPA). State of California — Department of Justice — Office of the Attorney General. (2024, March 13). https://oag.ca.gov/privacy/ccpa
Taylor, P. (2023, November 16). Data Growth Worldwide 2010–2025. Statista. https://www.statista.com/statistics/871513/worldwide-data-created/




