
All You Need To Know About ByteTrack Tracker

The purpose of this post is to give you knowledge about the BYTE method and ByteTrack tracking by examining research mostly from their academic paper. This post can be a useful guide and reference for your next research in case of the need for usage tracking algorithms.
- Key technical details about the ByteTrack have been detailed below. Also, demo results and implementation details about the tracker can be found at the end.
Object Trackers
There are different state-of-the-art object tracking methods in the computer vision area. We can list some of these well-known state-of-the-art methods which are also mentioned in the ByteTrack paper as:
● JDE
● CSTrack
● FairMOT
● TraDes
● QuasiDense
● CenterTrack
● CTracker
● TransTrack
● MOTR
These methods use different techniques for tracking. Most of them offer their own technical solution for object tracking challenges caused by real-life scenarios like occlusion of objects or fast-moving objects in videos.
Among these nine trackers mentioned above, JDE, CSTrack, FairMOT, and TraDes adopt a combination of motion and Re-ID similarity techniques.
- QDTrack adopts Re-ID similarity alone.
- CenterTrack and TraDes predict the motion similarity by the learned networks.
- Chained-Tracker adopts the chain structure and outputs the results of two consecutive frames simultaneously and associates them in the same frame by IoU.
- TransTrack and MOTR adopt the attention mechanism to propagate boxes among frames.
ByteTrack
● Most multi-object trackers use detection for tracking. However, the confidence score of object detection boxes causes true positive/false positive trade-off in detection. Most of the algorithms eliminate detection boxes by using a threshold to increase true positives, but it also causes false-positive results.
● For object tracking tasks, eliminating boxes with low confidence scores may decrease the tracking performance. These algorithms simply remove true objects in the point of detection model and it causes missing detections and fragmented trajectories.
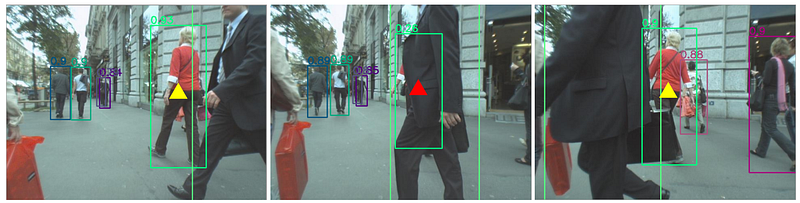
● We should not forget that low score detection boxes can indicate existing objects. You can see an example image shown in Figure(a).
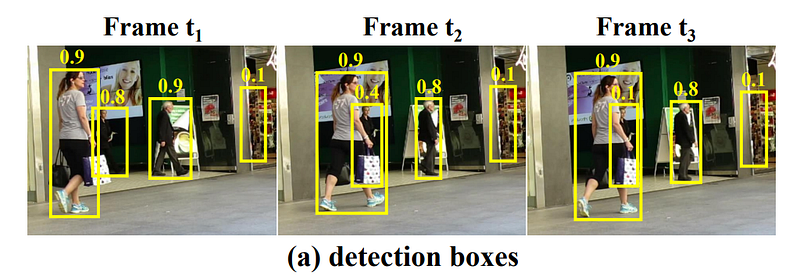
- The authors of this study propose a solution method for this problem by associating almost every detection box instead of ignoring low score ones. Their method is actually based on the junction area of detection and data association. This data association method is called BYTE. This association is a matching process by examining similarities with tracklets.
- They keep almost every detection box, unlike most the trackers. After that these boxes are separated into low and high score ones. Then, Kalman Filter is used to predicting the new locations of the current frame.
You can see the tracker differences in Figures (b) and (c). The dashed boxes represent the predicted box of the previous tracklets using the Kalman Filter.

- After using Kalman Filter, predicted tracklets and high score detections are matched by calculating the motion similarity score. This score is computed by IoU in the first association process.
- Then, the second association process is started consecutively by using unmatched tracklets and low score bounding boxes.
More detail about the algorithm can be found in the paper.
- This method is also applied to the nine different state-of-the-art trackers including Re-ID based ones, chain-based one, and attention-based ones. It achieved consistent improvement on IDF1 score ranging from 1 to 10 points on these trackers.
- Creators of BYTE have adopted their method on the bounding box of objects detected by YOLOX and created a simple and strong ByteTrack tracker.
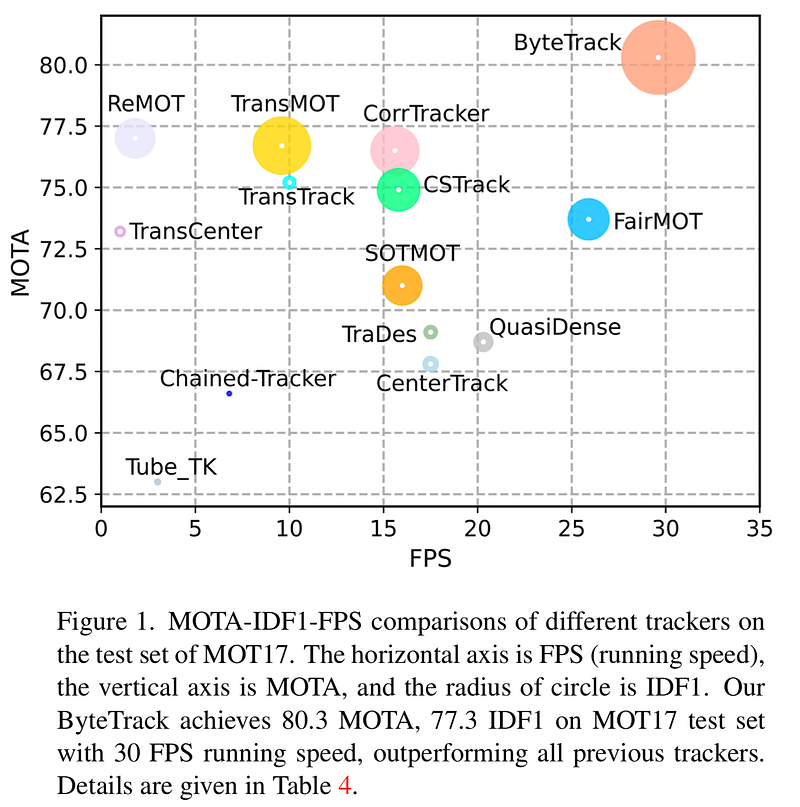
- The performance of ByteTrack is also impressive. It achieved 80.3 MOTA, 77.3 IDF1, and 63.1 HOTA on the test set of MOT17 with a 30 FPS running speed on a single V100 GPU.
- It also achieved state-of-the-art performance on MOT20, HiEve, and BDD100K tracking benchmarks.
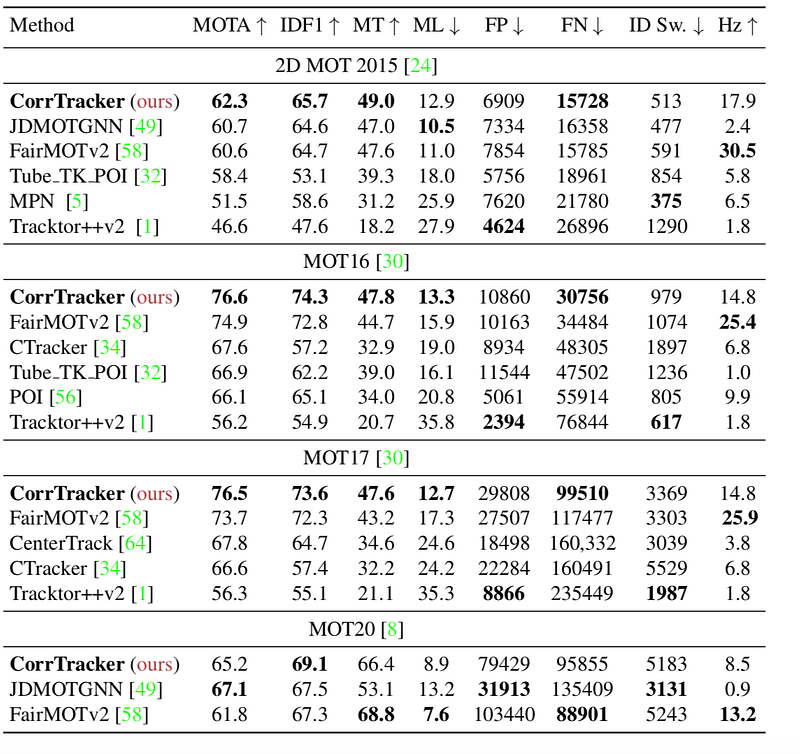
Some of the performance result comparisons can be viewed below.
Results and Code Implementations
- Sample detection results on the well-known dataset MOT17 in below.

- You can see the image demo result obtained from Hugging Face below.
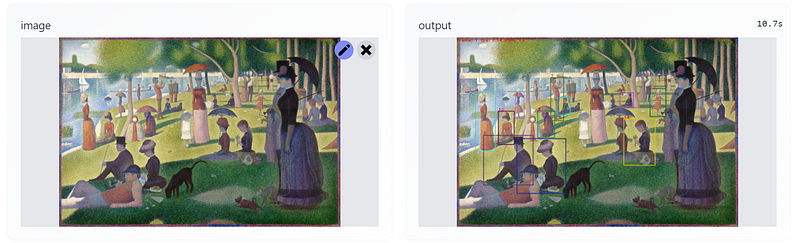
- You can check the video demo result from the google drive link below.
- You can examine the custom training implementation process in this notebook implemented by me. It also includes the implementation part for the video demo provided by one of the ByteTrack paper authors.
More Information and Resources
- For more information about ByteTrack, you can check their paper.
- It includes all the details about their techniques, algorithm, experiments, and comparison of performance results with other state-of-the-art methods.
- You can also check their GitHub repository for more details about implementation. Demo implementation on Colab can be found in there
Thank you for reading! If there are any points you think that I missed or any criticism, I would like to receive them.
About me
- I am a Machine Learning Engineer at Neosperience. I’m pursuing a Master’s degree in Data Science at Universita di Pavia.
- You can connect with me on Linkedin





