
AI Writes Prize-Winning Sci-Fi Novel In Chinese: 人工智慧用中文寫獲獎科幻小說
A Professor of Journalism at Beijing’s Tsingua University experimented — and the winning result is causing concern; it’s a problem for me too, trying to grasp the idea of it being a threat to the language when written and spoken Chinese are conceptually different
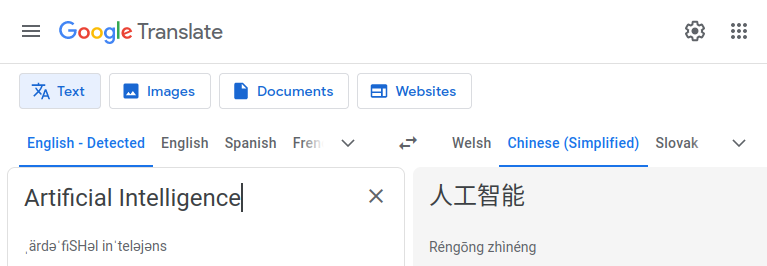
The headline to this story is written in English and what Google Translate says is Chinese (simplified). Simplified? I looked initially at the list of languages offered, searching for Mandarin or Cantonese knowing that these were the two most common forms of the Chinese language. No luck. I should have remembered that the spoken is not the written when it comes to these languages. Kudos to Medium for being able to let me paste it in directly as characters and not as a screen grab.
Every picture tells a story, and that’s my basic understanding of how pictographic languages work. The world of languages, such as English, in which the written word closely matches the spoken word is surprisingly complex. But that’s not Chinese, simplified or not.
Almost 6,000-characters in length, the Chinese-language novel Land of Memories, by Shen Yang, was among the winners of the Jiangsu Youth Popular Science Science Fiction Competition, Jinan Times, a newspaper in Shandong province reported. (South China Morning Post)
Continuing:
Shen crafted the sci-fi narrative from a draft of 43,000 characters generated in just three hours with 66 prompts. The unique storyline set the scene with the first three lines, all generated by AI:
“In the metaverse’s edge, lies the ‘Land of Memories’, a forbidden realm where humans are barred. Solid illusions crafted by amnesiac humanoid robots and AI that had lost memories populate its domain.
One judge said he did not vote for the submission because it was not up to standard and “lacked emotion” and another recognised that it was generated by AI.
As so often happens when I’m writing this story led me down a rabbit hole about the classification of languages. My background is in science not the arts although these days I obviously do try to write. When digging into the difference between what I thought was a pictographic language (a term that popped out of my brain from goodness knows where) and say, a written language like English a hole turned into a warren.
I discovered that Chinese writing is not strictly a pictographic language, although it has historical roots in pictographs. Modern Chinese characters, known as hanzi, are considered morpho-syllabic. This means they represent both meaning (morpheme) and sound (syllable).
Pictographs directly represent objects or concepts visually, like ancient Egyptian hieroglyphs.

Yes, I was way out in thinking that Chinese is pictographic, but while some early Chinese characters originated from pictographs, they have evolved significantly and no longer directly depict their meanings.
Morpho-syllabic characters combine semantic components representing meaning with phonetic components indicating pronunciation. This system allows for a diverse range of meanings and pronunciations while retaining some connection to their ancestral pictographic forms. I’m struggling to get my head around this.
Therefore, while Chinese writing shares some historical aspects with pictographs, its contemporary form operates on a more complex system that incorporates both meaning and sound. This makes it distinct from pure pictographic languages and closer to other systems like Japanese kanji or Korean hanja.
Chinese (simplified) for everyday communication and basic literacy, has about 3,500 characters, but for broader understanding and advanced learning, about 6,700 characters are available. Imagine learning all that.
Apparently there are several terms used to describe languages where the written word closely matches the spoken word, as opposed to pictographic languages, but that is out of the scope for this musing. However, I’ll just point out that English borrows heavily from many languages and so its pronunciation is tricky for learners. It’s classified as exhibiting ‘deep orthography’ meaning that pronunciation cannot easily be predicted from spelling.
My second (almost) language is Welsh and Welsh is actually quite a close match in pronunciation to its written form. It borrows heavily from English, unfortunately, as you can see in this translation:
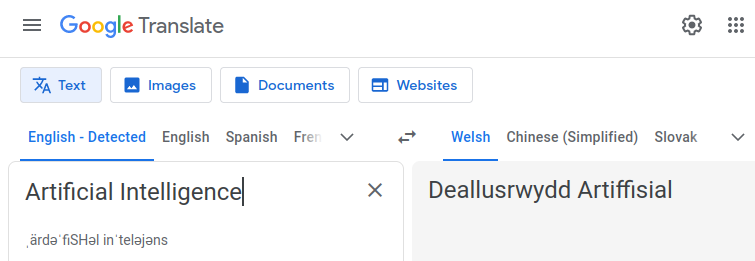
The double ‘l’ is one of the most difficult sounds for non-native speakers to master.
Thinking about it now, I wonder how Chinese speakers and readers ‘get the word’ when they read. Do they have to do a mental translation of the image or do they just have a mental ‘lookup table’?
Back to AI novels
The AI generated prize-winning sci-fi novel had 6,000 characters. It seems that depending on ‘equivalence ratios’ which are a moveable feast, 6,000 characters is about 6,000 English words. That doesn’t seem like novel length to me, it’s more like a short story. I checked with Bard and the ‘opinion’ was that the 6,000 hanzi was an extract from a novel, which would seem to make more sense.
Shen crafted the sci-fi narrative from a draft of 43,000 characters generated in just three hours with 66 prompts. (SCMP ibid.)
43,000 reduced to 6,000? The character count/numbers don’t stack up for me, but that’s not really the point.
Copyright
One of the emerging problems with AI generated content is the question of copyright. This is more a problem for images and music, but whole novels are being absorbed by AI in its training processes. There is serious litigation afoot with the New York Times, which is suing OpenAI (ChatGPT) for copyright infringement.
Expert commentary is suggest that this could put the whole AI industry in serious jeopardy.
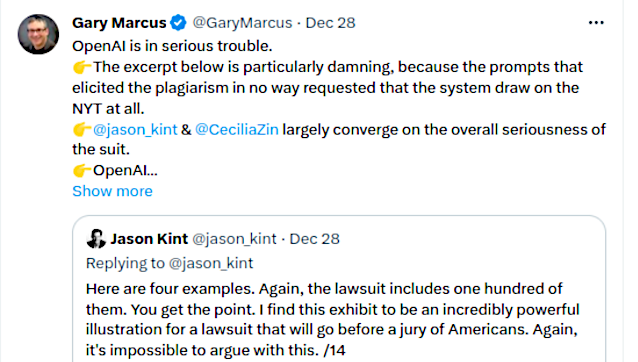

That seems straightforward but what happens if the text (novel) is written in Chinese? Would the alleged plagiarism be character by character matching?
And does software such as ChatGPT, when drafting a novel in Chinese, access what it has learned from English texts? In other words, is all training input, in whatever language, translated into a common language for its internal ‘storage’? I’m thinking here about the possibility of cross-language plagiarism’.
Artwork such as painting is in one ‘language’ only and ‘plagiarism’ is obvious. But what if a Chinese novel is not translated into, say English; it’s read in the original Chinese and used as the basis for an AI-generated novel in English?
That’s a raft of puzzles I’ll leave for another day.




