
AI Landscape in 2023
Takeaways from AI Hardware & Edge AI Summit

AI Hardware & Edge AI Summit was held during September 12–14, 2023, at Santa Clara Marriott, CA. It has been a year since last summit. What’s novel at today’s AI horizon?
Here is a list of what we have learned from the conference:
This decade is for generative AI
AI copilots are flourishing
Open ecosystem accelerates AI development
Chiplets can bring down the cost of LLMs
Edge-based LLM inferencing is coming
Hybrid AI between edge device and central cloud
Distributed training improves both the memory and compute efficiency
We are seeing glimpses of the future with generative AIThis decade is for generative AI
Dr. Andrew Ng, a globally recognized leader in AI, opened the conference with his keynote speech, Opportunities in AI. He has announced that this decade is for generative AI.
Generative AI is a type of artificial intelligence technology that can produce various types of content, including text, images, images and other media, using generative models. These models learn the patterns and structure of their input training data and then generate new data that has similar characteristics.
Traditionally, supervised learning takes months to train and deploy (run) models, but generative AI responses to a prompt in minutes.
The following is AI stack, where many application startups are exploring various AI products:

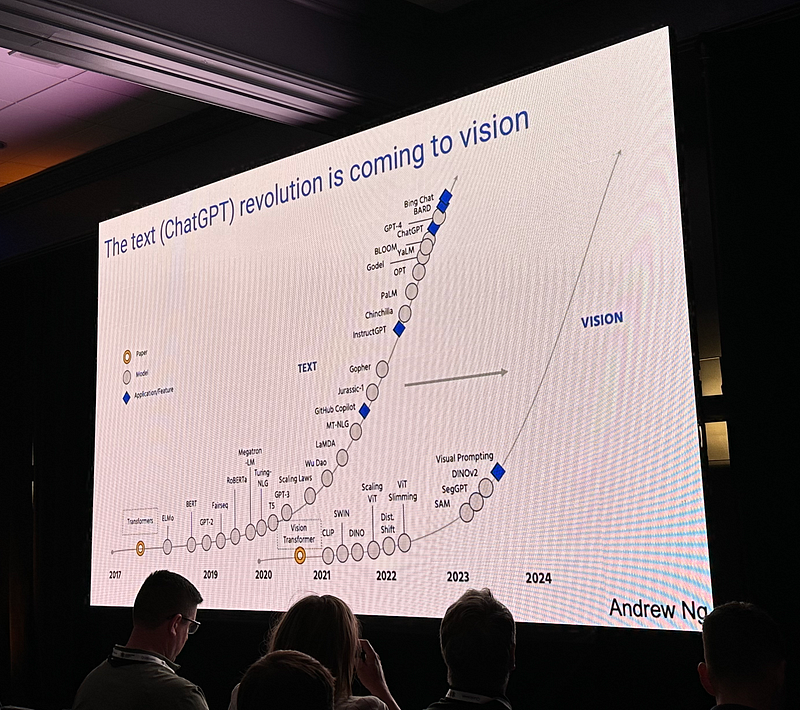
Text prompting has transformed text processing (NLP), and the text (ChatGPT) revolution is coming to vision.
In addition, AI for smell and AI for touch are emerging.
AI copilots are flourishing
A transformer is a deep learning architecture that relies on the parallel multi-head attention mechanism. The modern transformer was proposed by the paper, Attention Is All You Need, in 2017 by the Google Brain team. It notably requires less training time than previous recurrent neural architectures.
A later variation of transformer has been prevalently adopted for training Large language models (LLMs) on large (language) datasets. LLMs are trained by complex neural networks and capable of understanding and generating human language.
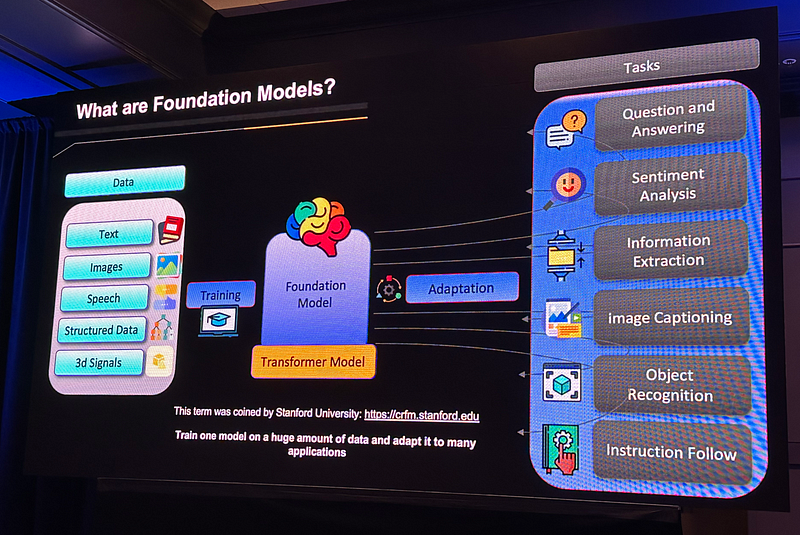
Foundation models refer to AI systems with broad capabilities that can be adapted to a range of different, more specific purposed usages. They are different from many other AI systems that are specifically trained and then used for a particular purpose.
LLMs, including ChatGPT, are examples of foundation models. Nowadays, foundation models are often used synonymously as LLMs.
The following slide illustrates the definition of foundation models:
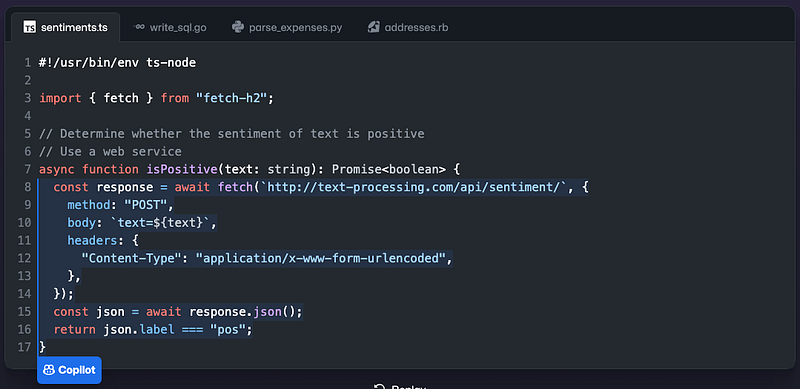
AI copilots are generative AI assistants that are built upon LLMs. They automate tasks and generate content. Copilot-powered systems can be operated by natural languages. For example, the following GitHub Copilot turns a comment into the actual code in TypeScript:
Copilot-powered systems enhance the productivity and provide better user experience. Microsoft has a full list of copilot product family.

Open ecosystem accelerates AI development
There is open-source momentum in AI development. The collaborated work brings us AI tools and frameworks.
- TensorFlow is an open-source ML library, which can be used across a range of tasks with a particular focus on training and inference of deep neural networks.
- TensorRT-LLM is a collaboration among Meta, NVIDIA, and others to accelerate and optimize LLM inference on H100 GPUs.
- PyTorch is an open-source ML framework that offers flexible and efficient deep learning model development.
- PyTorch Lightning is an open-source library that provides a high-level interface for PyTorch.
- ONNX is an open-source AI ecosystem that promotes innovation and collaboration in the AI sector.
- OpenAI Triton is a high-performance programming language that enables researchers to write highly-efficient GPU code.
- AITemplate is a unified inference engine for GPUs that delivers near hardware-native performance on a variety of models.
- Microsoft DeepSpeed is a deep learning optimization library that makes distributed training and inference easy, efficient, and effective.
- Google JAX is a machine learning framework for transforming numerical functions.
- Hugging Face is an open-source and platform provider of machine learning technologies. It hosts more than 330k open-source models.
Chiplets can bring down the cost of LLMs
A chiplet is a tiny integrated circuit (IC) that contains a well-defined subset of functionality. It is designed to be combined with other chiplets on an interposer in a single package. A set of chiplets can be implemented in a mix-and-match “Lego-like” assembly.
The concept of chiplets in hardware is similar to microservices and micro frontends in software.
Models are getting larger, needing more computation. From GPT-4 to the recent Large Language Model Meta AI (LLaMA), various LLMs are rapidly developed and serviced. LLaMA is a family of large language models (LLMs), released by Meta AI starting in February 2023. In July 2023, Meta released several models as Llama 2, using 7, 13 and 70 billion parameters.
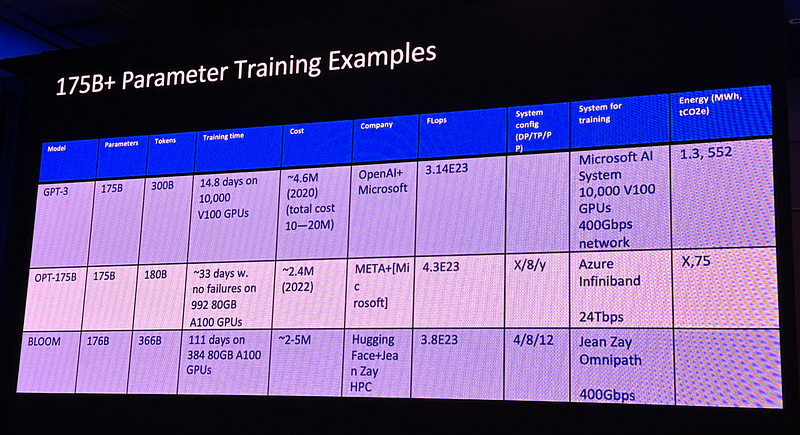
Large computation needs large scale chips. Chiplets can be used in heterogenous integration, through mixed, matched, and reused, to bring down the cost of LLMs.
Edge-based LLM inferencing is coming
Edge ML is localized processing on edge devices. It minimizes latency, reduces data transfer, and ensures privacy. It allows real-time decision making, and enables functionality in remote or offline environments. However, edge devices have low power, low processing capability, and low bandwidth.
Cloud-based ML is centralized processing on remote servers. It offers scalability but may introduce network delays and data security concerns.
LLMs are located at cloud today, but it needs to be moved to edge to be closer to the source of data. Edge devices need more power, storage, and processing capability to enable real-time analysis and decision-making.
Edge-based LLM inferencing is coming. It can be used in many use cases:
- It enables new and unique experiences that drive purchase decision, not possible today, such as AI personal assistant.
- It enables content creation for productivity applications, search, education chatbots, as well as code generation.
- It drives policy with multi-model inputs, in-cockpit conversational AI.
- It creates virtual and augmented worlds with digital twins capable of operating autonomously in the absence of human.
- It enables large models to provide domain specific NLP capable assistants for healthcare, finance, and many fields.

Hybrid AI between edge device and central cloud
LLMs are challenging for edge device that do not have power of compute, bandwidth, and memory with sustained performance. Hybrid AI between edge device and central cloud could be a solution.

- LLMs are memory-bound and produce a single token per inference, reading in all the weights.
- The smaller draft model runs on edge device, sequentially.
- The larger target model runs on the cloud, in parallel and speculatively.
- The good tokens are accepted.
- Results in net speedup in tokens per unit time and energy savings.
Distributed training improves both the memory and compute efficiency
Microsoft DeepSpeed is a deep learning optimization library that makes distributed training and inference easy, efficient, and effective.

Data parallelism uses the same model for every thread, but feed it with different parts of the data. DeepSpeed leverages the aggregate computation and memory resources of data parallelism to reduce the memory and compute requirements of each device (GPU) used for model training.
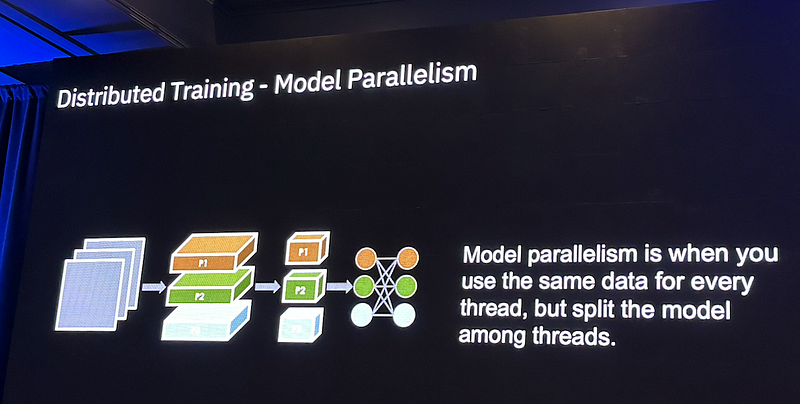
Model parallelism uses the same data for every thread, but split the model among threads. DeepSpeed reduces the memory consumption of each GPU by partitioning the various model training states (weights, gradients, and optimizer states) across the available devices (GPUs and CPUs) in the distributed training hardware.
DeepSpeed even supports for pipeline parallelism, which improves both the memory and compute efficiency of deep learning training by partitioning the layers of a model into stages that can be processed in parallel.
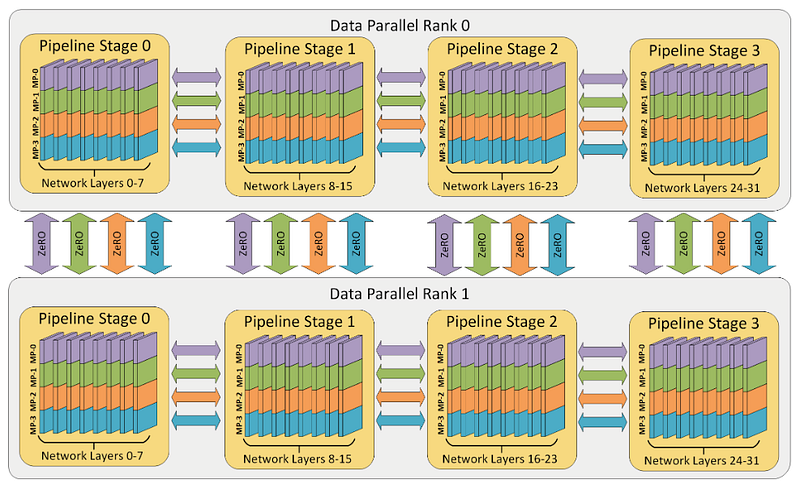
We are seeing glimpses of the future with generative AI

It is the tipping point for generative AI. We are seeing glimpses of the future with generative AI:
- Continued advances will bring similar leaps with multi-modal, real-time generation of text, images, audio, and video. All on the path to AI: an autonomous agent that can learn and perform skills exceeding that of most people.
- Generative AI is dramatically changing the landscape of gaming, medical, automotive, legal, financial, and education.
- The demand for ML compute is growing exponentially. Quality continues to improve with number of dense parameters for foundation models.
- There are profound societal implications. Our technology must flexibly support a rapidly evolving understanding of the trust, safety, privacy, and responsibility landscape.
Conclusion
The three-day summit finished. Compared to last year’s summit, the conference is more focused on generative AI and LLMs. We are seeing glimpses of the future with Generative AI. Software becomes more important in the hardware industry, and AI beyond text prompt is emerging.
Thanks for reading.
Want to Connect?
If you are interested, check out my directory of web development articles.Notes:
- Thanks to Kisaco Research for inviting me to the summit to meet AI experts and exchange ideas for future AI development.
- Thanks to many speakers for providing content for this article.
- Thanks to many booths that showed me great AI products in the works.
In Plain English
Thank you for being a part of our community! Before you go:
- Be sure to clap and follow the writer! 👏
- You can find even more content at PlainEnglish.io 🚀
- Sign up for our free weekly newsletter. 🗞️
- Follow us on Twitter(X), LinkedIn, YouTube, and Discord.