
Machine Learning Art
AI editing of objects in videos
stylizing objects in videos using a text

What is editing videos with AI?
AI-powered video editors can change your work to make it faster and easier. It also automates most of the tasks that don’t need much attention. It has done a minor job for people, so we now have more time to do more important things.
- June 2022 — AI art tools update can be found ➡️ HERE ⬅️
Can you edit out objects in videos?
Using human instructions to move semantic object entities in videos requires skilled workers who know the domain. We want to eliminate these requirements by letting the user specify a desired edit or style through a text prompt that is easy, intuitive, and makes sense. But manipulating video content in a way that makes sense is hard. One of the challenges is coming up with consistent content or style changes on time that meets the requirements of the target text. Another challenge is changing an object’s content to keep the original video’s content and global meaning while keeping the fine-grained details of the target text.
Text Styling of Video Objects
The authors try to style video objects in a way that is easy to understand and makes sense, based on a text prompt from the user. This is a difficult task because the resulting video must meet many requirements. For example, it must be consistent in time and avoid jittering or other artifacts. In addition, its stylization must keep both the big picture meaning of the object and its small details. And it must follow the user-specified text prompt.
Project Page (scroll down)

To do this, their method styles an object in a video based on a global target text prompt that describes the global semantics and a local target text prompt that represents the local semantics. To change the style of an object, they use the representational power of CLIP to get a similarity score between the local target text and a set of stylized local views and a global target text and a set of stylized global views.

The authors use an atlas decomposition network that has already been trained to spread the changes in a way that is consistent with time. They show that a new method can change the style of different objects and videos over time to match the target texts’ requirements. They also show how different levels of detail can be achieved by changing how specific the target texts are and adding a set of prefixes to them.
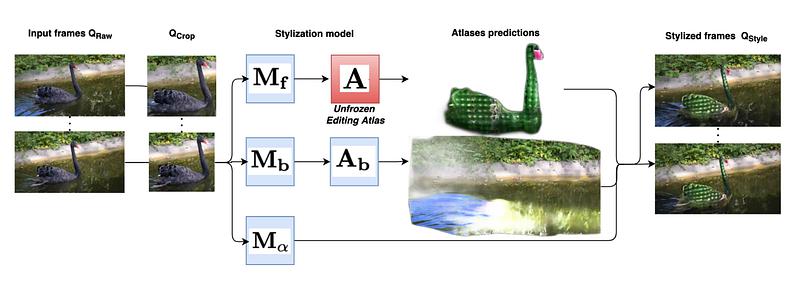
In the first step, the authors use the NLA procedure to teach the network how to put together video frames from inputs. Then, they make small changes to the editing atlas A using a new method . In their stylization pipeline, they make a set of input video frames that have been cropped, called Q Crop. A stylization model is used on this set to make a foreground and background atlas. -blending the predicted atlases makes a set of styled frames called Q Style. All of the MLPs’ weights are the same, except for the editing atlas MLP A, whose weight is tweaked.
Text — Video augmentation
A model that can make fine-grained changes to videos and images could be used for data enhancement in other learning environments. In the future, the authors could also extend the model to make shape changes or even entirely new objects.
Keywords: computer vision, Artificial Intelligence, Machine Learning, AI art, art, digital art, Dalle 2, Imagen, Parti, text-to-image, diffusion models, generative art, text-to-video, stylizing objects , videos, text-prompt
I invite you to explore the concept of “AI creativity” by reading and learning from the many articles found on 🔵 MLearning.ai 🟠
- Check out my instagram with new material every week
- If you enjoyed this, follow me on Medium for more
- Want to collaborate? Let’s connect on LinkedIn
- https://linktr.ee/evartology
Data Scientists must think like an artist when finding a solution when creating a piece of code. Artists enjoy working on interesting problems, even if there is no obvious answer.
All our writers (members) receive the opportunity to be promoted on our social media, which increases the popularity of articles published on MLearning.ai
- Linkedin (15.2K+ ML-professionals)
- Twitter (5.1K+ followers)
- Instagram (2.2K + followers )
- Sketchfab * — individual vRooML!
- Youtube
- Apple Podcasts
- Substack
Project Page:
https://arxiv.org/pdf/2206.12396.pdf

@article{loeschcke2022text,
title={Text-Driven Stylization of Video Objects},
author={Sebastian Loeschcke and Serge Belongie and Sagie Benaim},
journal={arXiv},
year={2022}
}