
Adapters: A Compact and Extensible Transfer Learning Method for NLP
Adapters obtain comparable results to BERT on several NLP tasks while achieving parameter efficiency.
Parameter inefficiency, in the context of transfer learning for NLP, arises when an entirely new model needs to be trained for every downstream task and the number of parameters grows too large.
A recent paper proposes adapter modules which provide parameter efficiency by only adding a few trainable parameters per task, and as new tasks are added previous ones don’t require revisiting.
The main idea of this paper is to enable transfer learning for NLP on an incoming stream of tasks without training a new model for every new task.
A standard fine-tuning model copies weights from a pre-trained network and tunes them on a downstream task which requires a new set of weights for each task. In other words, the parameters are adjusted together with new layers for each task. Fine tuning is advantageous in that it could be more parameter efficient if lower layers of the network are shared between tasks.
Adapters
The proposed adapter model adds new modules between layers of a pre-trained network called adapters. This means that parameters are copied over from pre-training (meaning they remain fixed) and only a few additional task-specific parameters are added for each new task, all without affecting previous ones.
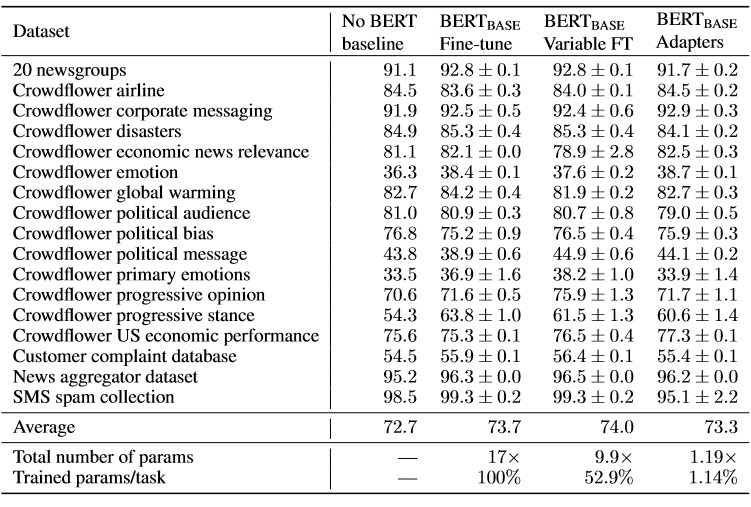
The innovation here is in the strategy that is used to design the adapter module to achieve parameter efficiency with one single model while not compromising performance. In fact, a simple model was compared with a fully fine-tuned BERT model on several text classification tasks. The findings show that only 3% of task-specific parameters are needed to almost match the results of the 100% task-specific parameters used by the fully fine-tuned model.
The traditional way of fine-tuning involves: 1) adding a new layer to fit the targets specified in the downstream task, and 2) co-training the new layer with the original weights. In contrast, the adapter tuning strategy injects new layers (randomly initialized) into the original network. Parameter sharing between tasks is supported since the original network’s parameters are frozen.
Keep in mind that only a small number of parameters are introduced in the proposed adapter-based tuning architecture, with the intention of keeping the original network unaffected and the training stable. The approach is simply to initialize the adapters to a near-identity function so that it can influence the distribution of activations (which can also be opted out) while training.
The adapter-based tuning is used with the popular Transformers, which are known to achieve state-of-the-art (SoTA) performance in many NLP tasks such as machine translation and text classification problems. The architecture is shown in the figure below:
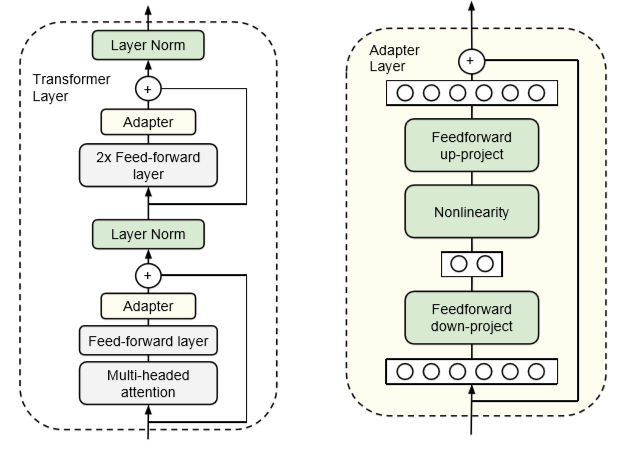
As you can see in the left of the figure, the standard Transformer is used with an additional adapter layer, added after each sub-layer and before adding the skip connection back. The output of the adapter layer is then forwarded to the layer normalization.
The adapters project the original feature size to a smaller dimension and then projects them to the original size thereafter, ensuring that the number of parameters stays substantially small as compared to the original model (procedure shown on the right of the figure). With the reduction of parameters, there is an obvious trade-off between performance and parameter efficiency which is discussed in the experiments below.
Experiments
The resulting effect of the added adapter layers is that they allow the model to focus on the higher layers of the network, which has generally been found effective in transfer learning.
The adapter-based model uses a training procedure similar to BERT for fair comparison (see more details in the paper). On the GLUE benchmark, adapters achieve a mean GLUE score of 80.0 (with 1.3 times the number of parameters of the pretrained model), compared to 80.4 achieved by a BERT-LARGE (with 9 times the number of parameters of the pretrained model). See the detailed results in the table below.

To further validate the performance of the adapters, other text classification tasks are used to test the effect of parameter efficiency (see the experimental setup in the paper). Overall, for all the tasks, adapters perform similar to full fine-tuning, variable fine-tuning (some layers are frozen), and baseline (which uses hyperparameter search), while substantially reduces the number of parameters used. See the table below for detailed results:
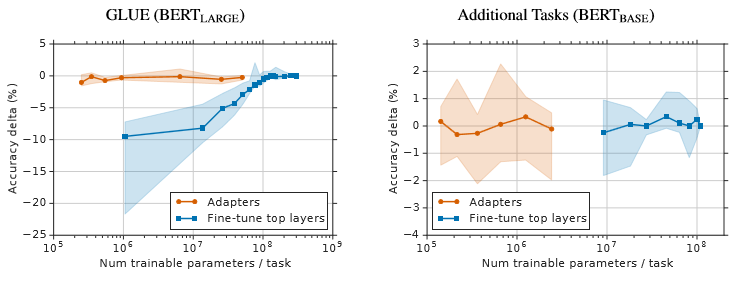
The figure below shows the parameter/performance trade-off aggregated over all the tasks used in the experiments above. For the GLUE benchmark in particular (see left of the figure), the fewer parameters are used in standard fine-tuning the lower the performance. Adapters were observed to yield stable performances even when substantially fewer parameters are used. See other results in the paper related to the performance/parameter trade-off.
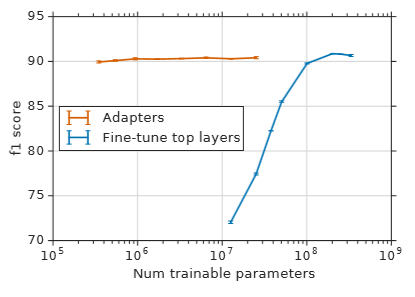
The adapters were also tested on SQuAD, which involves a question answering task. As shown in the figure below, adapters consistently produce comparable performance (on F1 score) to full fine-tuning, while training with substantially fewer parameters.
An extended ablation study is discussed in the paper in which the authors further investigated the robustness and extensibility of the adapters.
In summary, adapter-based tuning demonstrates comparable performance to full fine-tuning while at the same time maintaining high parameter-efficiency.
Parameter-Efficient Transfer Learning for NLP —(Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, Sylvain Gelly)
Other suggested readings: