
Web Scraping
4 Data Collection Tools You Should Not Miss In 2022
Information is a key for both survival and growth. Here are some of the best tools in the market to get it.

While I was watching the episodes of HBO’s Silicon Valley, I enjoyed the drama and comedy in that series. But what caught my attention the most was some ingenious product ideas such as SeeFood.
During his pitch to a VC firm, Coleman Blair, Erlich has realized that he was facing a serious problem. One of his programmers, Jian Yang, wants to speak about an app that promotes his grandmother’s 8 secret recipes of Octopus (SeaFood), which does not meet the VC firm’s assumption of a camera-based app.
“Like you take a photo of food, the app returns nutritional information or recipes or how it was sourced,” said the venture capitalist, explaining his expectation.
After hearing this last sentence, Erlich felt inspired. Without hesitation, he announced that their project is in fact SeeFood and not SeaFood: it’s “Shazam for food” like a food that you can see.
That announcement has saved them some hassle. But later, they noticed they needed lots of data to train the machine-learning algorithm that will allow the app to recognize and identify the meal. They planned a large-scale scraping task for images from the web, but they struggled to achieve it with the budget and the short time they have.
If they have used the appropriate tools and infrastructure, they could have succeeded in their mission.
You’re probably not going to build the next “Shazam for food,” but just like Erlich and Jiang Yang, you may have faced or going to face situations where you need to collect and analyze public data and get meaningful insights from it to make some important decisions or to automate and boost your business.
To help you with such an endeavor, I’m going to share with you, in this post, my review of four powerful data collection products that offer distinct features to cover different end-users needs.
1. ScrapingAnt

ScrapingAnt is a scraping API that runs a cluster of hundreds of Chrome browsers under the hood and offers a large proxy pool — including rotation and residential proxies — from all around the world to allow users to scrape all websites without being blocked. It can extract data much faster than with the use of single computer power and scrape thousands of pages in parallel.
It supports Python, JavaScript, and any programming language that can make API calls.
As a developer, I find ScrapingAnt very comfortable. I have used it by installing its client library scrapingant-client in my Node.js project, then implementing the code on my IntelliJ editor and running it locally on my terminal with the node command:
node my-scraper.jsIn this video, you see an example of how I used it:
Team support
The team is very supportive and friendly and can even create custom scraping scripts for you if you’re not a developer. You need just to send an email and communicate your requirements to them.
Price
- Free plan with 10,000 API credits. This plan includes JavaScript rendering, custom cookies, output preprocessing, basic email support, documentation.
- Enthusiast for $19/month: 100K API calls
- Startup for $49/month: 500K API calls, expert assistance.
- Business for $249/month: 3M API calls, expert guidance.
2. ScraperAPI

ScraperAPI is comparable to ScrapingAnt with slightly different pricing models. It supports Python, JavaScript, PHP, Ruby, and Java and offers an API that is easy to customize.
To enable JS rendering, IP geolocation, residential proxies, and more feature, all you need is just to add parameters such as &render=true, &country_code=us, and &premium=true, to your request.
curl "http://api.scraperapi.com/?api_key=APIKEY&url=http://http://httpbin.org/ip&render=true"Each one of the below pricing models includes:
- Rotating proxy tools
- Custom header support
- Unlimited bandwidth
- Automatic retries
- Desktop & mobile user agents
- 99.9% uptime guarantee
- Custom session support
- CAPTCHA & anti-bots bypasses
- 24/7 professional support
Price
- Free plan with 5,000 requests.
- Hobby for $29/month: 250K API calls, 10 concurrent threads.
- Startup for $99/month: 1M API calls, 25 concurrent threads, geotargeting.
- Business for $249/month: 3M API calls, 50 concurrent threads, geotargeting, residential proxies, JS rendering.
- Custom pricing model for enterprise: unlimited API calls and concurrent threads, geotargeting, residential proxies, JS rendering, custom anti-bot bypasses.
There is a 10% discount for a sign-up with the coupon WEBENIUS10.
3. Octoparse

Octoparse is a great tool to start your web scraping journey, especially if you’re not a coder. If you’re a developer, it could save you time, which it did for me for some scraping tasks.
The tool is user-friendly and has a powerful auto-detection feature and a lot of guiding messages that are automatically adjusted after each action you take while you’re creating your scraping workflow.
Here are 2 videos showing how to use the tool to scrape the list of customers' reviews and the list of content from my own Medium profile:
If you have a complex scraping scenario, you may need more training with the tool to know how to correctly set up your data collection workflow and learn more details like:
- How to scrape data that requires authentication.
- How to add required fields that are not auto-detected.
- How to auto-convert, format, and transform some fields with the “clean data” feature.
- and so on
I had such a complex case, and after struggling for two or three days to fix my scraping task — without asking the support of the team —, I’ve noticed that it could be much easier and less time-consuming if I have used a scraping API, like ScrapingAnt, and wrote the required scraping code by myself.
If you find yourself in such a situation and you can’t afford to invest time to learn, don’t make my mistake and ask the team to help you.
Team support
The team is supportive. When I needed their help, I’ve sent them messages with the tool itself and they get back to me per email, and the rest of the questions/answers, till my issue was solved, were per email.
Price
- Free plan for simple projects
- Standard for $75/month
- Professional for $209/month
- Data service starts at $399/month
- Crawler service starts at $189/month
- Custom pricing model for enterprise
4. Bright Data

Bright Data (formerly Luminaty) is the World’s #1 web data platform. It allows you to scrape public web data by offering a pool of tools and services that includes a data collection infrastructure and ready-made datasets.
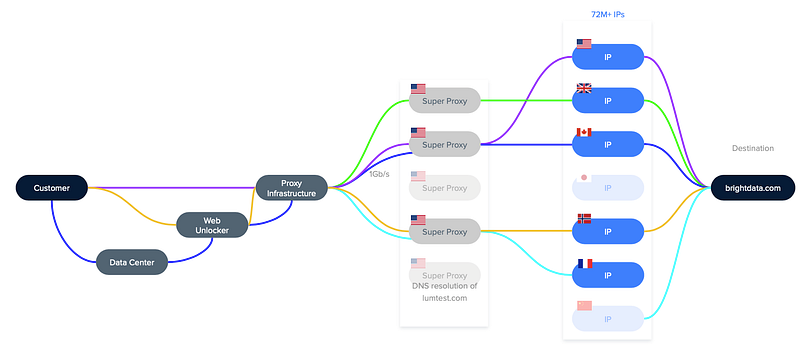
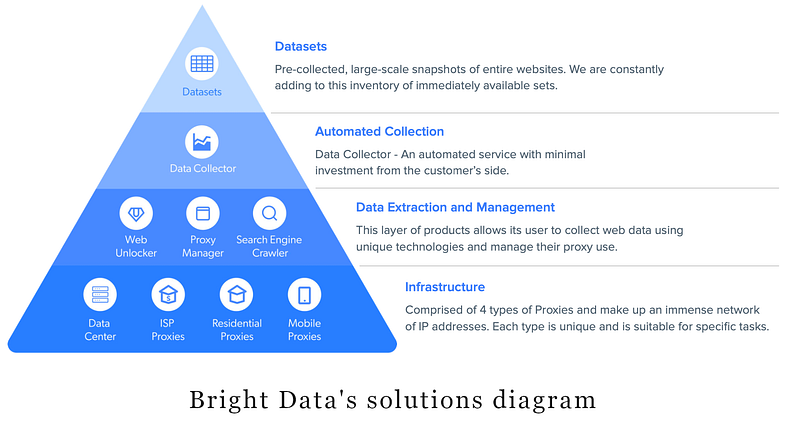
Bright Data’s products could be divided into four main categories: each category has its own characteristics and serves as the technological basis for the categories above:
1. Infrastructure
residential proxies, data center, ISP proxies, mobile proxies
This category contains an extensive network of IP addresses and 4 types of proxies: each type is unique and is suitable for specific tasks.
2. Data Extraction and Management
web unlocker, proxy manager, search engine crawler
These products allow you to manage your proxy and collect web data using unique technologies.
3. Data Collector
To use this automated service to collect data, you can:
- Choose and run one of the existing web scraping' templates,
- Request a new custom collector,
- Or implement a new one by yourself in the code editor on their web app. There you notice that the source code is divided into different views, which looked for me not as comfortable as using the ScrapingAnt API on my local code editor, which is more natural for me as a developer.
This video shows a scenario of scraping the list of Top Writers from Medium using Bright Data’s Data Collector service.
Note: The Data Collector can retrieve only publicly available data that does not require authentication. If you need to get a list of experts from LinkedIn, for example, and LinkedIn asks you to give your username and password before accessing that list, unlike the other mentioned providers, you may not be able to enter them to get what you need with Bright Data’s collector.
4. Datasets
Datasets are pre-collected, large-scale snapshots of entire websites that cover a wide range of data, like companies, people, and social media influencers. This is useful for many use cases, such as identifying and analyzing trends, optimizing your eCommerce activity, or even getting data to feed your machine learning algorithms. If the existing collections are not suitable for your needs, you can request a new dataset.
Team support
The team is supportive. When I needed their help, I’ve sent them messages with their web app itself and they get back to me per email and per skype. The rest of the questions/answers till my issue was solved were per skype.
Price
Bright Data offers slightly different pricing models from the other providers: pay as you go, yearly subscription, and monthly subscription.
This monthly option for the Data Collector includes the following models:
- Experimenting for $350/month: from $3.50/CPM, 100K page loads.
- Starter for $750/month: from $3.00/CPM, 250K page loads.
- Production for $1,250/month: from $2.50/CPM, 500K page loads.
- Plus for $2K/month: from $2.00/CPM, 1M page loads.
- Custom pricing model for enterprise
The rotating residential proxies are available to test with a 7-day free trial.
One More Thing
Although the above products are great ones to have in your toolbox as a software developer, a data scientist, a machine learning enthusiast, a business owner, a marketer, or even a content creator, you can always save your time and effort by outsourcing your data collection tasks to a web scraping service like ScrapeIt.
ScrapeIt offers:
- Up to 100,000 rows for $220 if it’s one-time data delivery.
- Up to 100,000 rows for $170/mo if it’s recurring data delivery.
- From $1000 for a custom solution.
I hope this list of tools and services gives you some guidance and helps you to make the best decision regarding how to get the information you need to achieve your endeavors.
Want more?
I write about engineering, technology, and leadership for a community of smart, curious people 🧠💡. Join my free email newsletter for exclusive access or sign up for Medium here.





