
A simple way to learn generally from a large training set: DINO
This post describes a self-supervised learning method: self-distillation with no Labels (DINO)
While the method (DINO [1]) itself is simple and straightforward, there are some prerequisites to understanding the method, i.e., 1) supervised learning, 2) self-supervised learning, 3) knowledge distillation, and 4) vision transformer. If you know all of it, you can skip to here.
Supervised Learning
Supervised learning is straightforward. We have a bunch of images, for each image, we have a label. Then, we train a model by telling it which image belongs to which label. In this case, we call it image classification, the learning objective is the cross-entropy loss between the one-hot label and the predicted probability distribution. By taking the index of the maximum value of the probability distribution, we obtain the predicted label of an image.
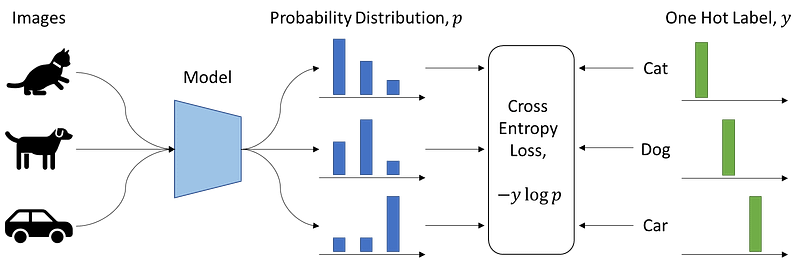
But the problem of supervised learning is that the model will often reduce the rich visual information contained in an image into a single category selected from a predefined set of a few thousand categories. In other words, the learning signal is only predicting a label.
Self-Supervised Learning
Self-supervised learning (SSL) is slightly different from supervised learning. We design an algorithm that can generate a “pseudo-label”, then we train the model like how we train with a supervised learning method.
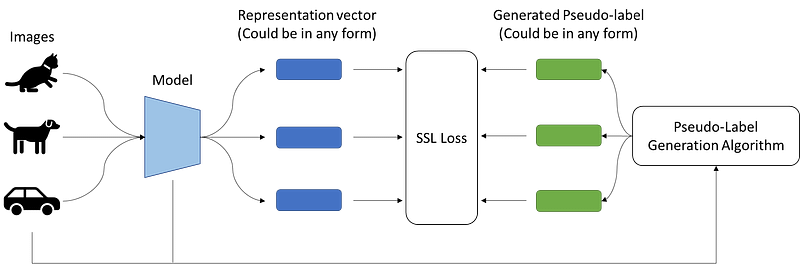
This kind of SSL methods are called the discriminative approach which includes instance classification (considering every single image is a different class, [2]), contrastive learning (learning to compare (like a siamese network) instead of classifying, [3]) or clustering (cluster the images first, obtain pseudo-labels, continue with supervised learning method, [4]). In practice, this is slow and memory intensive because only large batches can learn properly without collapsing. Recent methods have shown that SSL without discriminating images is also possible, that is to match the representation like metric-learning instead (e.g., BYOL [5]). In this way, the large batches problem is solved.
The model trained with SSL is usually more “general” because this is learned from millions of images without telling it what to learn specifically. Therefore, the model may keep a much more useful representation of an image.
Finally, we can use this generally self-supervised pre-trained model as initialization for fine-tuning on small datasets with the usual supervised learning (this is usually called Downstream Task). This usually boosted the performance of the downstream task because the model is less likely to be overfitting on the small datasets and the learned features are more useful. Therefore, downstream tasks like linear classification or object detection were usually used as an evaluation for an SSL method.
Knowledge Distillation
Consider a pre-trained model with a heavy backbone such as ViT-Large, we want a lightweight model that has a lower number of parameters and the computation FLOPS while able to output the same features (or class probabilities) given the same inputs (to mimic the output of the heavy model).

The reason is that training the lightweight model from scratch might not be able to perform as well as the heavy pre-trained model, but mimicking the output of the heavy pre-trained model can ensure that the performance will be remained as original as possible. This is called knowledge distillation, where we “distill” the “knowledge” from the heavy model (we usually call it Teacher model) into the lightweight model (Student model). In this way, we can have a compressed model that is fast and able to perform the same as the original model.
Note: It is common for the student model to be a smaller model than the teacher model, but it is also possible to have the same architecture as the teacher model (e.g., co-distillation [6]).
Vision Transformer
“Transformer” itself was an architecture introduced in the NLP domain that utilizes the attention mechanism. We can input a sentence with N tokens, then the transformer will first compute an attention vector and an embedding vector for every token (as a matrix, with the size of NxN and size of NxD respectively), then obtain a new embedding vector for every token by performing the dot product of the attention matrix and the embedding matrix (NxN dot NxD -> NxD). This means that each new embedding vector, is computed as a weighted summation of all the original embedding vectors, and the weights are the attention matrix.
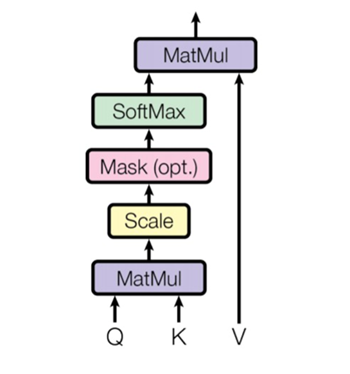
Then, “Vision Transformer” (ViT) was introduced for the computer vision domain that is similar to “Transformer”, but N tokens become N patches.
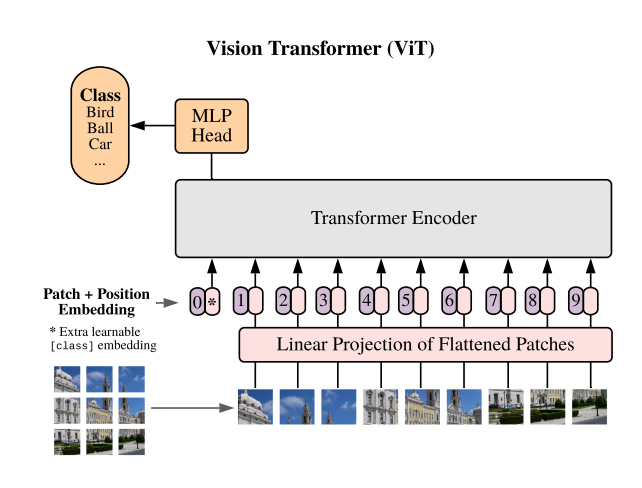
We commonly use CNNs to compute image representation, ViTs are just an alternative architecture. Two key differences with CNN are 1) the attention mechanism 2) and capturing global relationships (meaning seeing all patches before computing representation. CNNs see only local patches, i.e., neighbors only).
Self-Distillation with No Labels (DINO)
With the prerequisite, finally, we have arrived at the main focus — DINO. Basically, it is a general SSL method for computer vision that can apply to any architecture. This paper shows that Vision Transformer’s attention mechanism has a nice interpretation of what DINO has learned which is beneficial to image segmentation and able to achieve comparable performance with the best CNNs specifically designed for self-supervised learning.
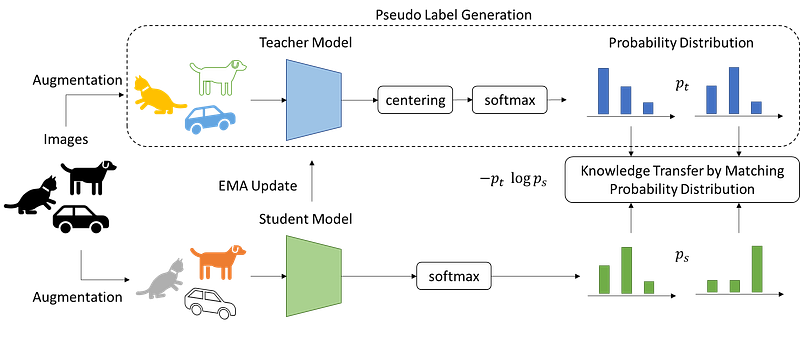
As mentioned earlier for SSL, we need to define a “pseudo-label” and a learning objective based on the defined pseudo labels so that the network can learn from it. Instead of a single label for discrimination, DINO defines the pseudo-label as “teacher’s representation”, and the learning objective is to match “student’s representation” with the teacher’s one.
Technically, this learning style is called knowledge distillation where we train a student network to match the output of a given teacher network. In DINO, both teacher and student networks have the same architecture, but different parameters. Given an image, both networks will output probability distributions over K dimensions (a pre-defined hyperparameter), Pt (teacher’s output), and Ps (student’s output).
By fixing the teacher’s parameters, the student network learns to match the distributions by minimizing the cross-entropy loss (with respect to student’s parameters), H(Pt, Ps) where H(a, b) = -a log b, by using stochastic gradient descent.
When computing the probability distribution, the output of the network is passed into a softmax function and then “sharpened”. The sharpening is like a soft clustering. If the sharpening strength is strong enough, then the output becomes a one-hot label.
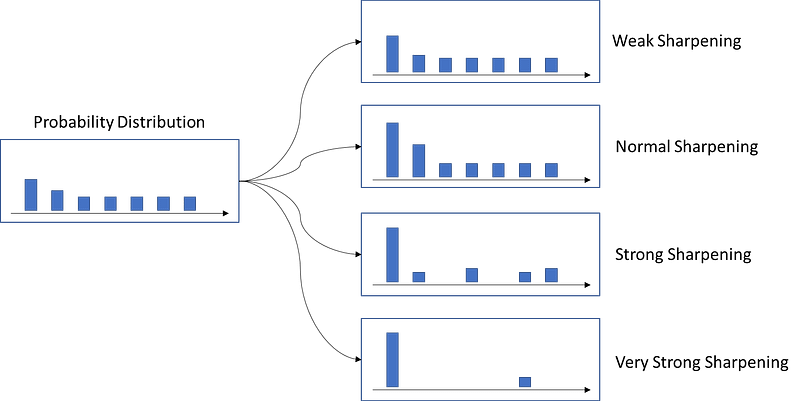
Since we are only aware that the image itself is itself, many SSL methods utilize this benefit and generate different “views” of the image (meaning different augmentations). Then teaching the model to differentiate whether the two views come from the same image or different image. The model will try to find out what is the difference between the two views, and choose to keep or discard the representation. In DINO, the same strategy is used. That is, two views are separately passed into the teacher and the student network, then the matching objective will require the student network to output the same values as the teacher’s output (with strong sharpening strength, the matching objective is like requiring the student network to predict the label of teacher network).
More tricks were used in DINO to prevent collapsing such as 1) multi-crop strategy, 2) momentum encoder for teacher network (i.e., EMA of student network) 3) and normalization of the teacher’s output.
For the multi-crop strategy, many smaller crops of an image are passed into the student networks (imaging that the student network sees only a small part, but is asked to predict the whole image).
For the momentum encoder, the parameters are usually the EMA of the student network, it is like stacking many student networks in the past as one teacher network. This benefit is probably related to Mean Teacher. Many recent SSL methods also apply the same practice.
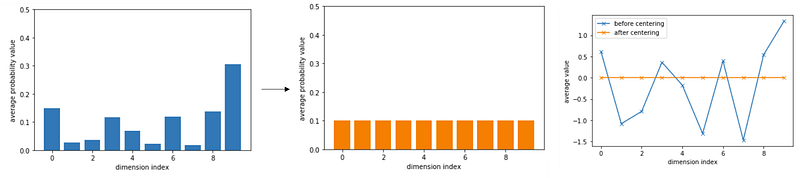
For normalization of the teacher’s output, it is very similar to batch normalization. In batch normalization, we perform subtract a value to make the batch zero-mean and scale by a value to make the batch have a variance of one. Teacher normalization is also similar, which includes both centering (zero-mean) and sharpening (scaling). Centering prevents one dimension to dominate but encourages collapse to the uniform distribution (meaning each dimension, is a zero-mean, we definitely have positive and negative values, then exp(positive)~1, exp(negative)~0). Sharpening does the opposite (meaning each dimension, we want to have only a high positive value).
How good it is before downstream tasks
After training, the teacher network is used as the network to compute representation (because the teacher network is a stacking of many student networks in the past). By doing k-NN with the features, DINO can already perform close to purely supervised learning. For instance, the supervised ’s k-NN score is 79.3 (on ResNet50), while DINO’s score is 67.5. Note that this is a very good achievement since we did not use a single label, but were still able to classify and group images correctly.
When training with Vision Transformer, the computed attention map is surprisingly interpretable and able to focus on different objects or parts.

This means that ViT trained with DINO can naturally do segmentation without supervision.
Conclusion: What are the emerging properties?
Although DINO is a general SSL method, the paper is named “Emerging Properties in Self-Supervised Vision Transformer”. I guess this is because the authors want to show that SSL ViT learned by DINO has the following properties: 1) the quality of the features in k-NN classification 2) and the presence of information about the scene layout in the features which benefit weakly supervised image segmentation.
This post has skipped many mathematics and experiments. I recommend that readers read the original paper [1] if you are interested.
Personally, I think DINO is a very simple SSL method and effective. Recently, Facebook has released a generalized SSL framework — data2vec [7]. I have a brief reading and data2vec is actually a combination of DINO and Masked Autoencoder (MAE) [8], showing that this learning mechanism is really beneficial not only to images but also to other domains such as speech and text.
Reference
- Mathilde Caron, Hugo Touvron, Ishan Misra, Herve Jegou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging Properties in Self-Supervised Vision Transformer.
- Zhirong Wu, Yuanjun Xiong, Stella X Yu, and Dahua Lin. Unsupervised feature learning via non-parametric instance discrimination. In CVPR, 2018.
- Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geof- frey Hinton. A simple framework for contrastive learning of visual representations.
- Junyuan Xie, Ross Girshick, and Ali Farhadi. Unsupervised deep embedding for clustering analysis. In ICML, 2016.
- Jean-Bastien Grill, Florian Strub, Florent Altche, Corentin Tallec, Pierre H Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Moham- mad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, Remi Munos, and Michal Valko. Bootstrap your own latent: A new approach to self-supervised learning. In NeurIPS, 2020.
- Rohan Anil, Gabriel Pereyra, Alexandre Passos, Robert Or- mandi, George E Dahl, and Geoffrey E Hinton. Large scale distributed neural network training through online distillation.
- Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, and Michael Auli. data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language.
- Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked Autoencoders Are Scalable Vision Learners.





