
|PERSPECTIVES| AI| LARGE LANGUAGE MODELS|
A Requiem for the Transformer?
Will be the transformer the model leading us to artificial general intelligence? Or will be replaced?

The transformer has dominated the world of artificial intelligence for six years, achieving state-of-the-art in all subdomains of artificial intelligence. From natural language processing (NLP) to computer vision to sound and graphs, there are dedicated transformers with excellent performance.
- How much longer will this domain last?
- Is the transformer really the best architecture out there?
- Will it be replaced in the near future?
- What are the threats to its dominance?
This article attempts to answer these questions. Starting with why the transformer has been so successful and what elements have allowed it to establish itself in so many different domains, we will analyze whether it still has unchallenged dominance, what elements threaten its supremacy, and whether there are potential competitors.
A brief history of an empire

“All empires become arrogant. It is their nature.” ― Edward Rutherfurd
Empires inevitably fall, and when they do, history judges them for the legacies they leave behind. — Noah Feldman
“Attention Is All You Need” Is the basis of artificial intelligence as we know it today. The roots of generative AI and its success are in a single seed: the transformer.
The transformer was initially designed to solve the lack of parallelization of RNNs and to be able to model long-distance relationships among words in a sequence. The idea was to provide the model with a system to discriminate which parts of the sequence were most important (where to pay attention). This was all designed to improve machine translation.
These elements, though, allowed the transformer to understand the text better. In addition, parallelization allowed the model to scale both as a size and as on larger datasets. The rise of GPUs further showed the benefits of a parallelizable architecture like the Transformer.
The Transformer thus emerged as the new king of AI. An empire grew in a very short time. In fact, today, all the popular models are Transformer: ChatGPT, Bard, GitHub Copilot, Mistral, LLaMA, Bing Chat, stable diffusion, DALL-E, Midjourney, and so on.
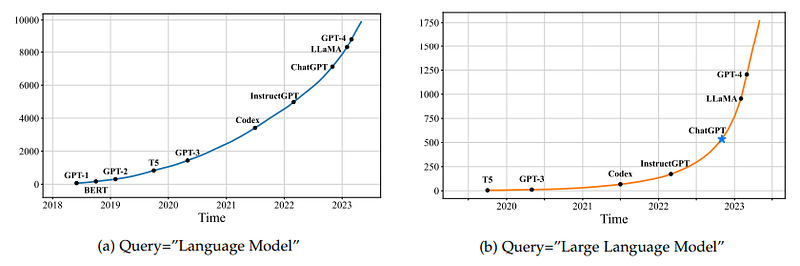
This is because Transformer was quickly adapted to so many tasks beyond language.
Even the vastest empires fall at some point; what is happening to the Transformer dominion?
The giant with feet of clay
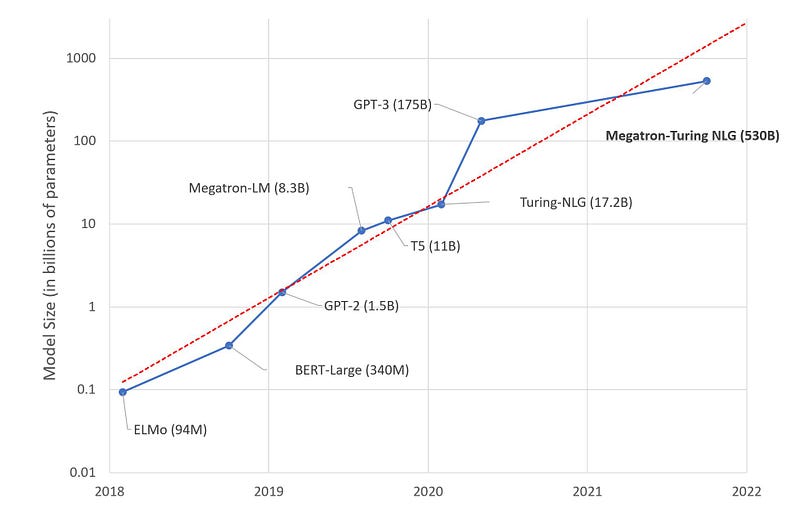
When the transformer was introduced, its performance shocked the world and gave rise to a parameter race. For a time we saw a kind of growth in models to the extent that it was called the “new Moore law of AI.” The growth continued until Megatron (530 B) and Google PaLM (540 B) were released in 2022. And yet we still haven’t seen the trillion parameters.
When deep convolutional networks showed their efficiency (VGG models), ConvNets went from 16 layers of VGG16 to 201 layers of DenseNet201 in a short time. Results and performance aside, it is a testament to the interest of the community. This pattern of horizontal and vertical growth (and incremental changes to the base model) stopped in 2021 when the community became convinced that Vision Transformers (ViTs) were superior to ConvNets.
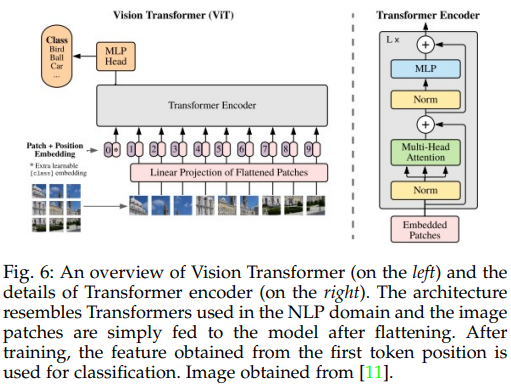
Why did the growth of transformers stop? Were they replaced as well?
No, but some of the premises that led to transformer growth have disappeared.
This growth was motivated by the so-called power law. According to OpenAI, by increasing the number of parameters, properties emerge abruptly. So scaling the models leads the model to develop properties that would not be observable below a certain scale. Too bad, that for Stanford researchers these properties are a mirage derived from a bias.
Scaling up a model means spending much more. More parameters, more computation, more infrastructure, more electrical consumption (and more carbon emissions). Is it worth it?
Actually, DeepMind with Chinchilla said that performance increases not only with the number of parameters but also with the amount of data. So if you want a model with billions of parameters you have to have enough tokens to train it. Too bad, that we humans don’t produce enough to train a model from a trillion parameters.
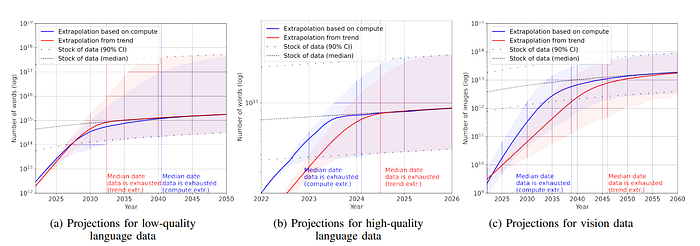
In addition, it is not just the quantity of text that impacts the performance of a model. it is the quality of the text. This is also a sore point because collecting huge amounts of text without filtering is not a good idea (aka downloading without criteria from the Internet).
Also, generating text using artificial intelligence is not a good idea. In theory, one could use an LLM and ask it to produce text indefinitely. The problem is that the model trained with this text can only mimic another LLM, and certainly not outperform it.
Overall, our key takeaway is that model imitation is not a free lunch: there exists a capabilities gap between today’s open-source LMs and their closed-source counterparts that cannot be closed by cheaply fine-tuning on imitation data. (source)
An additional point is that these huge models are also problematic for deployment. Smaller models have good performance, especially for some tasks. One can distill and get much smaller models specialized for a specific task.
Take home message: the huge transformer paradigm is in crisis. The idea that every year we will see a bigger and bigger model is over.
After all, the issue is practicality (and cost). AI can cost a lot of money once it goes into production. For example, Microsoft is reportedly losing huge amounts of money on GitHub Copilot ($20 per user per month). According to one report, ChatGPT costs $700,000 per day, and investors may no longer cover the cost if ChatGPT does not become profitable.
Therefore we can expect companies more interested in developing smaller models with a specific task and business in mind.
Okay, the transformer no longer grows, but is it still the best architecture in the game?
well, let’s talk about that in the next section…
Convolution is still on fire

First, why was the transformer successful everywhere?
In its initial description, the transformer brought together three basic concepts: starting with a position-aware representation of the sequence (embedding + positional encoding), relating the elements of the sequence (self-attention), and constructing a hierarchical representation (layer stacking).
When the article Attention is All You Need was published it was based on a decade of research in NLP and put together the best of what had been published previously:
- word embedding was revolutionary in 2013 in being able to transform words into vector representations. In addition, operations on embedding had logical and grammatical meaning.
- Self-attention was an improvement on the revolutionary idea that not all elements of the sequence are important. Plus solving the long-standing problem of recurring neural networks and their vanishing gradient.
- The hierarchical representation, on the other hand, came from twenty years of convolutional neural networks where we realized that by stacking layers the model learns an increasingly complex representation of the data.
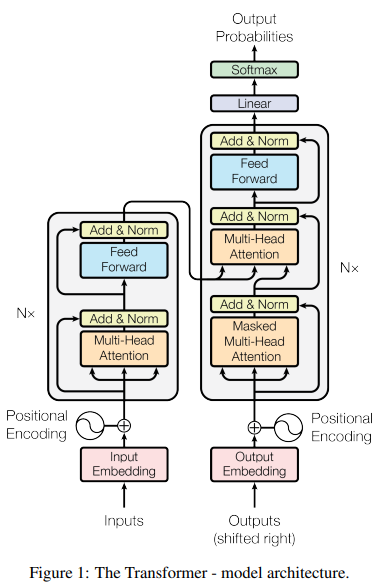
These elements made him successful in the NLP field, but at the same time, they were the key to winning in other fields as well. First, the fact that it had a very weak inductive bias made it adaptable to almost any type of data. Second, hierarchical representation and connecting elements of a sequence have applications far beyond NLP.
A story of success, except that the transformer has remained the same as it was in 2017 and is beginning to age badly.
The beating heart of transformers is ultimately self-attention. But it is a heart that pumps too much blood. In fact, its quadratic computational cost is huge.
Therefore, several groups have tried to try to find a linear substitution to attention. However, all of these variants have been shown to have inferior performance.
And what seemed a good substitute? Nothing less than the old convolution. As they showed in Hyena, by adapting convolution a little bit, you get a good model with transformer-like performance.
This is ironic because since 2021 Vision Transformers (ViTs) have been believed to be superior to ConvNets in computer vision. This seemed to be the end of the uncodified dominance of convolutional networks (ConvNets) in what until recently was their realm. But instead?
It seems that the ConvNets have had their revenge. Astonishing, like thinking that dinosaurs would return to dominance over continents by driving out mammals. In truth, a recent article published by DeepMind basically states that the comparison between ViTs and ConvNets was not fair. By providing the same compute budget to ConvNets these have similar performance to ViTs on ImageNet.
Another article seems to go in the same direction, convolutional networks seem to be competitive with transformers:
The same winners also win at smaller scales. Among smaller backbones, ConvNeXt-Tiny and SwinV2-Tiny emerge victorious, followed by DINO ViT-Small. (source)
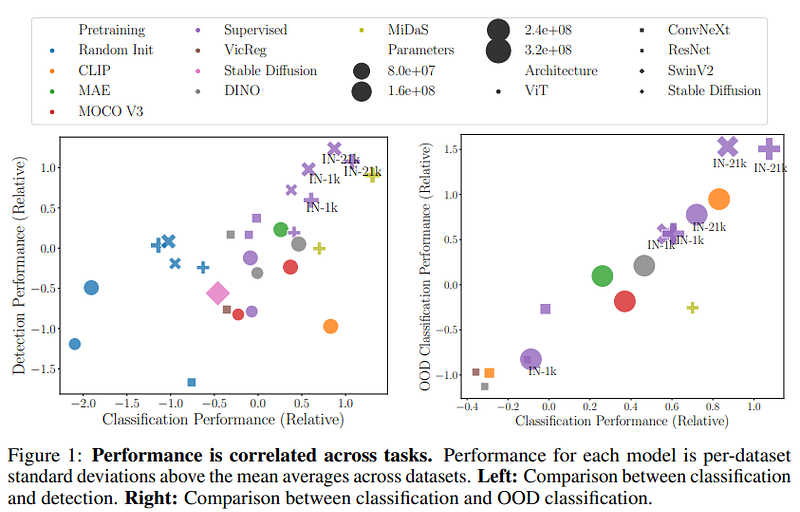
There are three primary factors that influence the performance of such a model: its architecture, the pretraining algorithm, and the pretraining dataset. (source)
Now if the pretraining algorithm and pretraining dataset are the same only the model architecture remains. However, all things being equal, the alleged superiority of ViTs does not seem to emerge. So much so that it seems like an admission of defeat what the DeepMind authors claim:
Although the success of ViTs in computer vision is extremely impressive, in our view there is no strong evidence to suggest that pre-trained ViTs outperform pre-trained ConvNets when evaluated fairly. (source)
Ouch. So we can say that ViTs are not superior to convolutional networks at least in computer vision. Is it?
We note however that ViTs may have practical advantages in specific contexts, such as the ability to use similar model components across multiple modalities. (source)
The authors point out that they could potentially still be superior because useful when we are interested in multimodal models. Considering that features can also be extracted from a convolutional network, it is certainly more convenient to use the same model across multiple modalities.
However this is a very important point, empirical data show that at least in computer vision the transformer is not superior to other architectures. This leads us to wonder whether its dominance will soon be questioned in other fields of artificial intelligence as well. For example, what is happening in the core field of the transformer? It is still the best model in natural language processing?
The text Dominion has a fragile basis

Short answer: yes, but its supremacy could end. Let’s start with why it has been so successful in NLP.
The initial advantage of the transformer on RNNs is that easily parallelized. This led to the initial euphoria and rush to the parameter. In the process, we realized what allowed the Transformer to win in NLP: in-context learning.
In-context learning is a very powerful concept: all it takes is a few examples and the model is capable of mapping a relationship between input and output. All this without even updating a single parameter.
Basically, this was an unanticipated (and not yet 100 % understood) effect of self-attention. According to Anthropic, there are induction heads that practically connect different parts of the model and allow this mapping.
This miracle is the basis of the supposed reasoning capabilities of the models. In addition, the fact that one could experiment so much with the prompt allowed for incredible results.
In practice, without having to train the model again, prompting techniques could be created to improve the model’s capabilities in inference. Chain of thought is the best example of this approach. Using this ploy, an LLM is able to solve problems that require reasoning (math problems, coding problems, and so on).
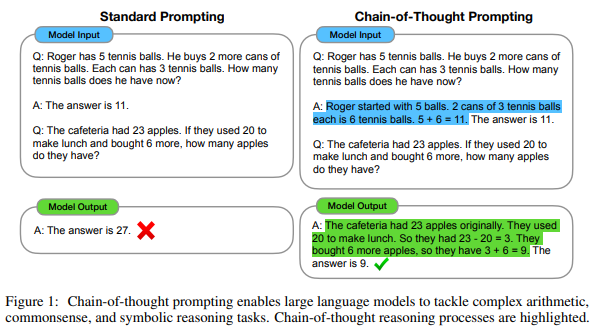
However, one must take into account that:
However, this multi-step generation process does not inherently imply that LLMs possess strong reasoning capabilities, as they may merely emulate the superficial behavior of human reasoning without genuinely comprehending the underlying logic and rules necessary for precise reasoning. (source)
Translated, we have created a parrot that has seen the entire human knowledge and can connect the question in the prompt with what it has seen during the training.
Why is this advantage extremely precarious?
Because the parrot does not have to be a transformer. We need any model that takes natural language instructions as input and can do in-context learning, after which we can use the whole arsenal of prompt engineering techniques as if it were a transformer.
Ok, so if we do not need necessarily the transformer, where is our new “stochastic parrot”?
Bureaucracy slows down innovation

The main reason is that research in industry is currently focused on bringing the transformer (despite its flaws) into production. Also, it is risky to put a better architecture into production but whose behavior we know less about.
Let’s dig more about it…
First, Google, META, Amazon, and other big tech have huge amounts of resources. Such large companies, however, are burdened by an elephantine internal bureaucracy:
Google is a “once-great company” that has “slowly ceased to function” thanks to its bureaucratic “maze.” (source)
This increase in bureaucracy, results in reduced productivity and an overall slowdown. In order to implement a small change, one must have the approval of increasingly long chains of command and follow increasingly complex protocols. In short, it seems that big tech has the same problem that has plagued empires.
This obviously impacts innovation as well:
“If I had to summarize it, I would say that the signal to noise ratio is what wore me down. The innovation challenges … will only get worse as the risk tolerance will go down.” Noam Bardin, former Google executive. (source)
Of course, there are also well-founded reasons for companies like Google or Microsoft to be more cautious in their choices. For example, Google lost billions in capitalization when Bard incorrectly answered a question about the James Webb Space Telescope.
These reputational risks have turned into a giant brake on innovation. A technology is adopted only when it is mature and not risky.
The best example is Apple. The company adopts a technology only when it is mature and considers it profitable. In general, it has stopped being innovative in recent years (while still maintaining record profits). So far, it has kept out of the generative AI race because it does not consider it mature.
Apple is known as a “fast follower”; it likes to wait until new technologies have matured, then jump in with its own Apple-flavored version. (source)
Shouldn’t this resistance to innovate then favor the transformer?
Yes, but we are forgetting open-source. It is not only Big Tech doing research, there are many groups of researchers investigating AI. They may not have the resources of the FAANGs, but together independent research is a formidable force.
Google itself admits this. In fact, Mountain View is less afraid of Microsoft or OpenAI:
“The uncomfortable truth is, we aren’t positioned to win this arms race and neither is OpenAI. While we’ve been squabbling, a third faction has been quietly eating our lunch,” Google’s leaked document, source
This third faction is precisely open-source. As soon as LLaMA was released it immediately received improved variants with instruction tuning, quantization, and Reinforced learning from human feedback (RLHF). Mistral 7B just came out and two groups extended the context length (first to 32K and then up to 128K).
Open-source models quickly become customizable and cheap, and gain support from a huge and active community. The open-source community immediately adopts each breakthrough and quickly improves it. Large companies waste time on internal bureaucracy and are restrained from adopting new technology because of the risk of reputational damage, risking falling behind.
This outstanding community is fertile ground for the transformer’s successor. If a model showed to overcome the transformer’s limitations it could count on the force of a tsunami.
But let’s look at one last point as to why despite everything the transformer has not yet been replaced
Theseus’ ship

A question was raised by ancient philosophers: After several centuries of maintenance, if each individual part of the Ship of Theseus was replaced, one at a time, was it still the same ship? — source
Has the transformer changed while remaining the same the transformer? A brief search of the literature clearly shows that there are hundreds of variants of the transformer today (if one takes into account all the variations of positional encoding, attention, and so on). So LLMs are not exactly the same model we have seen so far.
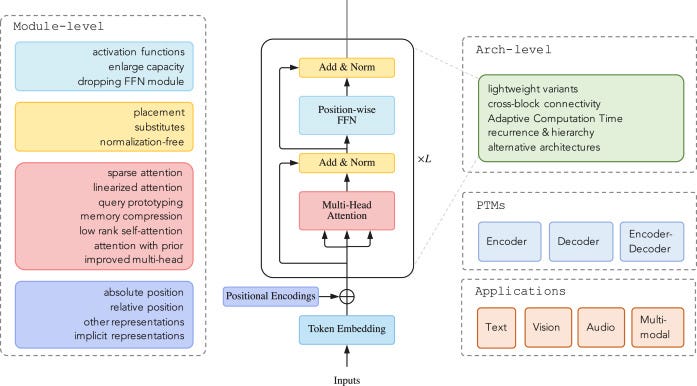
Right now we are in an incremental phase of research, where modifications of the same model continue to be proposed to try to overcome the limitations of a technology that is now old.
In a sense, we have reached the limits of the transformer. There is no point in scaling the model because it does not bring benefits nor do we have enough tokens. Second, the transformer is computationally expensive, and if in the past performance mattered today applications matter. Third, COT and other techniques are patches to the real limit of the transformer: the model is not really capable of understanding and generalizing. Self-attention allows the model to take advantage of the huge body of knowledge it has learned during training, but it still remains a stochastic parrot.
The transformer is a way to capture interaction very quickly all at once between different parts of any input. It’s a general method that captures interactions between pieces in a sentence, or the notes in music, or pixels in an image, or parts of a protein. It can be purposed for any task.” — Ashish Vaswani, author of the transformer paper (source)
In terms of cost, we will always see smaller and smaller specialized models for different applications. In addition, much of today’s research is looking for a less expensive alternative to the transformer (examples are Hyena, Monarch Mixer, BiGS, and MEGA).
In addition, transformer models lack the ability to learn continuously (they have static parameters) and lack explainability. Liquid neural networks (a model inspired by how worm brains work) aim to solve these two problems in particular.
Also, the idea of the monolithic transformer has been abandoned and more thought is given to the idea of having an ensemble of models working in this direction (GPT-4 seems to be an ensemble of 8 models). Sakana AI aims at the same concept by drawing inspiration from the idea of collective intelligence.
But so will these models replace the transformer?
Probably not. Or rather in some cases they will be adopted for specific necessities. For the time being, none of these models solve all the problems of the transformer, and for many applications the good old transformer is sufficient.
The transformer today has almost absolute dominance over many fields. Moreover, a lot of research and work has been based on this architecture and has led to its optimization. So it is challenging to replace it.
Ideas like liquid networks or swarm intelligence show that there is a search for alternatives beyond building more efficient and less expensive models. Then again, none of today’s research can overcome the real limitation of the transformer. Therefore, the transformer will be replaced but we do not yet know by what. It will be a new technology that will be based on new theoretical advances.
TL;DR
- The transformer parallelization advantage that led to the inordinate growth of LLMs is over. Having realized that huge amounts of quality data are needed has dulled enthusiasm for creating ever larger models. Plus deployment costs cripple larger models.
- Transformers no longer have absolute dominance over all branches of artificial intelligence. Recently some papers have shown that convolutional networks are competitive against transformers in computer vision when trained in the same way. their dominance in NLP is still undeniable but is based on fragile premises.
- Transformers could be replaced with a model capable of taking textual instructions and showing in-context learning. All prompt engineering techniques could be used the same.
- Large companies, weighed down by bureaucracy, are reluctant to innovate and are now focusing on application research. On the other hand, the open-source community is very active and a potential innovation would be adopted and pushed quickly.
- The real advantage of the transformer is that for years it had absolute dominance. So it has benefited from a lot of attention, research, and optimization. Being able to replace such a model is a very difficult but still necessary challenge. In fact, we have pretty much reached the limits of this technology and need a new one that will surpass it.
- While for the moment we do not have an alternative, research is looking for a model that can surpass it.
Parting thoughts

At this time, research in AI has been incremental, especially in model architectures. Large companies at this time have been dedicated to finally putting these models into production and using them for commercial purposes.
is true that after a year of big announcements, the institutions have also moved and new laws are being prepared that will regulate artificial intelligence. These laws will also partly define the directions of new research. If these laws are too rigid they will throttle innovation.
“There are definitely large tech companies that would rather not have to try to compete with open source, so they’re creating fear of AI leading to human extinction. It’s been a weapon for lobbyists to argue for legislation that would be very damaging to the open-source community.” — Andrew Ng (source)
Yann LeCun also feels the same way. Right now the big companies are afraid of open-source:
“If your fear-mongering campaigns succeed, they will *inevitably* result in what you and I would identify as a catastrophe: a small number of companies will control AI.” — Yann LeCun (source)
In any case, as we have seen no technology remains dominant forever, and the transformer is beginning to show the limits of its age. it is exciting to think about what will replace it, what theoretical advances, what elegant solutions it will implement, and what incredible capabilities it will have.
What do you think will replace the transformer? Have you tried and transformer alternative? Let me know in the comments
If you have found this interesting:
You can look for my other articles, and you can also connect or reach me on LinkedIn. Check this repository containing weekly updated ML & AI news. I am open to collaborations and projects and you can reach me on LinkedIn.
Here is the link to my GitHub repository, where I am collecting code and many resources related to machine learning, artificial intelligence, and more.
or you may be interested in one of my recent articles:
Reference
Here is the list of the principal references I consulted to write this article, only the first name for an article is cited.
- Vaswani, 2017, Attention Is All You Need, link
- Huang, 2016, Densely Connected Convolutional Networks, link
- Zhao, 2023, A Survey of Large Language Models, link
- Smith, 2023, ConvNets Match Vision Transformers at Scale, link
- Goldblum, 2023, Battle of the Backbones: A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks, link
- Wang, 2023, Pretraining Without Attention, link
- Ma, 2023, Mega: Moving Average Equipped Gated Attention, link
- Hasani, 2020, Liquid Time-constant Networks, link
- Yadlowsky, 2023, Pretraining Data Mixtures Enable Narrow Model Selection Capabilities in Transformer Models, link
- Kaplan, 2020, Scaling Laws for Neural Language Models, link
- Hoffman, 2022, Training Compute-Optimal Large Language Models, link
- Simonyan, 2014, Very Deep Convolutional Networks for Large-Scale Image Recognition, link
- Khan, 2022, Transformers in Vision: A Survey, link
- Wei, 2022, Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, link
- Touvron, 2023, LLaMA: Open and Efficient Foundation Language Models, link





