
How Perception Stack Works in Autonomous Driving Systems
A General Framework for Perception — an Introduction to Self-Driving Cars (Part 5)
In previous part of the Introduction to Self-Driving Car series, we discussed a core visual functionality of perception stack in an autonomous vehicle (AV): computer vision. In it we focused on perception sensing that involves data collection from vehicle sensors and the processing of this data into an understanding of the world around the vehicle — much like the sense of sight in a human driver.
Perception of the environment is indeed a crucial task in the pipeline to enable autonomous driving. By facilitating the perceptional sensors, such as camera, lidar, and radar, a vehicle is able to localize it self inside a static environment map. In this article, we will zoom out to better understand a higher level view of the perception stack, along with its fusion strategy to detect and classify the traffic participants in its surroundings in order to navigate safely. As different sensors possess individual strengths and weaknesses, the fusion of AV signals would facilitate a higher detection quality.
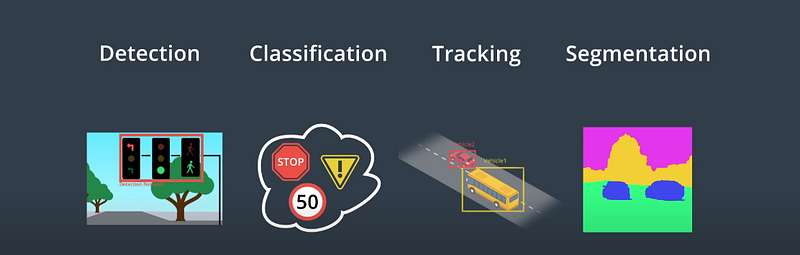
There are 4 core tasks in a self-driving software used to perceive the world around it:
- Detection to recognize and figure out where an object is in the environment.
- Classification to determine what exactly the object is.
- Tracking to observe moving objects over time, e.g. a walking pedestrian. This is useful for monitoring speed or velocity of the surrounding objects in relation to the vehicle itself.
- Segmentation to match each pixel in an image with semantic categories, such as road, car, and sky.
1. Detection
Object detection is emerging as a subdomain of computer vision that benefits from deep learning, especially convolutional neural networks (CNNs). More advanced variants of CNN structures that are used for detections — and often classifications too — include R-CNN (Region-based CNN), Fast R-CNN, Faster-RCNN, YOLO, and SSD.
“A detection algorithm is a technique for locating instances of objects in images or videos that leverages machine learning or deep learning to produce meaningful results.” — MathWorks
The goal of this detection technique is to determine where both static and dynamic objects are located in a given frame. Static objects include walls, trees, poles, and buildings. While dynamic objects include pedestrians, bikers, and so on.
A common example is traffic light detection. Here, computer vision initially localizes the traffic light within an image. A CNN structure is used to find the location of objects within the image. After localizing the object within the image, we send the image to another CNN for another classification or we could do detection and classification using 1 single CNN architecture concurrently, where one head might perform detection and another perform classification. A classification technique will bucketize the type of traffic light based on color of the light that it actively displays, which we’ll discuss further in the next section.
2. Classification
Once objects are detected and located in a given image, we would determine which category each object belongs to. This task is called “object classification.”
This is also among the most critical and expensive parts of the AV stack’s subsystems, as thorough and comprehensive data annotation is required to help train the machine learning algorithm to make the right decisions when navigating the roads. Note as of today nearly all state-of-the-art technology that works currently relies on supervised learning.
A self-driving car decides the path and speed it follows depending on the object and condition it precedes. For example, if it precedes a moving bike, then the AV will decide to slow down and change lanes in order to pass the bike safely. If it precedes a car, it will maintain its speed predicting the vehicle ahead will also maintain that same speed. This behavior decision is made as a result of AV’s ability to safely detect and correctly classify the object, whether a bike or a car.
In classification, both diversity and redundancy are critical to minimize failure and ensure safety.
The machine learning algorithms used for classifications are often used to interpret road signs, identify lanes, and recognize crossroads.
3. Tracking
Upon diving head first into the world of robotics, I realized that one of the autonomous driving industry’s biggest challenges in solving perception issues is an occlusion event. This is because during motion, visual objects undergo substantial changes in appearance. They can change size, shape, and position with respect to the background, as shown in figure below. They can even occasionally disappear behind other objects (C) and reappear in a new position (D).
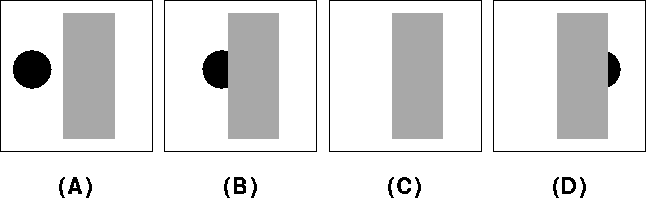
In this case, a visual system like tracking can learn to detect and represent depth relations, after a period of exposure to occlusion and disocclusion events. What is the goal of tracking, anyway?
- Tracking handles occlusion events. Once objects are detected in every frame, tracking across frames is crucial when detection of objects fails due to an occlusion of another object.
- Tracking preserves identity. The outputs of obstacle detection are bounding boxes containing objects. However there is no identity attached to each object. With object detections alone, we would not know which object in one frame corresponds to which object in subsequent frames.
Tracking is actually pretty straightforward:
- For identity tracking, we match objects in the previous frame with objects in the current frame by pairing detections with highest feature similarity. Objects typically have a variety of features, like colors and shapes. These image features can be computed using computer vision techniques such as local binary patterns and histogram of oriented gradients that are useful for considering the position and velocity of continuous frames — which don’t necessarily change significantly between frames so they are very useful for matching an object’s identity.
- After determining identities, we use the location of the object combined with a predictive algorithm to generate speed and location of the object at the next time step or in the next immediate frame.
4. Segmentation
Semantic segmentation involves classifying each pixel in the image. This is critical to understand the environment at the most detail possible. One application is to determine the drivable area of the environment.
Often, segmentation goes hand in hand with the detection task, segmentation also relies on Convolutional Neural Networks (CNNs). In a CNN architecture, every layer in the network is fully convolutional, which makes the resulting image much smaller than the original input image due to many convolutions within the step.
In order to segment the pixel, the network’s output size must match the size of the original input image. We can meet this size requirement by upsampling the intermediate output until we get an output that matches the size of the input image.
The first half of this network architecture is called the “encoder”, because it extracts and encodes the features of the input image. The second half of the network is called “decoder”, because it decodes these features and applies them to the output. Here is a demo of semantic segmentation implemented with TensorFlow:
Fusion-Based Perception
When an object falls and breaks, the simultaneous reception of our visual and auditory inputs form a single perception of this event. Given certain conditions, the human brain perceives sensations from different modalities as a whole. As a result, we react by trying to save the falling object. This perceptual fusion in human body works kind of similarly to a machine.
Like the different sensory inputs that a human experiences while driving, full autonomy is going to rely on a suite of sensors that can provide redundancy, work in multiple conditions, and absorb different kinds of information.
That means visible light cameras that can see, as well as LiDAR units that provide range and target information, radar that can back up spatial sensing, thermal cameras that can see in fog or at night, and much more. Working together, the system makes up what is called “sensor fusion.”
That’s just the hardware side. The software side also needs to be incredibly advanced, able to take information from all those sensors and make sense of the data in a single environment. The whole system is a perception engine.
“The job of the perception engine is to take the various inputs from those sensors and to fuse them into an understanding of those surroundings,” — Hod Finkelstein, CTO at Sense Photonics, a technology company specializing in LiDAR.
A common example of sensor fusion is to use LiDAR to naturally detect night time, camera images for cheaper object detections, and radar for various weather conditions.
A common methodology of sensor fusion is to use Kalman filter, which:
- Predict state of an object, e.g. the position and speed of a walking pedestrian.
- Update measurement, e.g. to use the new observation to correct an existing belief about the walking pedestrian.
Concluding Thoughts
Autonomous vehicle sensors generate massive amounts of data every fraction of a second. The sensors track the autonomous vehicle’s own state, and also the states of surrounding vehicles, pedestrians, and traffic signals. Every mile contains indicators for where the self-driving car should and should not go.
Identifying these indicators and determining those needed to safely move is incredibly complex, requiring a diversity of deep neural networks working in parallel. This is also why fusion-based sensing, with capability that extends to the full 360-degree field, is required for self-driving cars. This sensor system can accurately detect and track all moving and static objects. Then the vehicle can plan a path ahead and make a certain to act safely, instantly, and without human intervention.
Previously on this Introduction to Self-Driving Cars series:
[1] Wikipedia.org. “Perception,” https://en.wikipedia.org/wiki/Perception
[2] U.S. National Library of Medicine. “Why is there so much research on vision than any other sensory modality?” https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6787282/
More Resources
About the author: http://www.moorissatjokro.com/





