
A new way to sentiment-tag financial news
30% of financial headlines fit a specific pattern.

Over the past few years, financial-news sentiment analysis has taken off as a commercial natural language processing (NLP) application.
Like any other type of sentiment analysis, there’re two main approaches: one, more traditional, is by using sentiment-labelled word lists (which we will also refer to as dictionaries). The other, is using sentiment classifiers based on language models trained on huge corpora (such as Amazon product reviews or IMDB film reviews).
For domain-specific sentiment analysis, these latter language models tend to perform poorly. Hardly a surprise: a medical article reads nothing like a film review. In this respect, transfer learning is an interesting growing field. Currently, though, a dictionary still lies at the core of many domain-specific sentiment-analysis applications.
Within finance, those trying to build on open-source resources will likely end up with Notre Dame’s McDonald- Loughran (M-L) word lists, which were created by analysing over fifty thousand earnings reports over the 1994–2008 period [1]. This dictionary has been used by, among others, Google, Fidelity, Citadel, Dow Jones, and S&P Global.
What’s the problem then?
The obvious flaw in any sampled-and-labelled word list is that it’s small and cannot capture the full richness of a language, however specific the domain. Worse, though, is that EVEN WITHIN A SPECIFIC DOMAIN, words can take on a very different meaning, depending on a sub-domain’s context.
In financial writing, for example, it’s enough to move away from financial reporting to analysis of financial markets, and things start falling apart:
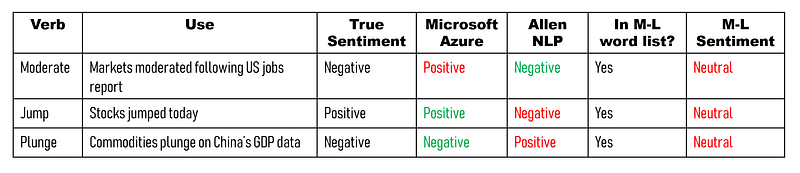
So we know we’re missing important information by using the M-L word lists. (We’ll see just by how much a bit further down.)
We also know that deep-learning language models (Like Microsoft’s Azure and Allen NLP’s sentiment taggers) offer limited added insight, because they’re often trained on radically different corpora (the AllenNLP demo is trained on the Stanford movie review dataset. So is, at least to some extent, Microsoft Azure’s text analytics tool).
Finally, it’s simply unsustainable to pay for data labeling for every sub-domain application.
What’s there to do?
Well, the thing about specific domains is that they don’t just have specialised vocabularies; they have writing-structure conventions. By structures, I mean syntactical choices that carry an embedded semantic meaning.
This article looks at one particular way in which financial markets get talked about. It shows how exploiting this structure allows you to gain an awful lot of useful information, with very little work.
The remainder of this article is as follows: 1. Examine a specific financial-markets writing convention, and how it lends itself to sentiment tagging. 2. Apply these insights to a sample of several thousand news headlines and explore the resulting data. 3. Examine what this analysis tells us about domain expertise when tackling NLP problems.
1. Writing conventions to the rescue
In financial writing, one has to be very careful about cause and effect. For individual companies, a stock can absolutely fall following, say, a poor earnings report. However, you’d rarely want to state that entire markets moved because of an event, though you’d still like to allude to that event’s influence.
So you use ‘as’: US Stocks Climb as Inflation Fears Recede.
In English, ‘as’ has multiple forms of use. But within financial headlines, where wordcount is frugal, ‘as’ is used almost exclusively in one specific way: to indicate that event A happens while event B is also taking place, and that B is at least partially causative of A happening.
Thus, the word serves as a hinge:

‘As’ is not alone in this peculiar role. To suggest explicit influence, you use ‘after’; to be slightly coy, you can use ‘amid’.
In terms of sentiment tagging, the key point here is that ‘as’ splits the sentence into two parts, which share the same sentiment.

To be clear, these two events could happen together; it’s not physics. But what will not happen, not ever, is for ‘as’ to be used to describe such co-occurrence, because of the embedded semantic meaning in choosing this hinged structure: a negative event can happen on the same day as a positive event, but not because the positive event took place.
Thus, if we figure out correctly the sentiment of one of the parts that hang off the ‘as’ hinge, we have figured out the sentiment of the other part as well. Already, this provides us with automated sentiment-tagging for a host of short sentences describing recent events, but it gets even better:
Because the introductory paragraph usually expands on a news story’s main point, by tagging the sentiment of one part hanging off the hinge, you have automatically tagged the sentiment of entire paragraphs.

The verbs hold the key
Because of the way ‘as’ and ‘amid are used, the main event is the first part of the sentence; the influencing event completes its other half. This writing convention doesn’t accommodate swapping the two parts:

But the beauty in financial markets is that they only ever move up or down. This means you can shortcut the sentiment tagging through the verbs.
We need to be slightly cautious here. In the above example, climb is not an absolute positive development. It’s positive when stocks climb; were inflation fears the ones to climb, this would be a negative.
This relates to the concept of frame semantics: you can’t understand the notion of the verb ‘climb’ in the context of stock markets without also having the notion of something people buy in the hope that it appreciates in value.
Now, generally for markets to move up is a positive, but there are specific instances where this is not the case, for example, bonds: when bond yields go up, bond prices go down.
To address this, we can establish a rule-based system that reverses the tagging in particular cases. So, we would tag a news story with ‘climb’ in its first part as positive by default, unless the subject of the sentence is an exception that reverses the tagging.
It’s a hack, but who cares? Considering tagging can be frightfully expensive, and that even for transfer learning you still need a domain-specific database of tagged sampled, obtaining one with so little added work is a pretty decent outcome.
So, just by exploiting this one writing convention, we’ve named two explicit benefits: one, large scale sentiment tagging of headlines, and two, meaningful tagging of entire paragraphs, potentially aiding deep learning approaches. Let’s explore their scope with some real data.
2. Data exploration
For the purposes of this research, I’ve collected a sample of several thousand financial news headlines, published over the last year. These discuss financial events and general market movements of stock, currency, and commodity markets, excluding news concerning specific companies.
I’ve segmented the data based on the geographical markets the news was discussing. On the whole, one would expect a certain degree of variance between these; after all, different groups of writers should have slightly different writing patterns.
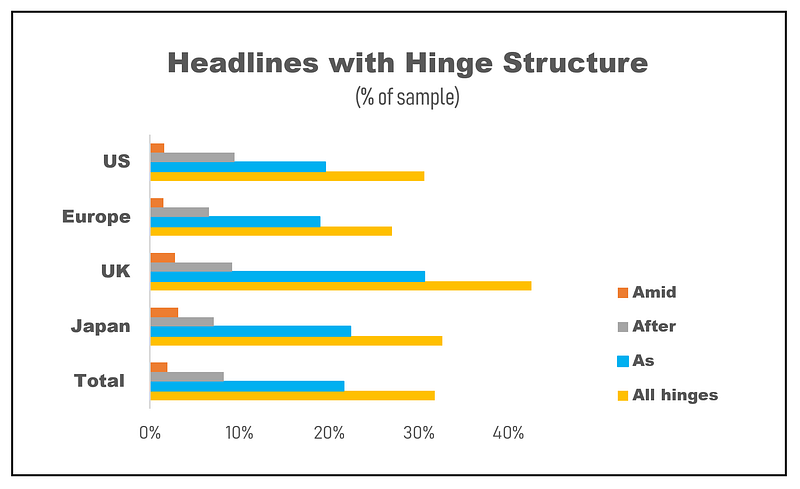
However, in support of the argument that writing conventions are at play, notice the variance is not that significant. Pretty consistently across markets, about 30% of the headlines adhere to this hinged structure, thereby offering extractable information.
Of course, to actually extract said information, one needs to parse the two parts of the headline, and specifically — identify the verbs hanging to the hinge’s left. To do this, I’ve used the SpaCy standard parser. Overall this approach works well, because both the left and right parts of the broken-up headline tend to be simple-structured sentences. As a result, we end up identifying a list of about 300 (lemmatized) verbs.
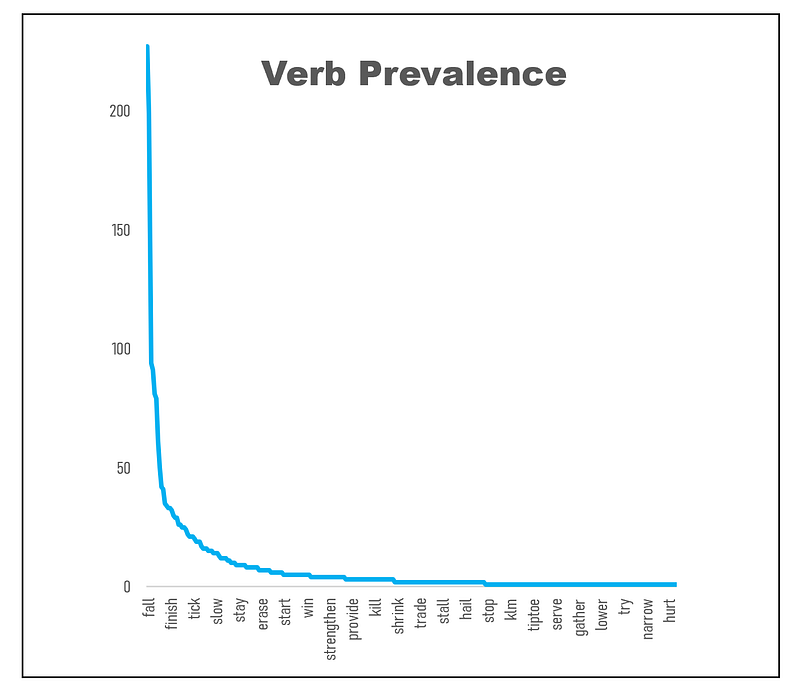
Their prevalence within the sample matches an exponential distribution, so a limited number of verbs get used a lot, and there’s a long tail of verbs that are only used once or twice.
Notice that not all verbs carry a sentiment. Sometimes, the news story itself is of neutral sentiment. But often, it’s because the verb is actually part of a verb compound, comprised of a verb and an up/down preposition: markets ticked up, the Dow ended lower. Extending the sentiment tagging to include such instances is not difficult.
The top 15 most frequently-used verbs are:

Fun observation — lower down the list, we find the seemingly-bizarre appearance of the verb “feed”. Can you guess why it shows up? (hint: news reports on past events). It’s a nice exercise thinking of how to bulk-fix this parsing problem.
Finally, we’re now in a position to assess the extent to which the M-L dictionary might be lacking. Limiting ourselves to sentiment-carrying verbs that have appeared in more than one headline, we can look to see whether these appear in the dictionary, and if they do, whether they carry a similar sentiment.
In our sample, there are 45 such lemmatized verbs, which correspond to 80 different verbs in their original form. On the plus side, all the sentiment-tagged verbs are in the dictionary. Further, there is no instance where the dictionary flips our sentiment tagging (saying something is positive when we’ve tagged it negative or vice versa).
On the other hand, most verbs are simply not sentiment-tagged.
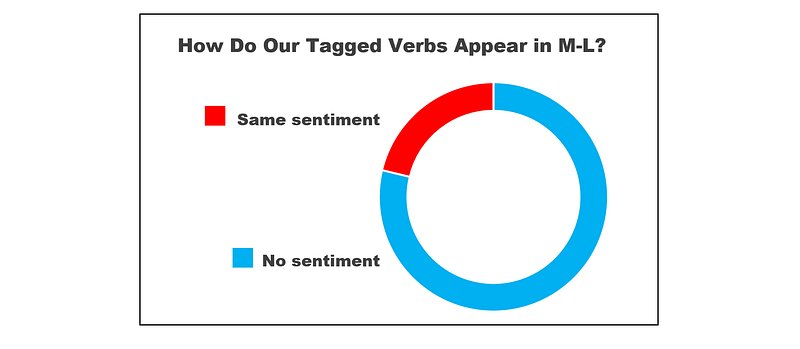
In particular, when looking at the sentiment-carrying lemmatized verbs within our top 15 list (recall that owing to the exponential distribution, these verbs cover most of the headlines), only one — ‘gain’ — is sentiment-tagged by the M-L dictionary.
It makes sense in the context of financial statements, on which the M-L tagging is based. As discussed above, the verb ‘climb’, for example, is not an absolute positive; within financial statements, if manufacturing costs were to climb, that would be a negative.
All this appears to suggest that, when sentiment-tagging financial news headlines that are written in this hinged structure, relying on the M-L dictionary will miss lots of important information. Seeing as so many news stories adhere to this structure, that’s quite a significant loss.
3. What this tells us about domain expertise
It’s a seductive belief that, if you can just get your algorithm to be good enough, clever enough, it’ll be able to hack at an NLP task irrespective of the domain.
And who knows? One day, that might just be the case.
But right now, it isn’t.
And so, the above discussion is useful when asking: what value does domain expertise actually add?
Often, domain expertise is considered useful at the vocabulary level. For example, earlier we’ve looked at the verb ‘moderate’, which — in markets context — people use as synonymous to ‘fell’ when trying to avoid spooking investors.
More broadly, vocabulary domain expertise means applying external knowledge to determine that some terms are more important than others, or that words take on a particular meaning.
That’s all part of speaking a sociolect, a sub-language that signals belonging to a specific social community. But a specialised vocabulary (including jargon) is only one layer, and the patterns with which ideas are laid out is equally a part of a sociolect. Think of lawyers, who seem to speak English, yet do so in these rigid, convoluted sentence structures.
Solid domain expertise allows you to recognize these patterns — and make use of them to extract information.
With this article, we’ve applied this principle to the financial markets sub-domain. As a result, we’ve been able to improve on existing sentiment analysis tools, and generate automatic sentiment labeling that scales.
This was done using the rather old-fashioned approach of word lists and menial tagging (of a small set of verbs), along with a couple of rules thrown in. Yet it showed how this work can support more advanced deep-learning techniques.
Personally, I find it rather sweet that we can end up gaining so much semantic value out of this teeny tiny syntactic unit, merely owing to writing conventions.
Don’t you?
Sources: 1. Loughran, T. and McDonald, B. (2011) When Is a Liability Not a Liability Textual Analysis, Dictionaries, and 10-Ks. Journal of Finance, 66, 35–65.