
A Major Challenge in Machine Learning Applications: Interpretability
Misconceptions Surrounding Rule Generation
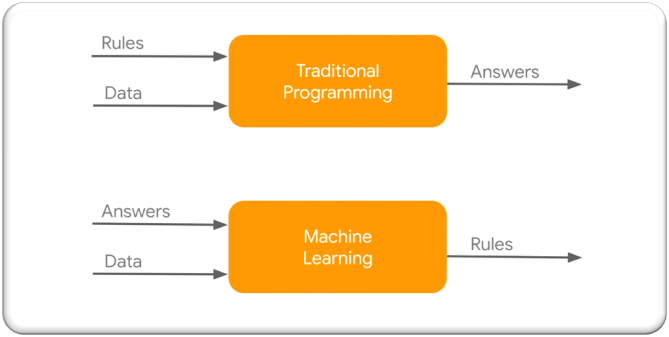
A common misconception exists regarding the functioning of machine learning, particularly the belief that it “produces rules” based on data and answers. It is crucial to clarify that machine learning does not generate explicit, easily interpretable rules. Instead, it learns intricate patterns and associations within the data to facilitate predictions or generate answers. These patterns, often perceived as rules, might be challenging for humans to decipher, highlighting one of the fundamental challenges in machine learning. Machine learning is frequently perceived as a “black box,” providing answers without revealing its underlying mechanisms. This opacity can pose difficulties when attempting to understand why the answers provided are not as expected.
Training and Testing in a Black-box Model
The diagram aptly illustrates the training process in machine learning. During training, the machine learning algorithm refines its internal parameters (often likened to rules) to minimize the disparities between its predictions and the provided correct answers. Unlike traditional programming, which involves the explicit provision of rules by a programmer, both traditional programming and machine learning necessitate testing. The testing phase is pivotal to evaluate the model’s ability to generalize and furnish accurate responses to novel, unseen data. In traditional programming, incorrect answers in the testing phase prompt programmers to engage in debugging and rectify the program. However, in machine learning, if the answers during testing are deemed insufficiently “correct,” additional training is required to self-correct the rules.
In other words, machine learning may not always be more efficient due to the potentially protracted training periods, dependent on the complexity of rules that can be specified by programmers. Nonetheless, the time consumed is not the most critical shortcoming.
Implications Arising from the Distinctions Between Machine Learning and Traditional Programming
While many people underscore the advantages of machine learning, such as its adeptness at recognizing intricate patterns and adapting to fresh data (as shown in the Pros section of the Table below), it is equally vital to acknowledge potential drawbacks. These encompass the risk of incorrect outputs if the training data is flawed, the model struggles with generalization, or it absorbs biased patterns from the data. However, the challenge of incorrect outputs can be mitigated through retraining with high-quality data.
Another, more vexing shortcoming of machine learning applications, however, remains challenging to address: interpretability (see the Cons section of the Table below).

Black-Box Models Versus Interpretability
Despite the earlier diagram’s portrayal, the “rules” deduced by machine learning algorithms are typically encapsulated within black-box models, rendering them challenging to interpret, even if one has access to all the model’s details. Models like deep learning and gradient boosting are often deemed non-interpretable, earning them the moniker “black-box models” due to their complexity, which exceeds human comprehension. Grasping the entire model simultaneously and comprehending the rationale behind each decision is practically impossible for humans.
However, it is worth noting that, as emphasized by FICO, “without explanations, [predictive] algorithms cannot meet regulatory requirements, and thus cannot be adopted by financial institutions and would likely not be accepted by consumers.”
This interpretability challenge within machine learning applications has garnered increased attention in the market. Interpretability frameworks such as LIME and SHAP have been developed and are frequently cited as means of unraveling the logic behind the outputs of black-box models.
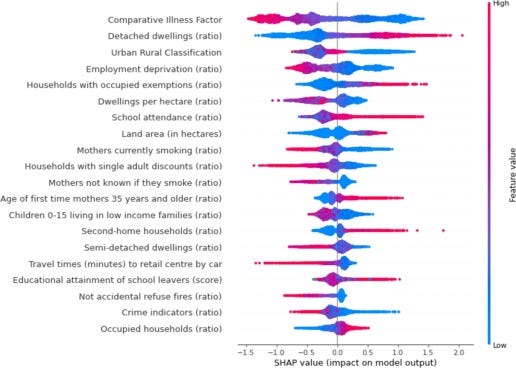
Nonetheless, it solely presents the SHAP value, which illustrates the impact of each input on the model’s output. It remains a formidable challenge to elucidate the mechanisms behind these outcomes. Unlike a polynomial equation model where individuals can input values for the input parameters into the equation to derive the output, a machine learning model does not lend itself to manual verification. Even more concerning, a majority of machine learning applications continue to operate as black-box systems, offering no avenues for interpretability.
AVM as an Example

Automated Valuation Models (AVMs) are just one example of how machine learning has been incorporated into the real estate industry. The rise of iBuyer companies, which use machine learning algorithms to make instant offers on houses, is another compelling illustration of how technology is transforming the property market. These platforms aim to streamline the process of buying and selling homes by providing quick and automated valuations for properties. While this approach offers convenience, it also brings to light several issues related to interpretability and transparency.
iBuyer platforms, like Opendoor and Zillow Offers, utilize vast datasets and machine learning algorithms to determine property values swiftly. These algorithms analyze a myriad of variables, such as location, property condition, and market trends, to arrive at a valuation. However, just like AVMs, the inner workings of these algorithms often remain hidden from users and even real estate professionals.
The challenge of interpretability arises when homeowners or real estate agents attempt to comprehend and trust the valuation provided by iBuyers. For instance, when an iBuyer offers a price to purchase a home, homeowners may wonder how the platform arrived at that specific figure. This lack of transparency can lead to skepticism and hesitation.
In cases where homeowners and iBuyers do not see eye to eye on valuations, disagreements can occur. This can result in protracted negotiations or the home remaining unsold. As a result, the entire home-selling process, which was intended to be expedited through iBuyer platforms, may experience delays and complications due to interpretability issues.
Moreover, the property market, much like the broader economy, is subject to fluctuations. The outbreak of unexpected events, such as the COVID-19 pandemic, can lead to rapid changes in the real estate landscape. For iBuyer platforms and their machine learning algorithms, adapting to such unpredictability can be challenging. Traditional programming often requires updates and adjustments made by human programmers who possess an understanding of the market’s nuances. In contrast, machine learning systems may struggle to adapt swiftly to these changing circumstances, potentially leading to incorrect valuations and decisions.
One of the most significant implications of using machine learning in real estate, as seen in both AVMs and iBuyer platforms, is the need for transparency and interpretability. For real estate professionals and homeowners, it is vital to understand how these algorithms reach their valuations. The absence of such insight can create a barrier of mistrust, hindering the widespread acceptance and adoption of these technologies.
To address these challenges, it is essential to develop models that are not just accurate but also interpretable. Researchers and data scientists are actively working on techniques to make machine learning algorithms more transparent. Methods like Local Interpretable Model-Agnostic Explanations (LIME) and SHapley Additive exPlanations (SHAP) are emerging as ways to interpret the outputs of black-box models like deep learning and gradient boosting.
For iBuyers, improving interpretability means providing users with a clear breakdown of how the valuation was determined. It involves explaining the significant factors that influenced the valuation and demonstrating how these factors align with market conditions.
In the property market, understanding the valuation process is critical for informed decision-making. Whether it’s a homeowner deciding to accept an iBuyer offer or a buyer determining a reasonable purchase price, transparency and interpretability play a pivotal role in building trust and confidence in the technology-driven real estate landscape.
In conclusion, while machine learning holds great promise in the real estate industry, it also presents challenges related to interpretability. AVMs and iBuyer platforms can provide efficient and accurate valuations, but the lack of transparency surrounding their algorithms can lead to mistrust and complications. The solution lies in developing models and approaches that prioritize interpretability, ensuring that both professionals and consumers can understand and trust the decisions made by these systems. As technology continues to shape the future of real estate, striking a balance between automation and transparency becomes essential for the industry’s growth and success.