

A Gentle Introduction to Graph Embeddings
Instead of using traditional machine learning classification tasks, we can consider using graph neural network (GNN) to perform node classification problems. By providing an explicit link of nodes, this classification problem is no longer classified as an independent problem but leveraging graph structures such as the degree of nodes. The usefulness of graph properties assumes that individual nodes are correlated with other similar nodes.
Typically example is a social media network. Imagine how Facebook connects you and somebody else based on what post you like, where you check-in etc. A graph is capable to represent this kind of relationship and we can leverage it to train GNN. Detail use cases of GNN will be covered in later stories.
We will explore the Graph Embeddings this time. The Graph Embeddings, same as word embeddings in NLP, uses low dimensional representation to represent entities with semantic similarity. In other words, similar entities (e.g. both apple and orange are fruit) have similar vector representations.
Model
Lots of researchers studied how can GNN works. TransE (Border et al., 2013), RESCAL (Nickle et al., 2011), DistMult (Yang et al., 2015) and ComplEx (Trouillon et al., 2016) will be introduced in this section.
TransE
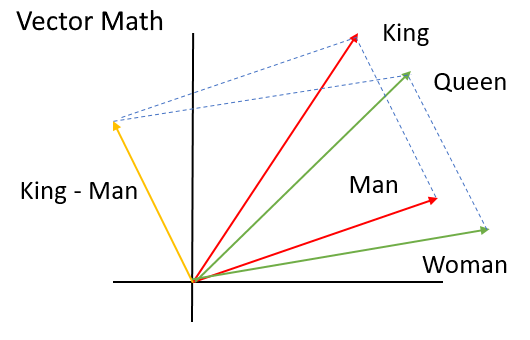
If you are familiar with word2vec (Mikolov et al., 2013), you can assume that TransE (Border et al., 2013) is similar to word2vec. Giving subject entity (aka head), relation and object entity (aka tail), object entity embeddings should be close to the subject entity embeddings plus relation embeddings if the subject entity is similar to the object entity. Otherwise, the subject entity should be far away from the object entity.
RESCAL
RESCAL (Nickle et al., 2011) uses multiple matrics to represent the relations among entities. Assume that the total number of entity is n while the total number of a relation is m, the total number of parameters is n x n x m. If there is no relation between an entity i and entity j, the value is set to zero.
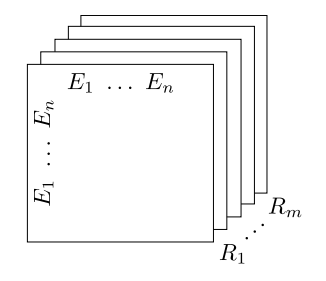
One of the challenges of RESCAL (Nickle et al., 2011) is scalability. Since the matrics store relation between every subject entity and object entity, a huge amount of parameters are introduced.
DistMult
DistMult (Yang et al., 2015) is similar to RESCAL (Nickle et al., 2011) except for the number of parameters. Instead of use complex matrics, Yang et al. reduce the number of relations parameters by using a diagonal matrix only (i.e. restricted matrices). It requires fewer parameters for training. A number of parameters of RESCAL can be more than DistMult ten to a hundred times.
DistMult enjoys a low number of parameters (same as TransE) to achieve superior performance. In computation, DistMult is similar to TransE while DistMult uses multiplicative interaction while TransE uses addictive interaction.
One of the problems of DistMult is that it can only model symmetric relations but not suitable for general knowledge graphs as it simply the relations by using a diagonal matrix.
ComplEx
To handle symmetric and antisymmetric relations, Trouillon et al., (2016) proposed to use complex embeddings (both real and imaginary parts). Symmetric relations mean sRo = oRs if a does not equal to b while s is a subject entity, R is relation and o is object entity. If it holds if a is equal to b only, it is antisymmetric relations.

The scoring function is similar to DistMult as a diagonal matric is introduced to score vectors. DistMult scoring function helps to calculate the symmetric part while the antisymmetric part is handled by imaginary embeddings.
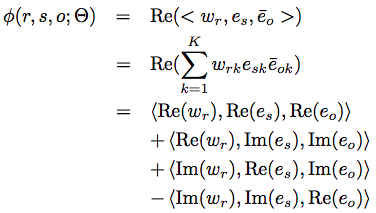
Training Objective
Link prediction(Nowell and Kleinberg, 2004) is one of the ways to train an entity embeddings. Given defined nodes relations (i.e. graph), we can generate negative samples (i.e. corrupted relations, we will discuss in a later section) to disturb the model and allowing a model to learn relations among entities.
Once we have both positive samples and negative samples, we can use ranking loss, logistic loss or softmax loss as loss function to score those samples.
- Ranking Loss: Loss will be introduced if positive samples score is larger than negative samples and small margin error.
- Logistic Loss: Instead of ranking samples, it can predict the probabilities of edge existence.
- Softmax Loss: Understand the distribution of the probabilities of entities' connections.
Large Scale Training
We go through several unsupervised learning methods to train entity embeddings. Let imagine that you are working for Facebook or Uber and having an extremely large amount of nodes and edges. How can we fit those data into memory? Lerer et al. released a PyTorch-BigGraph (PBG) that supports million of nodes and trillion of edges in 2019. PBG provides a way to perform distributed execution across multiple machines.
Partition
The first step of performs distributed execution is partitioning data. Step are:
- Perform partition to each entity (if necessary).
- Divided edges to buckets. Edges will be put into the bucket (p1, p2) if edges connecting with source partition p1 and destination partition p2.
- Shuffle bucket order within a partition. It is important that at least one of partitions (i.e. p1 or p2 in the bucket (p1, p2)) was trained to expect the first. Empirically, it is better than a random order.
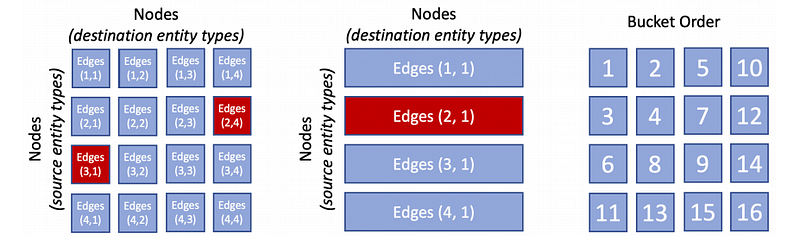
There are 2 fundamental changes when performing distributed execution. Negative samples are drawn from the same partition and edges are no longer sampled independently and identically distributed (i.i.d.). One of the impacts is suffering from slower convergence. We will come again these problems in later sections.
Distribution
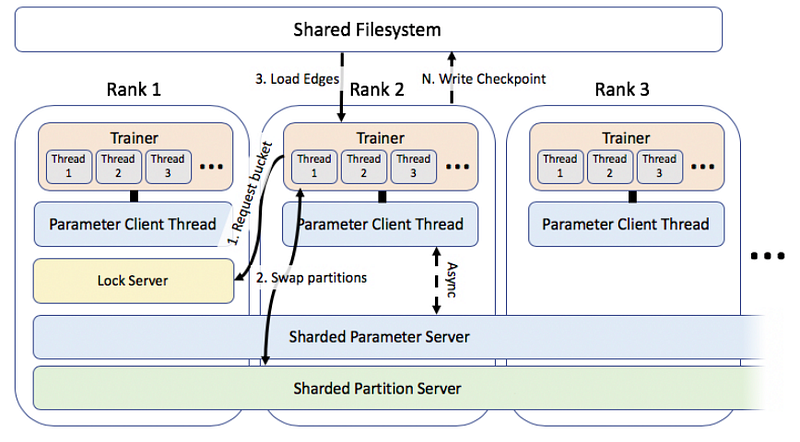
After partitioned data, it can be sent to different machines for parallel training. The traditional mechanism uses parameter servers to store embeddings information and updating the parameters asynchronously after gradient sent from workers. However, one of the drawbacks is the huge network bandwidth overhead. Therefore, Lerer et al. proposed a solution to overcome it.
Lock Server is proposed to lock partitioned embeddings in a single machine. If partitions are disjoint, it can be trained parallel, otherwise, embeddings will be locked in Lock Server. Only shared parameters will be synchronized.
Negative Sampling
3 negative sampling methods are available in PBG. All negatives method is the simplest way which is generating all possible edges for all data. Same-batch negatives method is only generating all possible edges within a batch. It reduces the total number of negatives and network bandwidth overhead. The last method is Uniformly-sampled negatives which generates a fixed number of negatives samples within a batch. You may visit documentation to a deeper understanding of the negative sampling methods.
Take Away
- PyTorch BigGraph (PBG) supports CPU only up till now (Nov 2019) while authors are working on GPU support. Stay tuned.
- PyTorch BigGraph (PBG) implemented TransE, RESCAL, DistMult and ComplEx model (with small modification). In other words, you just need to provide correct format data, PBG will do the rest of them for you.
- Trouillon et al., (2016) evaluated the impact of the number of negatives generated per positive training sample. They found that 50 negative examples per positive training sample are a good trade-off between accuracy and training time.
- The aforementioned model and loss function are re-implemented in PBG, you may simply call the library to train graph embeddings.
Extra Reading
- PyTorch BigGraph source repository
- Graph Learning in Uber Eats
About Me
I am Data Scientist in the Bay Area. Focusing on the state-of-the-art in Data Science, Artificial Intelligence, especially in NLP and platform related. Feel free to connect with me on LinkedIn or follow me on Medium or Github.
Reference
- D. N. Nowell and J. Kleinberg. The Link Prediction Problem for Social Networks. 2004
- M. Nicke, V. Tresp and H. Kriegel. A Three-Way Model for Collective Learning on Multi-Relational Data. 2011
- S. Bhagat, G. Cormode and S. Muthukrishnan. Node Classification in Social Networks. 2011
- A. Borders, N. Usunier and A .G. Duran. Translating Embeddings for Modeling Multi-relational Data. 2013.
- B. Yang, W. T. Yih, X. He, J. Gao and L. Deng. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. 2015
- T. Trouillon, J. Welbl, S. Riedel, E. Gaussier and G. Bouchard. Complex Embeddings for Simple Link Prediction. 2016
- A. Lerer, L. Wu, J. Shen, T. Lacroix, L. Wehrstedt, A. Bose and A. Peysakhovich. PyTorch-BigGraph: A Large-scale Graph Embeddings Framework. 2019