
A Comprehensive Guide to Distributed Caching
An essential website requires a web server to receive requests and a database to write or read data. However, this simple setup will only scale once you optimise your database or change the overall database strategy if you receive millions of requests per second. Is that correct? The database eventually reached its limit on Active Connections and had difficulty managing concurrent requests.
One solution to consider when looking to improve a system’s scalability is caching. Caching is a widely used technique that can be found in many different areas, including web applications, databases, media streaming, e-commerce, gaming, cloud computing, and mobile applications.
Before delving deeper into caching, it is essential first to understand its advantages over using a traditional database alone. Caching can offer several benefits that a database alone may not provide:
- Speed: Caching can significantly improve the speed of an application by storing frequently accessed data in memory, which can be accessed much faster than data stored on disk.
- Scalability: Caching can help scale an application by distributing the load across multiple cache servers, which can handle many requests.
- Reducing the load on the database: Caching can reduce the load by storing frequently accessed data in memory, thus reducing the number of requests to the database.
- Improving availability: Caching can help improve an application’s availability by providing a backup of frequently accessed data in case the database becomes unavailable.
- Cost: Caching can reduce costs by reducing the number of requests to the database, which helps reduce the need for expensive database resources like CPU, memory and storage.
- Data Consistency: Caching can improve consistency by storing the most recent data and ensuring that the data is always up to date.
Caching Strategies
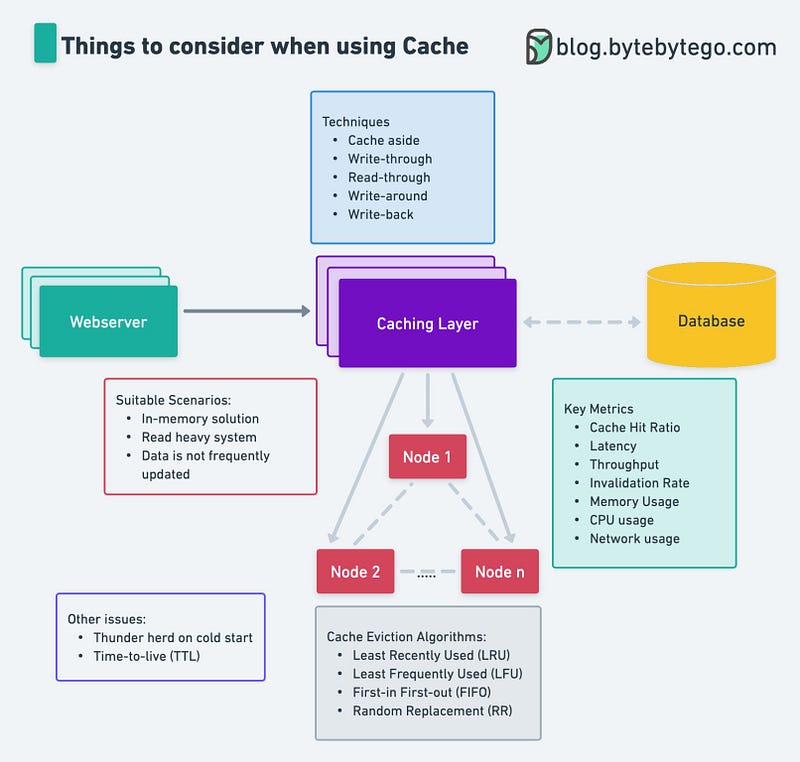
Let’s look at the caching solutions available to us and determine which one best meets our requirements. Caching in a high-scale application can be a challenging task. Here are a few strategies that can be used to cache in a high-scale application:
- In-memory Caching: In-memory caching stores the cache data in the memory, allowing faster access times. This strategy is helpful for high-scale applications that handle a high volume of read operations.
- Cache Sharding: Cache sharding is a technique that divides a large cache into smaller partitions, which can be stored on different servers. This can help to distribute the load and reduce the risk of a single point of failure. Each shard is responsible for a specific subset of the data accessed by a particular key.
- Distributed caching: Distributed caching allows you to cache data across multiple servers, which can help reduce the load on any one server and improve the system’s overall performance. Distributed caching systems can be further divided into replicated and partitioned caching. Replicated caching stores a copy of the data on multiple servers, while partitioned caching divides the data into smaller chunks and stores them on different servers.
- Content Delivery Networks (CDNs): CDNs are servers distributed across the globe. They can cache and deliver user content based on their geographic location.
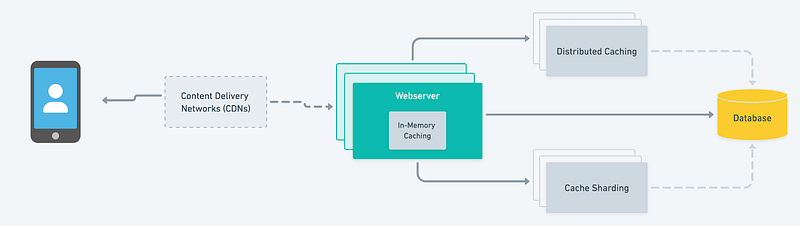
When it comes to caching, it’s important to note that the choice of strategy will depend on the unique needs and requirements of the application. It’s beneficial to test various scenarios and determine the best fit for the specific use case. It’s also possible that a hybrid approach, such as combining in-memory caching with distributed caching or cache sharding, may be necessary for high-scale applications where data consistency is not a primary concern. Overall, the caching strategy should be tailored to the application’s specific needs.
This article will focus on distributed caching, but the concepts discussed can also be applied to other areas.
Distributed Caching
Distributed caching is a technique that allows you to cache data across multiple servers rather than on a single server. This can reduce the load on any server and improve the system’s overall performance.
Several key components make up a distributed caching system:
- Cache nodes are servers that store and manage cached data. They can be configured as a cluster or grid and communicate with each other to keep the cached data consistent.
- Cache clients are the applications or services that interact with the cache nodes to read and write data.
- Load balancer: This component distributes the load across the cache nodes. It can be configured to use various algorithms such as round-robin, least connections, or IP hash. You can read more about load balancers here.
These components provide high availability, scalability, and system performance.
A wise man said:
There are only two hard things in Computer Science: cache invalidation and naming things. - Phil Karlton
Strategies for Cache Invalidation
Cache invalidation is the process of removing stale or outdated data from a cache. This is an essential aspect of caching because it ensures that the data in the cache is up-to-date and consistent with the source data.
Now that we understand the importance of cache invalidation, let’s focus on one critical metric used in this process: Time-to-live (TTL). Each cached item is assigned a timestamp and a TTL value. Once the TTL expires, the corresponding item is automatically removed from the cache.
And how do we remove the item from the cache? Several cache eviction strategies can be used to improve the performance of a system, including:
- First In, First Out (FIFO): This strategy removes the oldest entry in the cache when a new one needs to be added.
- Least Recently Used (LRU): This strategy removes the entry that has been in the cache the longest without being accessed.
- Most Recently Used (MRU): This strategy removes the entry accessed most recently.
- Least Frequently Used (LFU): This strategy removes the entry that has been accessed the fewest times.
- Random Replacement (RR): This strategy randomly selects an entry to remove when a new one needs to be added. It is suitable for applications where it is hard to predict which data is likely to be re-accessed in the future.
You can also handle cache invalidation from applications as well by using the below essential and widely accepted techniques:
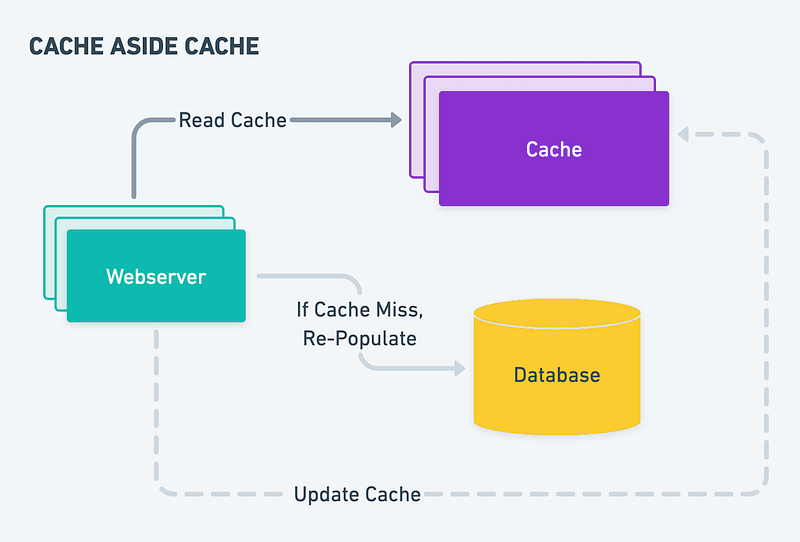
Cache-aside cache
This strategy involves checking the cache for the requested data before going to the source data (e.g. a database). If the data is not found in the cache, it is retrieved from the source data and stored in the cache for future use.
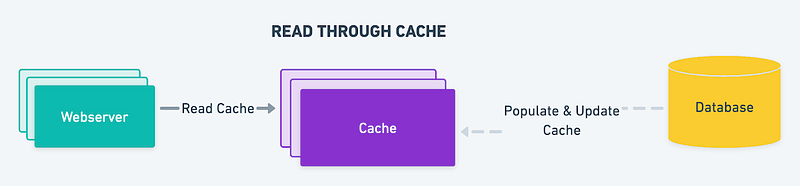
Read-through cache
In a read-through cache, when a read operation is performed, and the data is not found in the cache; the cache will automatically fetch the data from the backing store and store it in the cache before returning it to the requestor. This can improve read performance by reducing the number of read operations required from the backing store. In cache-aside, the application retrieves data from the database and stores it in the cache. In contrast, the library or the cache provider typically handles the read-through caching strategy, the logic for fetching data from the database and populating the cache. The read-through caching strategy is well suited for scenarios where the same data is frequently requested, and the workload is read-heavy. However, one disadvantage of this strategy is that the first time the data is asked for, it will always result in a cache miss, which incurs the extra penalty of loading data to the cache. Developers may deal with this by pre-loading the cache manually, also known as “warming” the cache. As with cache-aside, it’s also possible for the data to become inconsistent between the cache and the database, so the choice of write strategy is essential.
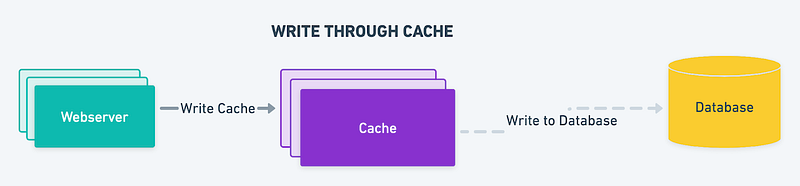
Write-through cache
In a write-through cache, when a write operation is performed, the data is written to both the cache and the backing store. This ensures that the data is always consistent between the two but can result in slower write performance due to the additional write operation to the backing store.
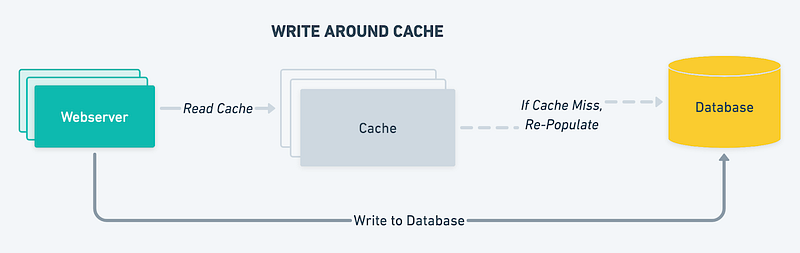
Write-around cache
In a write-around cache, write operations bypass the cache and are written directly to the backing store. This can improve write performance but can result in the cache not being up to date with the latest data.
Write-back / Write-Behind cache
In a write-back cache, write operations are written to the cache and marked as “dirty.” The data is eventually written back to the backing store, but this can be done at a later time and may be done in a batch with other dirty cache entries. This can improve write performance, but if the cache is lost (e.g. due to a power failure), any dirty cache entries will be lost.

Push-based invalidation: This technique uses a push notification system to notify the cache nodes when the data in the source data changes. This technique can be used in the case of distributed caching, where the data is partitioned among different cache nodes.
Polling-based invalidation: In this technique, the cache nodes periodically check the source data for changes and invalidate the stale data.
Optimizing the Distributed Caching
It should be noted that the implementation of distributed caching is a complex process and requires a significant amount of expertise to maintain it properly. There are a few strategies that can be used to optimize distributed caching:
- Data Partitioning: Dividing the data into smaller partitions and distributing them across multiple servers can help reduce the load on any one server and improve the system’s overall performance.
- Consistency: Data consistency is vital in a distributed caching system. Consistency can be achieved using techniques like data replication and quorum-based protocols.
- Load Balancing: Distributed caching systems must be able to handle the load of multiple requests. Load balancing can be used to distribute the load across multiple servers, which can help improve the system’s overall performance.
- Invalidation: Distributed caching systems need to have a way to invalidate stale or outdated data. This can be achieved by setting a time-to-live (TTL) value for each cache entry or using a distributed cache invalidation protocol like the invalidation-based protocol.
- Fault-tolerance: Distributed caching systems must be able to handle server failures without losing data.
- Monitoring and Management: Monitoring and managing distributed caching systems are essential to detect and resolve issues.
Key Metrics for Monitoring
A poorly performing cache can negatively impact the application’s performance by slowing down data retrieval because a significant amount of essential data is stored in the cache. To ensure optimal performance, it’s crucial to periodically evaluate the cache’s usage patterns and make timely upgrades or maintenance to the system as needed. This will ensure that the cache is functioning as intended and that the application continues to perform well.
When monitoring and measuring the performance of a distributed caching system, there are several key metrics that you should consider:
- Cache Hit Ratio: The ratio of cache hits to cache requests. A high cache hit ratio indicates that the cache is working effectively, while a low cache hit ratio may indicate that the cache is not being used effectively.
- Latency: The time it takes for a request to be fulfilled by the cache. Lower Latency indicates better performance.
- Throughput: The number of requests that the cache per second can handle. High throughput indicates better performance.
- Memory Usage: The amount of memory used by the cache. A high memory usage may indicate that the cache is full or needs to be used more effectively.
- Data Consistency: The consistency of data across the different cache nodes. A high consistency indicates better performance.
- Invalidation rate: The rate at which invalidations are happening in the cache. A high invalidation rate may indicate a problem with the eviction policy or the application requesting invalidation too frequently.
- Error rate: The rate of errors that occur when interacting with the cache. A high error rate may indicate a problem with the cache or the application.
- Replication rate: The rate at which the data is replicated across the nodes. A high replication rate may indicate that the data is frequently changing or the replication interval is too low.
Remember that the most important metric can vary depending on the use case; for example, for a real-time application, the Latency will be more critical than the invalidation rate, and so on.
Security Challenges
Ensuring security in a distributed caching system can be a challenging task; here are a few strategies that can be used to enhance security:
- Authentication: Requiring authentication for access to the cache can help to prevent unauthorised access to the cache. This can be achieved using techniques like user name and password authentication or tokens.
- Encryption: Encrypting the data stored in the cache can help to protect it from unauthorised access. This can be achieved using encryption algorithms like AES or SSL/TLS for communication between cache nodes.
- Authorization: Authorizing access to the cache based on user roles or permissions can help to prevent unauthorised access to the cache. This can be achieved using techniques like role-based access control or tokens.
- Network Security: Securing communication between cache nodes is essential. This can be achieved using firewalls and VPNs or secure protocols like SSL/TLS.
- Data validation: validating the data before storing it in the cache to avoid storing malicious data.
- Auditing: Keeping track of the users who access the cache and their actions can help detect and prevent unauthorised access.
- Monitoring: Regularly monitoring the cache for suspicious activity, such as unusual traffic patterns or failed login attempts, can help to detect and prevent unauthorised access.
- Regularly updating the software: Regularly updating the software of the cache system can help fix any known vulnerabilities and enhance the system’s security.
It’s worth noting that security is a continuous process, and it’s essential to continuously monitor and update security measures to keep up with new threats and vulnerabilities.
Handling Errors
An additional consideration is that while setting up the cache is important, it’s equally crucial to properly handle errors to ensure a positive user experience and optimal application use. Handling errors in a distributed caching system can be challenging; here are a few strategies that can be used to handle the mistakes:
- Failure detection: Detecting failures in a distributed caching system is essential. This can be achieved using ping-pong or heartbeat messages between cache nodes.
- Automatic failover: Automatic failover is a mechanism that allows the cache to automatically switch to a backup cache node in case of a failure. This can ensure high availability and minimise downtime.
- Redundancy: Redundancy is a mechanism that allows the cache to store multiple copies of the data across various cache nodes. This can help to ensure data availability in case of a failure.
- Error logging: Logging errors in the cache can help identify and diagnose issues. This can be achieved using a centralised logging system or sending error notifications to a monitoring system.
- Error handling: Error handling is a mechanism that allows the cache to handle errors gracefully. This can be achieved by retrying, returning error messages or redirecting the request to a backup cache node.
- Monitoring: Regularly monitoring the cache for errors can help to detect and prevent issues. This can be achieved by using monitoring tools like Prometheus or alerting systems that notify when an error occurs.
- Recovery: Recovery is a mechanism that allows the cache to recover from failures. This can be achieved using techniques like replication or data backup and restoration.
In summary, handling errors in a distributed caching system can be challenging. Still, techniques like failure detection, automatic failover, redundancy, error logging, error handling, monitoring, and recovery can help ensure high availability and minimize downtime.
Popular Available Solutions
There are several ready-made solutions available in the market for distributed caching systems. Some popular ones include:
- Memcached: Memcached is a simple, fast and widely used caching solution. It’s best suited for use cases that require simple key-value caching and support for data eviction policies such as LRU.
- Redis: Redis is a more advanced caching solution than Memcached. It supports data structures such as strings, hashes, lists, sets, and sorted sets and also supports advanced features like persistence, replication, and Lua scripting. It’s best suited for use cases that require more advanced data structures and support for data eviction policies such as LRU, LFU, and random eviction.
- Hazelcast: Hazelcast is a distributed caching solution that supports data eviction policies such as LRU, LFU, and random eviction. It also supports distributed data structures such as maps, queues, and topics. It’s best suited for use cases that require support for distributed data structures and support for data eviction policies.
- Couchbase: Couchbase is a distributed caching solution supporting a document-oriented NoSQL database. It’s best suited for use cases requiring caching, a document-oriented NoSQL database, and support for data eviction policies such as LRU and Time to live (TTL).
- Amazon Elasticache and Google Cloud Memorystore are fully managed caching services; they are best suited for use cases requiring fully managed caching service, automatic failover, data replication and built-in monitoring and alerting capabilities.
It’s worth noting that the best solution will depend on the specific needs and requirements of the application, and it’s always good to try different solutions and see which one works best for your use case.
Conclusion
In this conversation, we discussed caching, a technique used to improve the performance and scalability of a system by storing frequently accessed data in memory. We covered different cache strategies such as Time-to-Live (TTL), Write-through, Write-back, Cache sharding and Distributed caching. We also discussed handling errors in a distributed caching system, ensuring security in distributed caching, the applications for different cache strategies and the benefit of caching over the database.
Finally, we discussed Cache invalidation, which removes stale or outdated data from a cache. We discussed different techniques of cache invalidation, such as Time-to-live (TTL), Write-through, Write-back, Push-based invalidation, and Polling based invalidation. It’s worth noting that the choice of the invalidation technique will depend on the specific requirements and the use case, such as the level of data consistency, the scale of the system, and the network communication.
With that, I conclude this learning; I hope you have learned something new today. Please do share with more colleagues or friends. Finally, Consider becoming a Medium member. Thank you!



