
Musk Makes Good on Promise
99% of People Can’t Use It: The Grok-1 Large Model is Now Open Source
How Many GPUs Are Needed to Pre-train Grok-1?

Recently, Musk has fulfilled his promise by open-sourcing both the weights and architecture of the Grok-1 large model!
Grok-1 is a behemoth with an astonishing 314 billion parameters, making it a standout among open-source large models.
However, such a massive model might be too cumbersome for the average user to utilize with ease.
Although Grok-1 has mastered general linguistic abilities, it still requires further fine-tuning for specific scenarios to better tackle a variety of real-world applications.
The good news is that Grok-1 is now available under the Apache 2.0 license, supporting commercial use.
Next, let’s delve into the details and usage scale of this model!
Let’s see what changes and surprises it can bring to our work and lives.
Model Details
Today, I took a look at Grok’s code and have some findings I’d like to share with you all.
Indeed, the Grok model has some unique designs and impressive performances.

First, let’s examine the attention mechanism of the Grok model.
It introduces a unique scaling factor, specifically 30 times tanh(x/30).
This scaling factor acts as a limiter, linearly scaling smaller logit values so they fall within a range of -30 to 30, while larger values are capped within this interval.
Next, Grok opts for an activation function similar to GELU, akin to the Gemma model.
Moreover, Grok has four layers of Layernorm, which is more compared to the two layers in the Llama model.
However, similar to Gemma, Grok performs dimensionality reduction in the final RMS Layernorm layer.
Additionally, I noticed that Grok’s RoPE (Rotary Positional Encoding) exclusively uses the float32 type, consistent with the Gemma model.
In Grok, the RoPE multiplier is set to 1, and QKV (Query, Key, Value) includes biases, but the output layer and MLP (Multilayer Perceptron) layer do not have biases.
Finally, regarding the vocabulary size, Grok’s vocabulary consists of 131072 entries, while Gemma’s vocabulary is larger, reaching 256000.
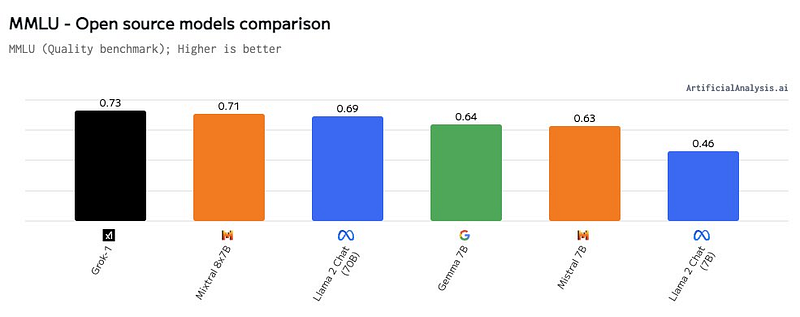
Since October 2023, the xAI team began training this model and achieved a 73% score on the MMLU benchmark, surpassing many well-known models.
Overall, the Grok model indeed incorporates many classic optimization techniques commonly used in large language models, such as RMS norm and RoPE.
It would be even more exciting if the team could open-source versions of the model with fewer parameters to lower the barrier to entry!
Such models would be more readily accepted and applied by the broader developer community.
Usage
How many GPUs are needed to pre-train the Grok-1 large model?
The Grok-1 model consists of numerous expert subnetworks, each with approximately 30B parameters.
There are a total of 2048 such subnetworks.
However, during training, only the two most powerful experts are utilized, so the actual number of parameters to consider is 60B.
I plan to use A100 GPUs, each with 40GB of memory.
But 60B parameters require 240GB of memory! That means at least 6 A100 GPUs are needed.
And that’s not all; training also involves gradient computation and backpropagation.
So, I might need 12 A100 GPUs!
What about fine-tuning Grok-1 without pre-training; how many GPUs would that require?
Using Grok-1 directly? The weights can be downloaded from:
This model is not only large, with 50 checkpoint files, each file ranging from 1–3GB, but also occupies about 300GB of storage space in total.
Given the parameter count exceeds 300B, efficient computation requires using multiple GPUs in parallel.
Drawing on previous estimates with the 314B Moe model, handling a model of this scale would need at least 8 A100 GPUs.
Because of the model’s size, inference speed on a single GPU would be slow.
Parallel processing with 8 A100 GPUs could handle several dozen samples per second.
So, using Grok-1’s pre-trained weights for a chat application would require at least 8 A100 GPUs, with a total memory exceeding 5TB.
Indeed, this is a massive undertaking!
Conclusion
Now that you have a deeper understanding of the Grok-1 large model, including its unique design, performance, and the resources required for its use.
What impact do you think Grok-1 will have on the future? Are you looking forward to seeing more applications and innovations based on this model?
Feel free to share your thoughts!
If you enjoyed this story, feel free to subscribe to Medium, and you will get notifications when my new articles will be published, as well as full access to thousands of stories from other authors.
I am Li Meng, an independent open-source software developer, and author of SolidUI, highly interested in new technologies, and focused on the AI and data fields. If you find my content interesting, please follow, like, and share. Thank you!





