
8 ChatGPT Prompts For Frequently Done Pandas Operations
A quick way to get things done with Pandas

We’ve all heard about ChatGPT. It’s not just on the tech industry’s radar, but also making headlines in the wider press. I frequently get friends reaching out to ask if I’ve heard about it. And yes, I sure have — I use it every day.
Despite some critiques concerning its performance and reliability on simpler tasks, ChatGPT and other large language models (LLMs) excel in a variety of tasks. For me, they’ve served as a significant productivity booster.
Recently, I decided to leverage ChatGPT for the Pandas operations I regularly carry out for data cleaning and analysis. In this article, I’ll share and guide you through 8 prompt examples where I asked ChatGPT how to get things done with Pandas.
If you’d like to learn more about Pandas, visit my course 500 Exercises to Master Python Pandas.
First prompt to define its role:
Prompt: You are a Python tutor teaching me the Pandas library. I will be asking you how to do a particular task with Pandas and expecting you to explain it to me. Also show me the code along with your explanation.
I gave it the structure of the DataFrame in terms of column names and data types before I start asking questions.
Second prompt:
Prompt: Let me first tell you about the DataFrame I have. Then, I will start asking questions. The columns and their data types are given below as a Python dictionary with keys showing column names and values showing the data types.
{‘store’: dtype(‘O’), ‘product_group’: dtype(‘O’), ‘product_code’: dtype(‘int64’), ‘stock_qty’: dtype(‘int64’), ‘cost’: dtype(‘float64’), ‘price’: dtype(‘float64’), ‘last_week_sales’: dtype(‘int64’), ‘last_month_sales’: dtype(‘int64’)}
I will be using a sample dataset that I prepared with mock data. You can download it from my datasets repo. It’s the one named “sales_data_with_stores.csv”.
Here is the DataFrame I have for you to reference easily:
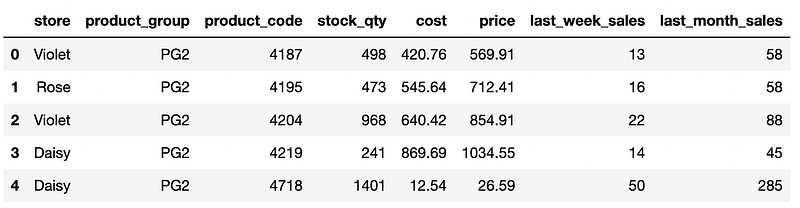
We can now start on Pandas tasks.
Example 1
Prompt: Tell me how to calculate the average last week sales for each store.
This is a simple one-liner but can still take some time to figure out if you just started learning Pandas. Here is the answer of ChatGPT:
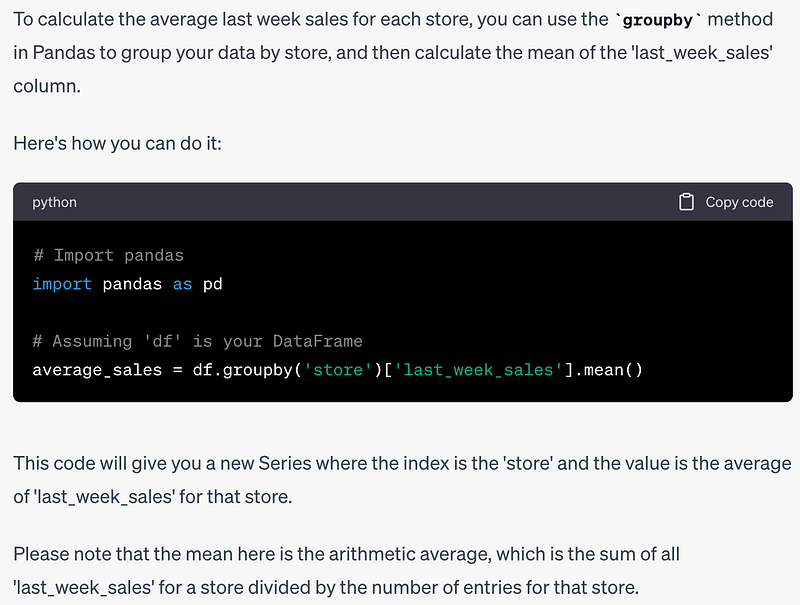
I will be copy-pasting the code snippets in case you want to test it for yourself.
# Import pandas
import pandas as pd
# Assuming 'df' is your DataFrame
average_sales = df.groupby('store')['last_week_sales'].mean()ChatGPT also provided a detailed explanation along with the code in terms of how the task done and the type of the output.
Example 2
Prompt: Tell me how to find the total profit in the last month for each store.
For this task, it needs to figure out how to calculate the profit first. Let’s see it’s response:
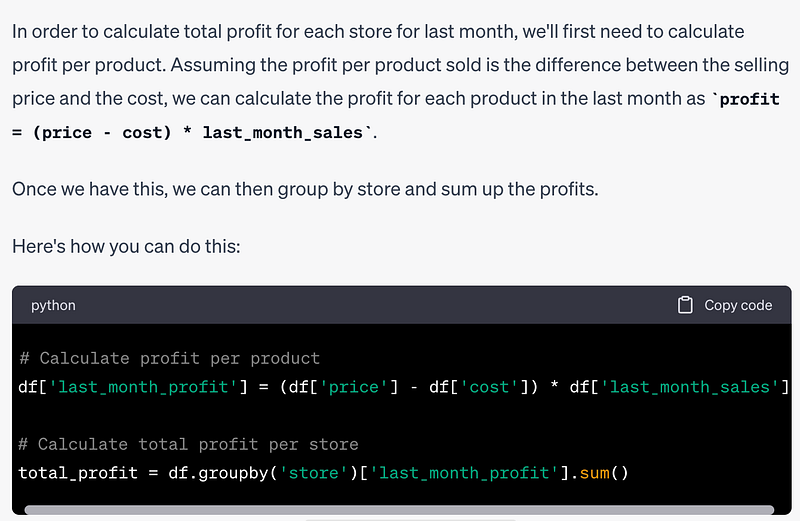
# Calculate profit per product
df['last_month_profit'] = (df['price'] - df['cost']) * df['last_month_sales']
# Calculate total profit per store
total_profit = df.groupby('store')['last_month_profit'].sum()Example 3
When working with real-world data, we often encounter the challenge of missing values. I want to see how ChatGPT tackles a task that isn’t quite as straightforward.
Prompt: There are some missing values in the stock quantity column. I want to replace the missing values with average stock quantity in that store. Tell me how to do this task.
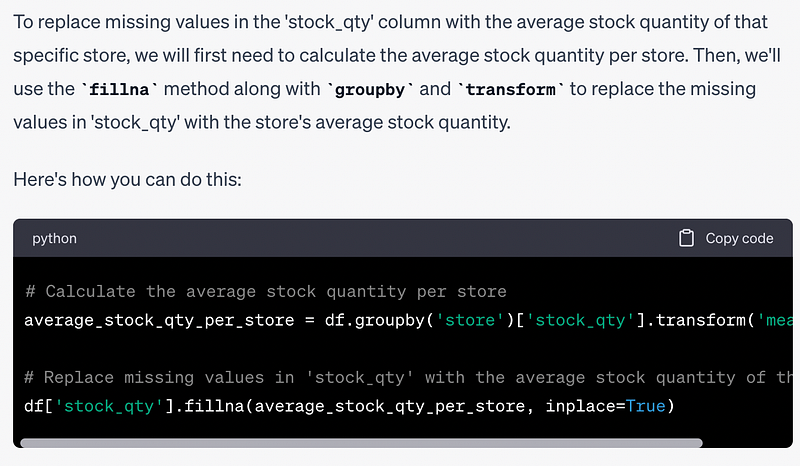
# Calculate the average stock quantity per store
average_stock_qty_per_store = df.groupby('store')['stock_qty'].transform('mean')
# Replace missing values in 'stock_qty' with the average stock quantity of that store
df['stock_qty'].fillna(average_stock_qty_per_store, inplace=True)There are other ways to solve this task but using the transform function is one of the efficient ways. At least, this is how I would do it.
I recently wrote an article that mentions the importance of the transform function. Here is a short snippet from the article that explains why I would do this task using the transform function:
It sounds similar to the apply function but unlike the apply function, transform can return a Series that has the same size as the input, which makes it useful in performing vectorized operations and broadcasting, particularly when used with groupby objects.
Example 4
Prompt: Tell me how to find the top 3 products with the highest sales in last month for each store.
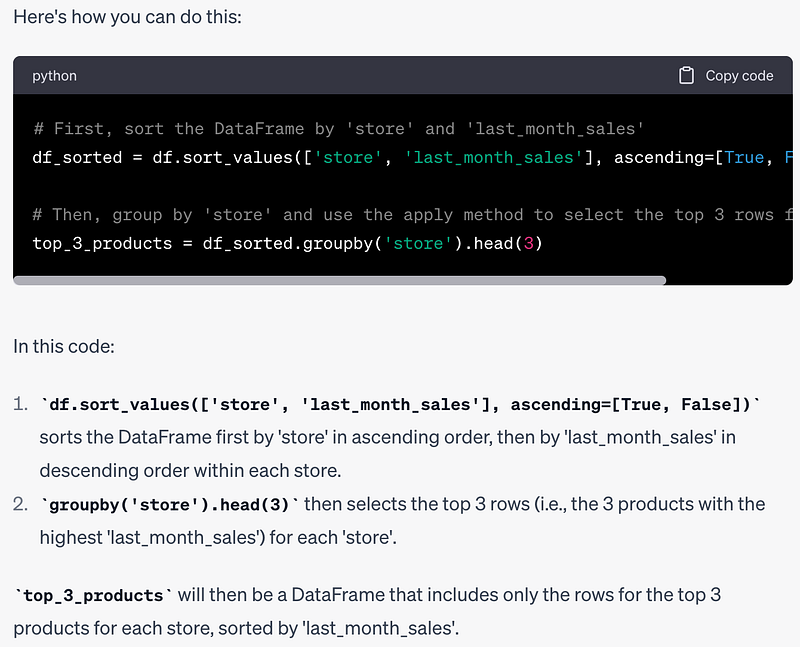
# First, sort the DataFrame by 'store' and 'last_month_sales'
df_sorted = df.sort_values(['store', 'last_month_sales'], ascending=[True, False])
# Then, group by 'store' and use the apply method to select the top 3 rows for each group
top_3_products = df_sorted.groupby('store').head(3)It sorts the entire DataFrame first. We can also do the sorting within each group. Let’s see if ChatGPT knows how to do it.
Example 5
Prompt: Is there another way of doing this task without sorting the DataFrame first?
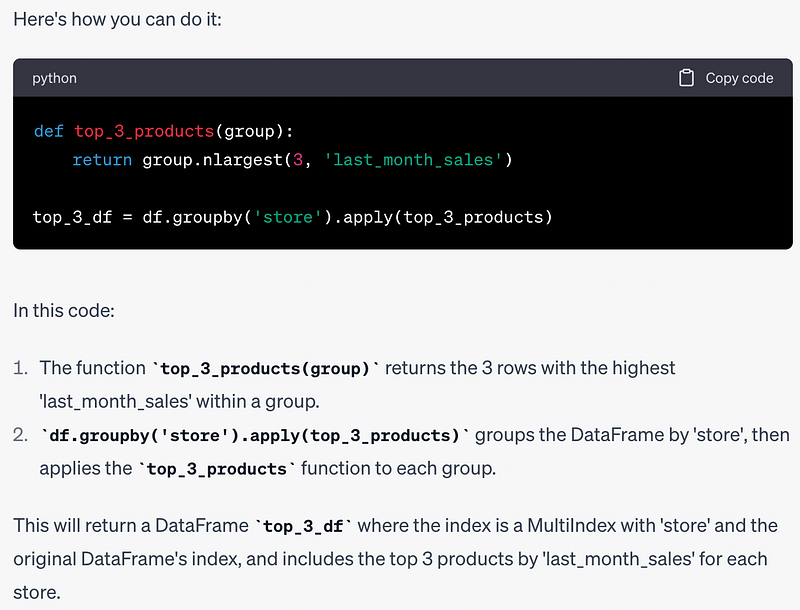
def top_3_products(group):
return group.nlargest(3, 'last_month_sales')
top_3_df = df.groupby('store').apply(top_3_products)It is important to note that sorting the entire DataFrame first might be the more performant way. I just wanted to see if ChatGPT provides different solutions.
Example 6
Prompt: I want to see the last week performance of each stores compared to their last month performance.
This is a simple task but the prompt does not directly tells ChatGPT how to do it. Let’s see how it will perform.
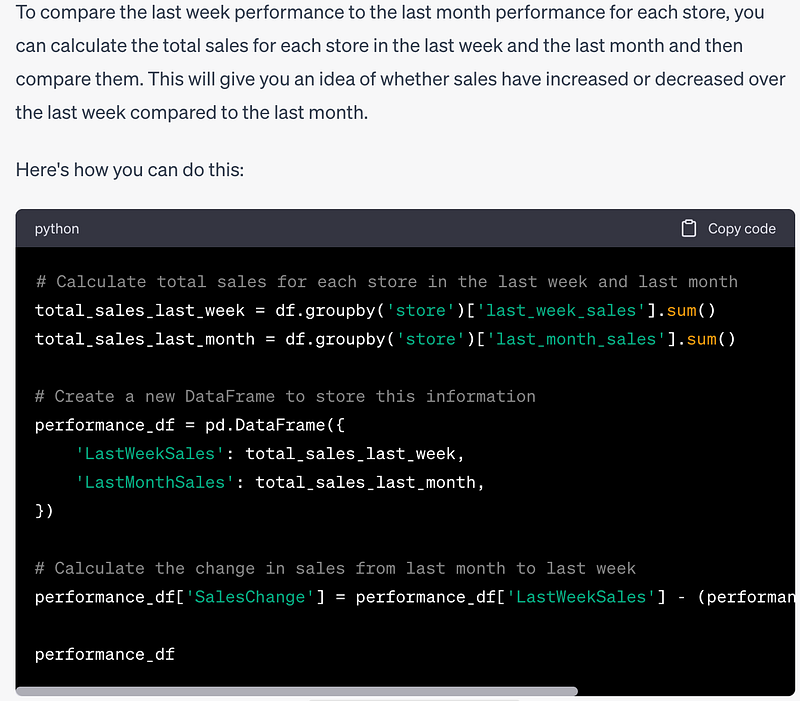
# Calculate total sales for each store in the last week and last month
total_sales_last_week = df.groupby('store')['last_week_sales'].sum()
total_sales_last_month = df.groupby('store')['last_month_sales'].sum()
# Create a new DataFrame to store this information
performance_df = pd.DataFrame({
'LastWeekSales': total_sales_last_week,
'LastMonthSales': total_sales_last_month,
})
# Calculate the change in sales from last month to last week
performance_df['SalesChange'] = performance_df['LastWeekSales'] - (performance_df['LastMonthSales'] / 4)As a response to the performance in the last week compared to the last month, it finds the difference between the last week sales and one fourth of the last month sales, which makes sense.
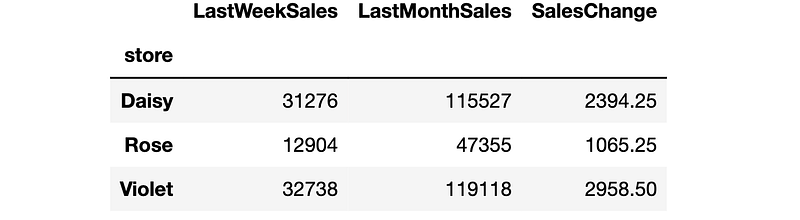
The DataFrame it creates looks like this:
Example 7
Prompt: Create a new column called `critical_stock`, which takes the value of 1 if the `stock_qty` is less than 500, 0 otherwise.
ChatGPT gives me 3 options for this task. Here are the two of them I liked better:

# first option
df['critical_stock'] = df['stock_qty'].apply(lambda x: 1 if x < 500 else 0)
# second option
import numpy as np
df['critical_stock'] = np.where(df['stock_qty'] < 500, 1, 0)Example 8
Prompt: Create a summary of the DataFrame in terms of the size, missing values, data types, and column statistics.
The functions and methods used for summarizing a DataFrame is quite simple but ChatGPT did a great job at organizing them in a nice and clean way.
I’m just copy-pasting the code it generated:
# Import necessary libraries
import pandas as pd
# DataFrame size
print("DataFrame Size:")
print(df.shape)
print("\n")
# Missing values
print("Missing Values:")
print(df.isnull().sum())
print("\n")
# Data types
print("Data Types:")
print(df.dtypes)
print("\n")
# Column statistics
print("Column Statistics:")
print(df.describe(include='all'))Final words
The examples we covered did a small demonstration of how ChatGPT is revolutionizing the way we perform common tasks in data analysis, specifically with Pandas. It is not only increasing our efficiency in completing tasks but also enriching our understanding of the complex operations that can be done with Pandas.
I will be exploring even more ways to employ ChatGPT in my data analytics toolkit and get more complicated tasks done. It is important to note that as the complexity of tasks increases, the way you write prompts start to matter a lot. This is the reason why there is a new discipline emerging, called prompt engineering.
You can become a Medium member to unlock full access to my writing, plus the rest of Medium. If you already are, don’t forget to subscribe if you’d like to get an email whenever I publish a new article.
Thank you for reading. Please let me know if you have any feedback.





