
Can you solve this “Hard” Programming Interview Question: Word Ladder? (Asked at Amazon, Facebook, Google)
I’ll walk through my intuition for how I solved this problem. We’ll start with a pretty naive, simple approach, and then I’ll demonstrate some optimizations you can apply to make this algorithm faster.

Question
A transformation sequence from word beginWord to word endWord using a dictionary wordList is a sequence of words beginWord -> s1 -> s2 -> … -> sk such that:
Every adjacent pair of words differs by a single letter.Every si for 1 <= i <= k is in wordList. Note that beginWord does not need to be in wordList.sk == endWordGiven two words, beginWord and endWord, and a dictionary wordList, return the number of words in the shortest transformation sequence from beginWord to endWord, or 0 if no such sequence exists.Example 1:
Input: beginWord = “hit”, endWord = “cog”, wordList = [“hot”,”dot”,”dog”,”lot”,”log”,”cog”]Output: 5Explanation: One shortest transformation sequence is “hit” -> “hot” -> “dot” -> “dog” -> cog”, which is 5 words long.Example 2:Input: beginWord = “hit”, endWord = “cog”, wordList = [“hot”,”dot”,”dog”,”lot”,”log”]Output: 0Explanation: The endWord “cog” is not in wordList, therefore there is no valid transformation sequence.Intuition
Naive
This smells like a graph problem. We have a starting word, and want to reach an end word by applying a series of transformations to the given start word. In this case, we move from one word to another if they differ by a single letter.
We want to find the minimum distance, so a breadth-first search feels applicable here.
So how about we generate the list of edges for every pair of words, and if they differ by single letter, we know there’s an edge between the two words.
Then, we’ll use a queue, which stores a list of nodes to explore and the current distance. This should be initialized to just hold the start word and distance of 1.
We’ll also use a visited set to make sure we don’t get stuck in a loop or explore the same node more than once.
Here’s the code:
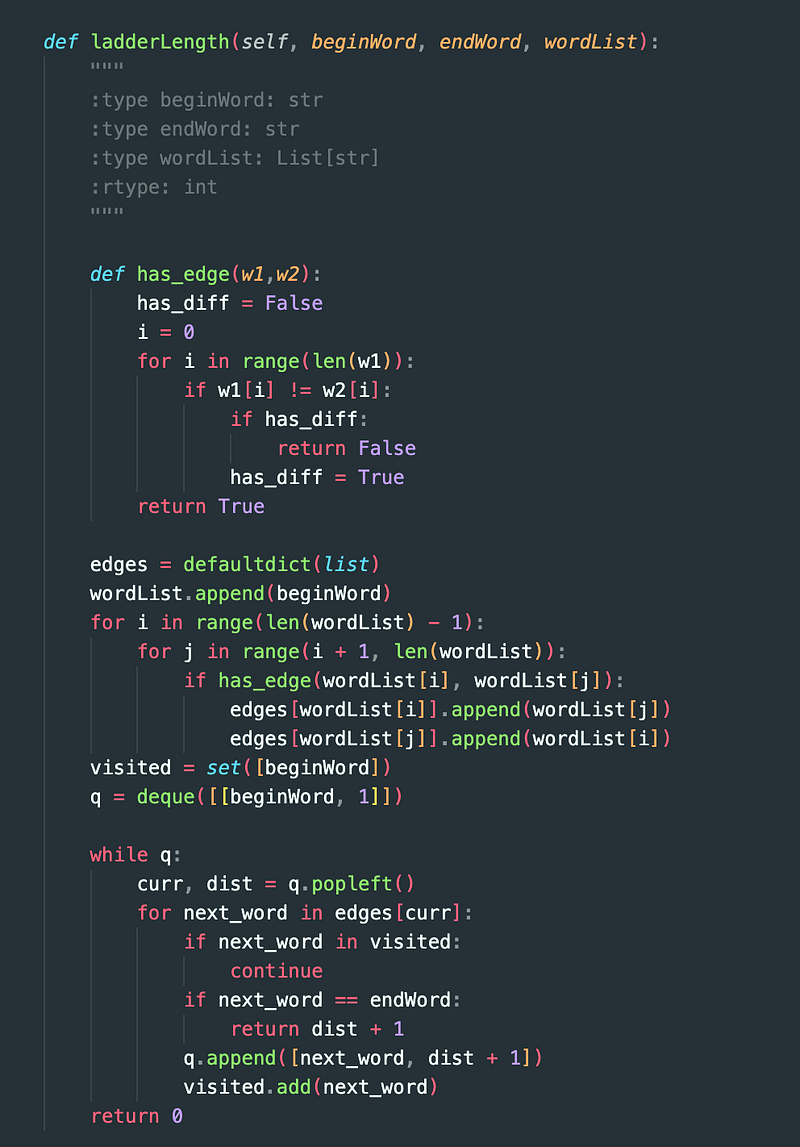
What about the algorithmic complexity? Let’s say:
Length of word = M
Length of word list = N
Then,
Runtime = O(N * N * M)
Space complexity = O(N * N)
Unfortunately, if the length of the word list is large, then this solution is really slow! Let’s think of another approach.
Using Wildcards
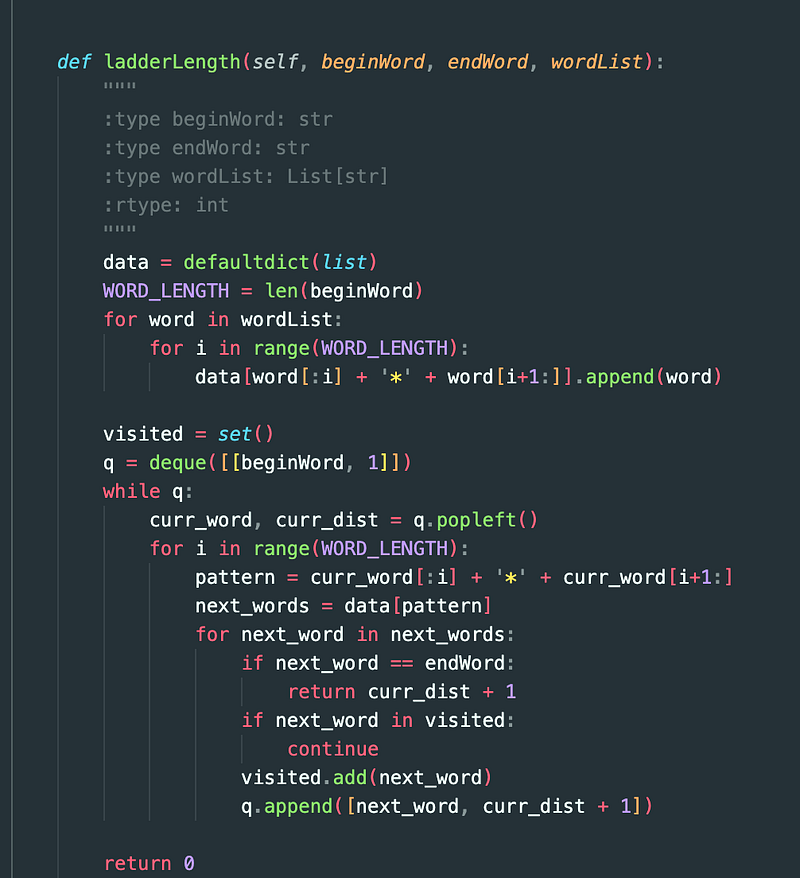
What if instead of trying to generate edges between every pair of words, we created these words with a wildcard in them?
For example, HOT could generate *OT, H*T, and HO*.
And if we treat *OT as a new node, then this would also connect to DOT or LOT.
Here’s the code:
Then,
Runtime: O(N * M * M)
Space complexity: O(N * M)
And we’ve significantly reduced our runtime if the length of the words is much lower than the length of the word list.
Generating the next words on the fly
Instead of doing preprocessing, we could also find the next words to explore on the fly.
At every position of the current word, we insert a new character (there’s only 26 of them)! If that new word is in the word list, then we know there’s a valid edge there. Though, note we should also convert our word list in a set so we can make the membership lookup into O(1) time.
Bi-directional BFS
Another trick we can do is to use a bi-directional BFS. Instead of searching from the start word to the end word, we can search in both directions.
The reason this is faster is because if we assume the branching factor from each word is b, and the distance from the start to end word is d, compare:
Our original BFS: O(b^d)
Bi-directional BFS: O(b^(d/2)) + O(b^(d/2)).
I’ll explain this more in-depth in a separate post, but for now, here’s the code that combines the bi-directional BFS and the “generating words on the fly” optimizations.
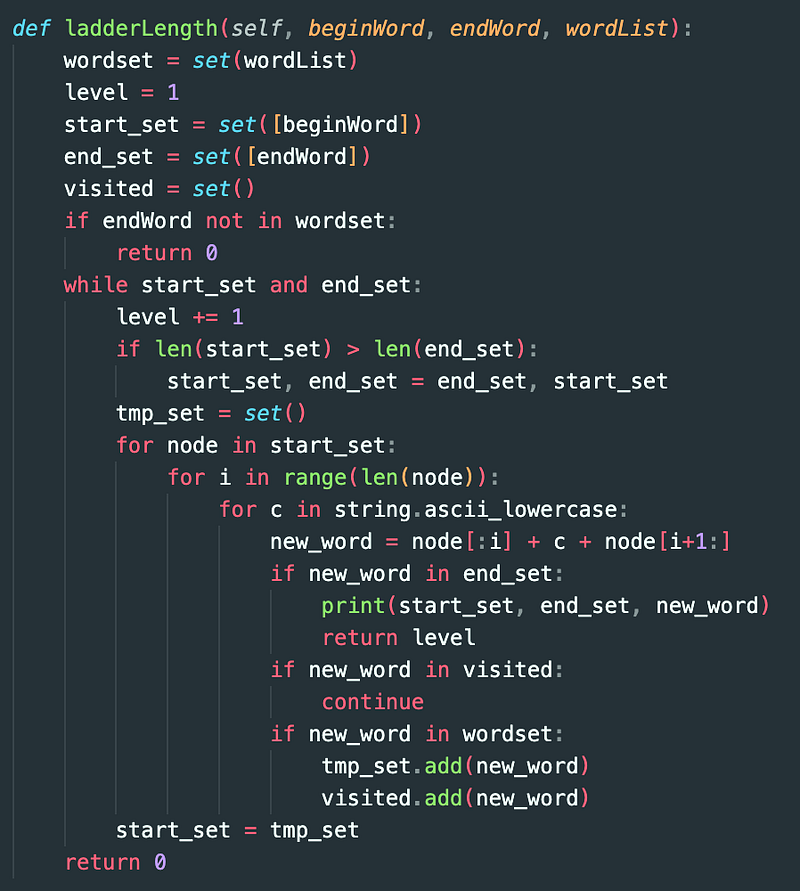
What do you think the runtime and space complexity are for this solution?
For more articles like this, follow me on Medium. Not a member yet? Join the community. Want more software engineering interview guides and coding question tips? Check out all of my writing organized by topic in this article.
If you have any requests for what I should write, please let me know!