
Building a YouTube Recommender with LLM Models
This is my second post on LLM and GenAI application and solution implementation. In the last post I mentioned that I am part of CoE for GenAI and LLM and I ended up building LLM application for my personal slack channel where I automated QnA.
In this blog, I am planning to take a step forward and talk about a different use case that one of my colleague asked for and I ended up working on that for building a video (youtube) recommendation mobile application. Now, I did work on building mobile apps in my previous life, but today my focus is to discuss on the backed, specifically the LLM powered recommendation engine in a chatbot style application. And just to call out, this was a quick POC to prove out the idea, I have not “productionized this” yet.
The Problem Statement
The requirements were simple. My colleague follows a series of youtube influencers and spends a lot of time generating content. He connects with his peers and have a network of friends and colleagues who create similar content. Together (my friend, his network of friends, their likes and their favorites) they have 100’s (if not 1000’s) of videos that they continuously like/ share/ comment or create. The intention was to build a mobile app that can be used by any user to ask a question and get a playlist created based on order of similarity of the question.
Converting the ask to a list of requirements, the focus was :
- Use Youtube SDK to connect and collect list of created videos, liked videos, shared videos, favorite videos from a list of 30 people.
- For the collected videos, collect tags, keywords, descriptions etc into a structured set
- For each video use cognitive services to extract text from audio
- For each video get the overall sentiment
- For each video get the top segments and topics
- For each topic extract additional text from wikipedia
The Solution Overview
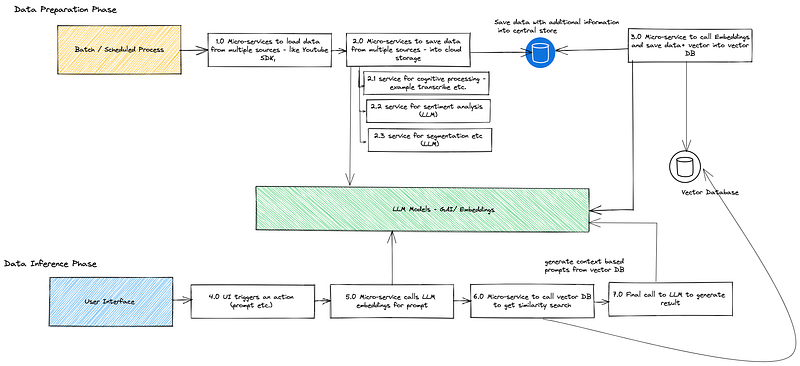
The solution consists of 2 parts. The offline part (data preparation) where the extraction and data preparation happens. This is also the most engineering heavy section.
First, I build dedicated micro-services that can perform a specific action. For example, one of my micro-service was responsible to connect to YouTube and extract a list of videos with their tags, keywords, descriptions etc. The micro-service then wrote the information as individual JSON file to a cloud storage account (as files/ objects).
Next, the second micro-service was triggered from the first (as a chain) where for each of the JSON (which represents a specific YouTube video) I called a cloud based (not LLM) AI cognitive service (using python) to load the YouTube video into memory, extracted audio for the first 5 minutes and then called a audio to text transcription service. This information was then passed to the third micro-service.
The third micro-service then called sentiment analysis on text data, performed segmentation and top 3 topic identification and saved all of that information into the JSON structure (separate location from the source).
Once the final JSON file was created for each of the source video, I used Wiki python SDK to call WIKI on the topics and added more context to the JSON to augment the video description.
Finally, I then called my final micro-service to chunk the description and call embeddings LLM model for each chunk. The whole payload (JSON) along with the chunk vector returned from the LLM was saved into a Vector database for search and query.
When the process ran for all the videos, I ended up having the whole video data for the 1000’s of videos into the vector database. This marked the end of phase 1 (the data preparation part).
The second part consists of building the mobile application (not covered in this blog) to connect to a backend API gateway to ask for video recommendation. This part was the real-time inferencing part. The real-time inferencing part expects a question or request from the mobile application user which is then constructed into a vector question by calling the LLM embeddings model. Next, the vectorized question is used to perform a similarity search on the vector database based on cosine similarity to get a list of top K hits.
The top K hits are then parsed and ranked based on the similarity score and passed back (with link to YouTube) to the mobile application screen.
Conclusion
Although this was a POC to quickly demonstrate and end to end working prototype of a recommendation application but this has a huge similarity to other real-world problems.
Stay tuned for more information on similar use cases.

In Plain English
Thank you for being a part of our community! Before you go:
- Be sure to clap and follow the writer! 👏
- You can find even more content at PlainEnglish.io 🚀
- Sign up for our free weekly newsletter. 🗞️
- Follow us on Twitter(X), LinkedIn, YouTube, and Discord.

