
7 Over Sampling techniques to handle Imbalanced Data
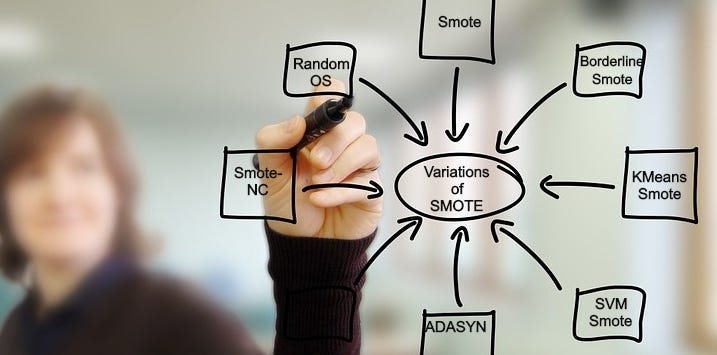
Deep dive analysis of various oversampling techniques
Modeling imbalanced data is the major challenge that we face when we train a model. For dealing with the classification problems the class balance of the target class label plays an important role in modeling. For imbalance class problems i.e presence of minority class in the dataset, the models try to learn only the majority class and result in biased prediction.
Some of the famous examples of imbalanced class problems are:
- Credit Card Fraud Detection
- Disease diagnosis
- Spam detection, and many more
The imbalance of the dataset needs to be handled before training a model. There are various techniques to handle class balance, some of them being Oversampling, Undersampling, or a combination of both. This article will cover a deep dive explanation of 7 techniques of oversampling:
- Random Over Sampling
- Smote
- BorderLine Smote
- KMeans Smote
- SVM Smote
- ADASYN
- Smote-NC
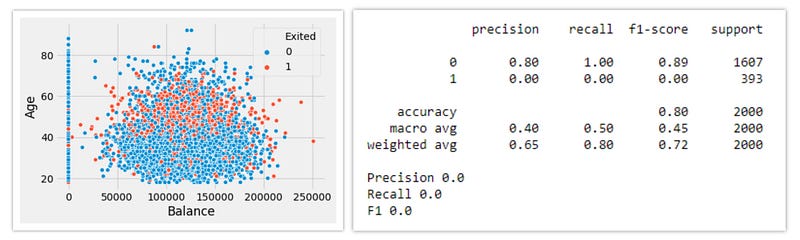
For the evaluation of different oversampling models, we are using the Churn modeling dataset from Kaggle.
Performace of the Logistic Regression model without using any oversampling or undersampling technique.
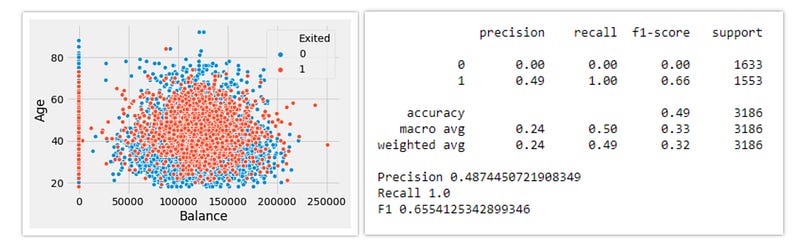
1. Random Over Sampling:
Random oversampling is the simplest oversampling technique to balance the imbalanced nature of the dataset. It balances the data by replicating the minority class samples. This does not cause any loss of information, but the dataset is prone to overfitting as the same information is copied.
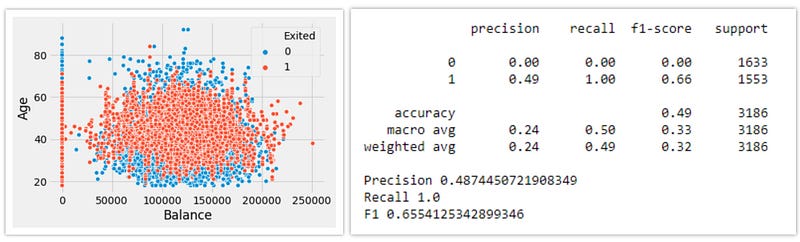
2. SMOTE:
In the case of random oversampling, it was prone to overfitting as the minority class samples are replicated, here SMOTE comes into the picture. SMOTE stands for Synthetic Minority Oversampling Technique. It creates new synthetic samples to balance the dataset.
SMOTE works by utilizing a k-nearest neighbor algorithm to create synthetic data. Steps samples are created using Smote:
- Identify the feature vector and its nearest neighbor
- Compute the distance between the two sample points
- Multiply the distance with a random number between 0 and 1.
- Identify a new point on the line segment at the computed distance.
- Repeat the process for identified feature vectors.
3. Borderline Smote:
Due to the presence of some minority points or outliers within the region of majority class points, bridges of minority class points are created. This is a problem in the case of Smote and is solved using Borderline Smote.
In the Borderline Smote technique, only the minority examples near the borderline are over-sampled. It classifier the minority class points into noise points, border points. Noise points are minority class points that have most of the points as majority points in its neighbor, and border points have both majority and minority class points in its neighbor. Borderline Smote algorithm tries to create synthetic points using only these border points and ignore the noise points.
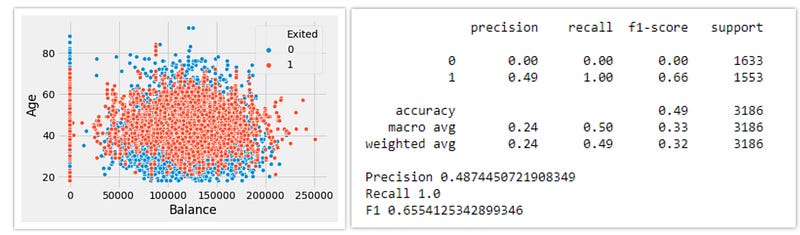
4. KMeans Smote:
K-Means SMOTE is an oversampling method for class-imbalanced data. It aids classification by generating minority class samples in safe and crucial areas of the input space. The method avoids the generation of noise and effectively overcomes imbalances between and within classes.
K-Means SMOTE works in five steps:
- Cluster the entire data using the k-means clustering algorithm.
- Select clusters that have a high number of minority class samples
- Assign more synthetic samples to clusters where minority class samples are sparsely distributed.
Here each filtered cluster is oversampled using SMOTE.
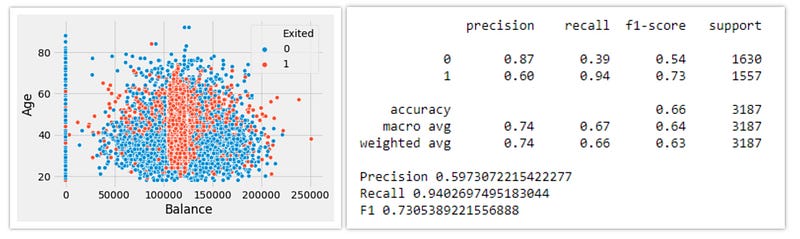
5. SVM Smote:
Another variation of Borderline-SMOTE is Borderline-SMOTE SVM, or we could just call it SVM-SMOTE. This technique incorporates the SVM algorithm to identify the misclassification points.
In the SVM-SMOTE, the borderline area is approximated by the support vectors after training SVMs classifier on the original training set. Synthetic data is then randomly created along the lines joining each minority class support vector with a number of its nearest neighbors.
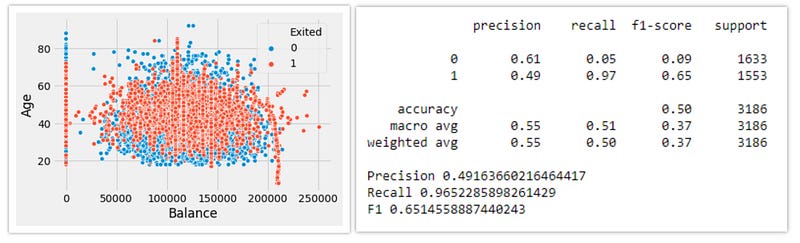
6. Adaptive Synthetic Sampling — ADASYN:
Borderline Smote gives more importance or creates synthetic points using only the extreme observations that are the border points and ignores the rest of minority class points. This problem is solved by the ADASYN algorithm, as it creates synthetic data according to the data density.
The synthetic data generation is inversely proportional to the density of the minority class. A comparatively larger number of synthetic data is created in regions of a low density of minority class than higher density regions.
In other terms, in the less dense area of the minority class, the synthetic data are created more.
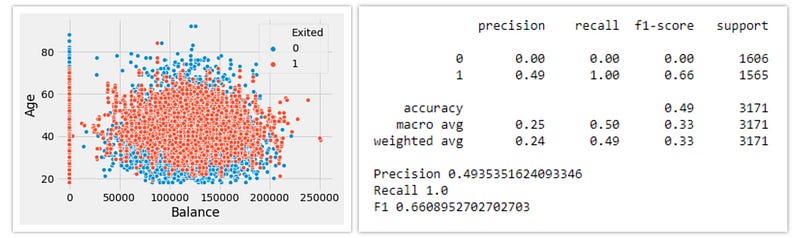
7. Smote-NC:
Smote oversampling technique only works for the dataset with all continuous features. For a dataset with categorical features, we have a variation of Smote, which is Smote-NC (Nominal and Continuous).
Smote can also be used for data with categorical features, by one-hot encoding but it may result in an increase in dimensionality. Label Encoding can also be used to convert categorical to numerical, but after smote it may result in unnecessary information. This is why we need to use SMOTE-NC when we have cases of mixed data. Smote-NC can be used by denoting the features that are categorical, and Smote would resample the categorical data instead of creating synthetic data.
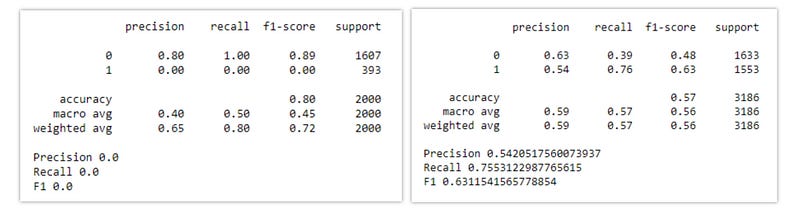
Implementation:
Conclusion:
Modeling an imbalanced dataset is the major challenge that we face while training a model, using various oversampling techniques discussed above the performance of the model can be improved. Also in this article, we have discussed SMOTE-NC, which is a variation of SMOTE, that can handle categorical features.
Model performance of an Imbalanced dataset can also be improved by using various undersampling techniques such as Random Undersampling, TomekLinks, etc, and a combination of oversampling and undersampling techniques such as SMOTEENN, SMOTETomek, etc.
References:
[1] Imblearn documentation: https://imbalanced-learn.readthedocs.io/en/stable/api.html#module-imblearn.over_sampling
[2] https://pypi.org/project/kmeans-smote/
Thank You for Reading




