
7 Famous Approaches to Generate Distributed ID with Comparison Table
Nowadays, many small and large systems require unique global identifiers; it is an essential task in distributed computing with growing internet usage and high dependencies on different applications.
Before jumping directly to Distributed ID Generation approach, Let’s first understand the traditional or current approach or Non-Distributed Approach:
Traditional Approach (Non-Distributed System)
Approach 1: An ID generator uses a shared counter that increases at each call.
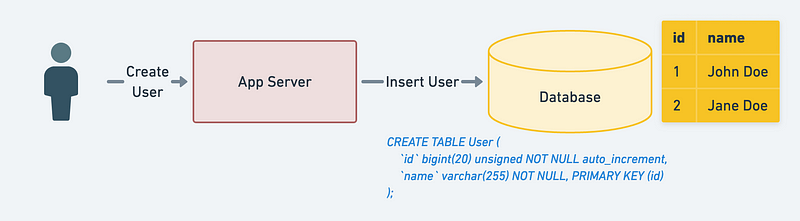
So the above approach works. And even today, Most of the applications are still using this approach.
Approach 2, Another native solution is to generate an ID as a timestamp function. But those are bad solutions because there are the following existing problems.
- Multiple independent servers can generate the same ID.
- The same ID generates for two consecutive requests.
So why do we need a complex system to generate Record / Row ID?
It is often necessary to uniquely identify many data and messages in complex distributed systems. For example, in finance, payment, catering, hotel, cat’s eye film, and other products, the data is growing day by day. After the data gets inserted into databases and tables, a unique ID is required to identify data or messages. At this time, a system that can generate globally unique IDs is vital. Also, the system should handle High Concurrent Requests Per Second (HCRPS) or quickly create identifiers for each new resource.
Applications
Here are a few applications where you need distributed ID generation strategy:
- Stats Collector
- Chat / Messaging
- High Likes / Comments
- Status Update / Tweet
Now, Let’s deep dive into the number of available approaches based on different requirements. A distributed ID generator must meet the following requirements.
Functional Requirements
- They can’t be any length. Let’s assume that is 64 bits of size.
- Sequentially generate unique IDs across the cluster.
- Generates over 10,000 unique IDs per second.
Non-Functional Requirements
- High Performance
- Low Latency including Geo-Latency
- High Availability
- Fault-Tolerant
- Easy to Scale
Approaches:
Here is the overall comparison table between different approaches:

1. UUID / GUID
A GUID is an acronym that stands for Globally Unique Identifier; they refer to as UUIDs or Universally Unique Identifiers. It is a well-known concept used in software for years. UUIDs are 128-bit hexadecimal numbers; the 32 hex characters, plus four dashes, are just a friendlier version for readability and are globally unique. The form is 8–4–4–4–12, with a total of 36 characters. It’s very easy to use
public static void main(String[] args) {
String UUID = UUID.randomUUID().toString().replaceAll("-","");
System.out.println(UUID);
}There are four versions of UUIDs.
- UUID1 uses MAC address and timestamp to generate effective uniqueness.
- UUID3 and UUID 5 uses cryptographic hashing and application-provided text strings to generate UUID. (UUID 3 uses MD5 hashing, and UUID 5 uses SHA-1 hashing).
- UUID4 uses pseudo-random number generators to generate UUID.
2. MySQL: Centralizing Auto-Increments / Famously known as “Flickr’s Ticketing Service” Approach
If we can’t make MySQL auto-increment work across multiple databases, set up a dedicated database with a single table and a single record whose sole purpose is to provide unique and incremental ID. MySQL’s Replace Into Statement can help to achieve this efficiently.
REPLACE works exactly like INSERT, except if an old row in the table has the same value as a new row for a PRIMARY KEY or a UNIQUE index, the old row is deleted before the new one row is inserted.
CREATE TABLE `ID` (
`id` bigint(20) unsigned NOT NULL auto_increment,
`stub` char(1) NOT NULL default '',
PRIMARY KEY (`id`),
UNIQUE KEY `stub` (`stub`)
) ENGINE=MyISAMWhen I need a new globally unique 64-bit ID I issue the following SQL:
REPLACE INTO ID (stub) VALUES ('a');
SELECT LAST_INSERT_ID();3. MySQL: Cluster Mode
As mentioned in the traditional MySQL AUTO_INCREMENT approach, the single-point database mode is not desirable. To improve the above-centralized model, we need to make some changes for high availability, like the master-slave cluster mode should be replaced. If you are afraid that a master node will hang up, you should consider a dual master mode cluster; that is, two MySQL instances can produce self increasing IDs separately. But with different initial values and steps.
Solution: Set the starting value and self increasing step size MySQL_ 1 configuration:
set @@auto_ increment_ Offset = 1; -- starting value
set @@auto_ increment_ Increment = 2; -- step sizeMySQL_ 2 configuration:
set @@auto_ increment_ Offset = 2; -- starting value
set @@auto_ increment_ Increment = 2; -- step sizeThe self incrementing IDs of the two MySQL instances are as follows:

Likewise, you can have as many machines as needed with different step sizes and initial positions of ID. You can even extend this same strategy for Geo Level; each location will have a different starting value and step size.
4. MongoDB
MongoDB uses ObjectIds as the default value of the _id field of each document, which is generated while creating any document. More Detail
ObjectID is a 96-bit number that is composed as follows:
- a 4-byte timestamp value representing the seconds since the Unix epoch (which will not run out of seconds until the year 2106)
- a 5-byte random value, and
- a 3-byte incrementing counter, starting with a random value.
For e.g. 507c7f79bcf86cd7994f6c0e has ISO time value of 2012–10–15T21:26:17Z
5. Twitter Snowflake
There’s a famous ID generator called Snowflakes created by Twitter. Twitter snowflake is a dedicated service for generating 64-bit unique identifiers used in distributed computing for objects within Twitter such as Tweets, Direct Messages, Lists, etc. These IDs are unique 64-bit unsigned integers, which are based on time. The full IDs are made up of the following components:
- Epoch timestamp in a millisecond — 41 bits (gives us 69 years for any custom epoch)
- Configured machine/node/shard Id — 10 bits (gives us up to total of 2 i.e 1024 Ids)
- Sequence number — 12 bits (A local counter per machine that sets to zero after every 4096 values)
- In the beginning, the extra one reserved bit is set as 0 to make the overall number positive.

Since these use the timestamp as the first component, therefore, they are time sortable as well. Another benefit is its High Availability. By default, 64-bit unsigned integers (long) will generate an Id whose length is 19, but sometimes it may be too long; our use case needed an Id whose size should not be greater than 10. This design requires a Zookeeper to keep mapping Nodes and Machine Ids. Also, it requires several Snowflake servers and introduces additional complexity and more’ moving parts’.
💡 Clock synchronization There’s a hidden assumption that all ID generation servers have the same clock to generate the timestamp, which might not be accurate in distributed systems. In reality, system clocks can drastically skew in distributed systems
6. Baidu UID generator
UID generator is developed by the Baidu technology department and implemented based on the snowflake algorithm. Unlike the original snowflake algorithm, It works as a component and allows users to override workID bits and initialization strategy. As a result, it is much more suitable for virtualization environments, such as docker. Besides these, it overcomes concurrency limitation of Snowflake algorithm by consuming future time; parallels UID produce and consume by caching UID with RingBuffer; eliminates CacheLine pseudo sharing, which comes from RingBuffer, via padding. And finally, it can offer over 6 million QPS per single instance.
You need to add a worker Node table. A record will be inserted into the database table when the application starts. The self incrementing ID returned after successful insertion is workID.

As can be seen from the above figure, the time part of the UID generator is only 28 bits, which means that by default, the UID generator can only endure 8.5 years (2 ^ 28–1 / 86400 / 365). Of course, according to the needs of your business, the UID generator can adjust the number of delta seconds, worker node ID, and sequence occupancy appropriately. Here is the Github Code with more detail if you are interested to see how it is implemented.
7. Sony
Sonyflake is a distributed unique ID generator inspired by Twitter’s Snowflake. Sonyflake focuses on lifetime and performance in many host/core environments. So it has a different bit assignment from Snowflake. A Sonyflake ID is composed of
- 39 bits for a time in units of 10 msec
- 8 bits for a sequence number
- 16 bits for a machine id
As a result, Sonyflake has the following advantages and disadvantages:
- The lifetime (174 years) is longer than that of Snowflake (69 years)
- It can work in more distributed machines (²¹⁶) than Snowflake (²¹⁰)
- It can generate ²⁸ IDs per 10 msec at most in a single machine/thread (slower than Snowflake)
However, if you want more generation rates in a single host, you can quickly run multiple Sonyflake ID generators concurrently using goroutines. Since tech giants have some disadvantages of those above implementations, you can write a custom ID to meet your specific requirements.
Conclusion
These seven approaches are very famous, and with a bit of adjustment to your business need, you can adopt any one of them. There is nothing wrong with continuing with your traditional approach because it works perfectly.
With that, I conclude this learning; I hope you have learned something new today. Please do share with more colleagues or friends. Finally, Consider becoming a Medium member. Thank you!



