
6 Practical Approaches to Tackle API Duplicate Requests
The basic and essential technique for REST API development

The issue of online web form double submission has long been a headache of web application developers. Having duplicate requests without proper handling could be devastating such as financial loss due to double payment charges.
Although the issue is mostly prevented by disabling the submission button and using debounce on UI, it solely relies on handling on the client side and the loophole still exists without having defensive logic on the backend side.
Let’s look at a simplified version of an online shopping cart checkout process below. Supposing that customer has done the payment, the following steps process the submitted online shopping cart:
- Create delivery record
- Send customer notification
- Update cart status to submitted
Shopping cart checkout could be far more complicated in the real world, this is a simplified version for demonstration purposes.

Given payment has been done, what happens if more than one checkout request is submitted for the same online shopping cart? According to the checkout flow above, the double submission could result in creation of duplicated delivery records and customer notification.
In this article, I will walk you through each approach one by one in order to build a solution to detect and return 409 Conflict in case of duplicate requests.
Option #1 — Check record existence prior to insertion
Checking if a record is already in the database before inserting one is reasonable, however, it makes sense only in a single threaded environment.
Modern computation processes multiple requests at the same time. The same machine could run multiple threads that handle a number of incoming requests concurrently. The example below demonstrates that duplicate records will still be created in a multi-threaded environment even though record existence is checked before the insertion.
Therefore, this approach is not good enough.

Option #2 — Enforce single thread processing
As the issue is due to the handling of multi-thread, can the enforcement of single thread processing avoid insertion of duplicate requests?
For example, the use of keyword synchronized in Java language makes sure only one thread executes the system logic at a time. Other threads which attempt to execute the same system logic are put on hold until the current thread has completed the execution.
public synchronized void insertDeliveryRecord() {
// … check record existence
// … execute SQL for record insertion …
}This approach looks promising but it is still not sufficient to cater for services which run on more than one instance. Keyword synchronized is only effective for threads within the same JVM.
Unless your system runs only on a single instance, services are normally scaled horizontally with multiple instances for achieving high performance and reliability. Multiple service instances have their own JVMs which are independent of each other. It means that duplicate records could still be created if different service instances handle ecommerce checkout requests around the same time.
Option #3 — Impose constraint on database
Blocking duplicate records on the database is an effective and simple approach.
The sample table definition below defines a composite key which imposes a unique record key constraint to the delivery table. SQL operation to insert record with the same key will be rejected. In Java, SQLIntegrityConstraintViolationException is thrown and so the system logic will quit and the rest operations will be skipped due to the runtime exception.
CREATE TABLE ORDER_DELIVERY (
order_id VARCHAR(50),
delivery_date DATE,
address VARCHAR(70),
priority INT,
PRIMARY KEY (order_id, delivery_date)
)This solution is awesome as it overcomes the shortcomings of option 1 and 2, it is able to detect duplicate records in multi-threaded environment and multiple instances.
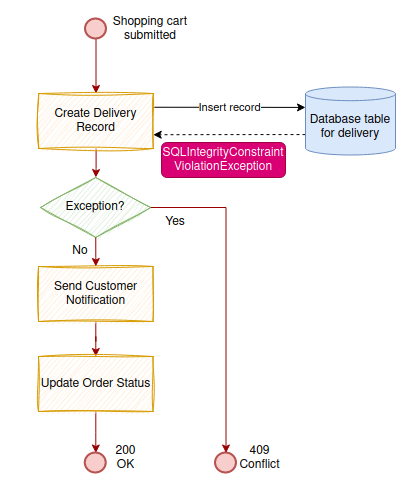
Unfortunately, it is not a perfect solution.
SQLIntegrityConstraintViolationException is not only triggered by violation of unique key but also violation of any other constraints such as invalid foreign key. So, system logic may mistakenly treat invalid foreign key error as the error of duplicate record. If the shopping cart checkout endpoint returns http response 409 Conflict for duplicate record, then the same error code will be returned for other database integrity errors instead a proper return code such as 500 server internal error.
Option #4 — SQLIntegrityConstraintViolationException with hardcoded error message handling
While SQLIntegrityConstraintViolationException does not provide other fields that accurately distinguish between the duplicate record key error and other integrity errors, the only way is to look for the keyword “Duplicate Entry” in the error message like this:
try {
orderDeliveryRepo.insert(deliveryRecord);
} catch (SQLIntegrityConstraintViolationException e) {
If (nonNull(e.getMessage()) && e.getMessage().upperCase().contains(“DUPLICATE ENTRY”)) {
// Duplicate record detected, return 409 Conflict
} else {
// Something went wrong, return 500 Internal Server Error
}
}
Although this approach has the job done, system logic based on specific keywords in error message is not easily maintainable and it could fail in case of any change on the error message due to database version upgrade or change of database (e.g. migrate from MySQL to Postgres).
Option #5 — Update record on duplicate key
Apart from returning an error to clients, the alternative is to accept duplicate requests and update the existing record in the database.
Most relational databases support an operation called upsert which is to update the existing record if a record with the same key already exists, otherwise, insert a new record.
The SQL syntax of MySQL for upsert is to have ON DUPLICATE KEY UPDATE at the end of the insert statement:
INSERT INTO <table name> (<column 1>, <column 2>, …)
VALUES (<column 1 value>, <column 2 value>, …)
ON DUPLICATE KEY UPDATE
<column 1> = <column value>,
<column 2> = <column value>The sample insert statement below updates address and priority if record with the same keys already exist:
INSERT INTO ORDER_DELIVERY (address, priority)
VALUES (‘7400 CLEON AVE SUN VALLEY CA 91352-4811 USA’, 1)
WHERE ORDER_ID = 'XHX8PBX79Z’ AND DELIVERY_DATE = ‘2023-02-16’
ON DUPLICATE KEY UPDATE
address = VALUES(address),
priority = VALUES(priority)This approach is perfectly fine if subsequent operations can be executed more than once. According to the checkout process flow, multiple customer notifications could be sent for duplicate requests because the upsert operation is successfully done without any error even if the same record already exists.
Database does not tell whether the SQL statement is actually a new record insertion or data update. So, the program flow will just run the next step to send customer notification. Before going for this approach, extra work is required in order to make sure a proper handling is in place such as the logic to ensure customer notification is sent once.

Option #6 — Use of database transaction
Database transaction guarantees atomicity that multiple SQL statements to be executed with data consistency and avoid any partial updates.
SQL SELECT statement allows us lock a specific record with “FOR UPDATE” at the end:
SELECT …. FROM <table name> FOR UPDATEApplying database transaction, we will be able to run the following operations in sequence:
- Select and lock order record
- Check if delivery record already exists
- If no, insert delivery record and proceed the rest operations
- Otherwise, return 409 error

While the checkout process for a particular order record is being executed, all other requests for the same order record will be put on hold until the existing database transaction is committed.
This approach is cleaner and easier to be maintained as it does not rely on a specific exception error and hard coded error message. As lock is applied on record level, checkout requests of other order records can be run in parallel without blocking.
The challenge of this approach is to establish database transactions. It would be more complicated if the checkout process involves multiple steps such as external API consumption.
If your system is built using Java Spring framework, good news is that you can simply apply annotation @Transactional to the checkout method and the framework will automatically create a database transaction for you without hassle.
@Transactional
public void doOrderCheckout() {
// select order record for update
// check if delivery record already exists
// insert delivery record
// send customer notification
// update orders status
}Final Thoughts
Handling of duplicate requests is the essential technique of REST API development. API should guard and protect backend resources. we cannot simply assume that clients or front-end have the proper logic to prevent duplicate requests.
This article focuses on the backend process with record insertion. By taking consideration of multiple threaded environments and the provision of multiple service instances, having a database to check for duplicate records is the practical approach. The quick solution is to apply a unique key constraint and detect duplicate entry errors. Fine tuning in the exception error handling is required in order to identify the exact duplicate entry error.
Applying database transactions is the best approach. Having all operations within a single database transaction not only guarantees atomicity but also a more flexible solution instead of hardcoding the error message.





