
6 Optimization algorithms in Machine Learning every Data Scientist should know
Finding the best parameters for your ML models is essential to achieve the desired performance and fit to the data. Here are 5 techniques that you should not neglect for your next ML project.

Introduction
To recall, machine learning optimization refers to the process of finding the best set of parameters and configuration for machine learning models to achieve the desired performance. This is important to minimize misclassification errors, maximize model accuracy, or optimize other performance metrics.
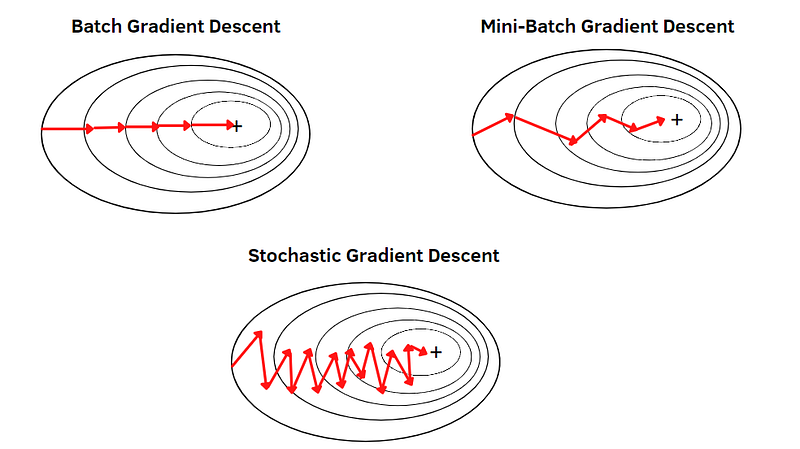
1. Batch Gradient Descent
The algorithm begins with an initial set of parameters and calculates the gradient of the cost function with respect to those parameters. Then, the parameters are updated by taking steps proportional to the negative gradient, iteratively moving towards the minimum.
This method is valid if and only if the cost function is differentiable and continuous everywhere. It is used in most machine model including regression, classification, and neural networks.
A drawback of the gradient descent is that the learning rate will require a careful selection otherwise the cost function can get localised at the minimum point which can be computationally expensive for high-dimensional data.
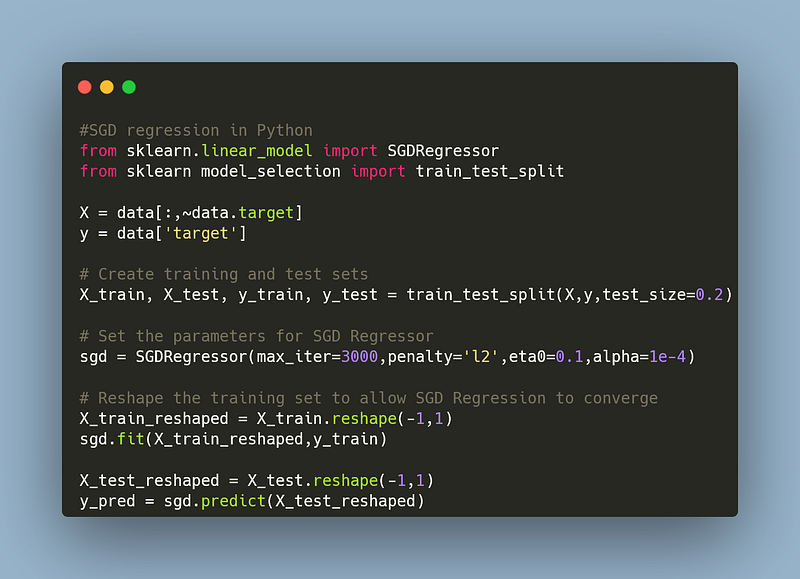
2. Stochastic Gradient Descent
Stochastic gradient descent updates the parameters based on the gradient computed from a single randomly selected training sample or small batch of samples. Similar to the batch gradient descent, the cost function needs to be differentiable and continuous. It is suited for larger datasets and the model’s performance and improvement rate can be view instantaneously after every update.
A limitation for this optimization algorithm is it generates high variance in the parameter updates. This is due to the random sampling which can lead to slower and premature convergence.
3. Mini-batch Gradient Descent
The mini-batch version of the gradient descent updates the parameters based on the gradients computed from a very small batch of training samples. This methods assume that the cost functions can be well estimated by a mini-batch of samples which balances between the stability of the gradient descent and the efficiency of the stochastic gradient descent
It is used for datasets which too large for a stochastic gradient descent but does not fit in memory for the batch gradient descent. However, the optimization method still requires fine-tuning of the learning rate and careful selection of an appropriate mini-batch size.
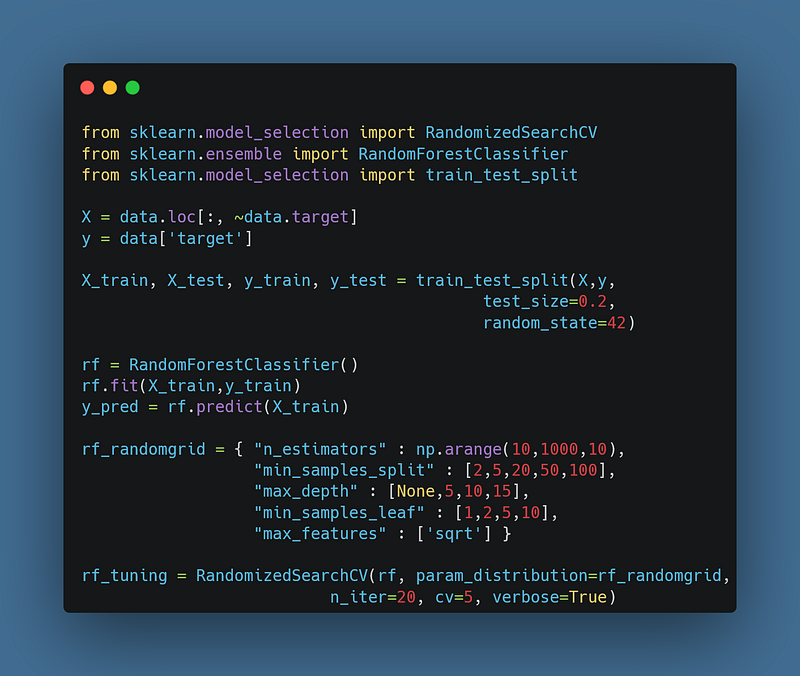
4. Randomized Search
The method randomly selects parameter values within the pre-defined ranges and evaluates the machine learning model’s performance using cross validation or other evaluation methods.
This assumes that the optimal parameters can be found within the defined parameter ranges. This algorithm is useful when the parameter and the performance is complex or non-linear. It is often applied when the parameter space is high-dimensional and exhaustive search is computationally expensive.
A limitation of this algorithm is it may require a large number of iterations to find optimal parameters with no certainty of finding the global optima. The code snippet below shows tuning of hyperparameters for Random Forest Classifier using Randomized Search with cross-validation of 5 folds.
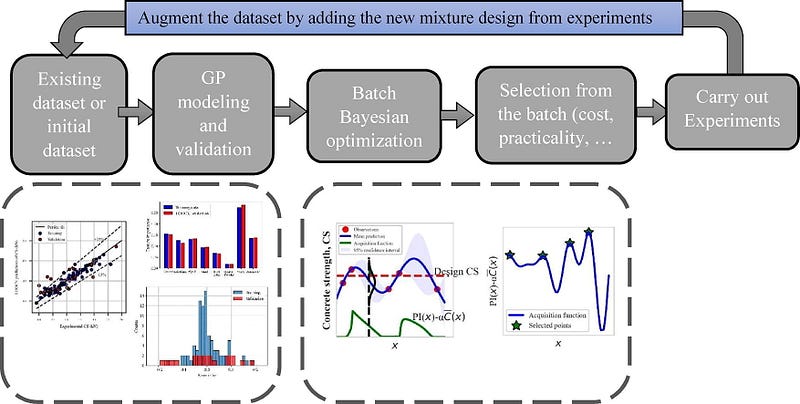
5. Bayesian Optimization
The algorithm works by constructing a probabilistic surrogate model of the objective function and uses it to select the next set of parameters to evaluate. It balances exploration and exploitation to efficiently search the parameter space. This assumes that the objective function is smooth and the surrogate model accurately represents its behavior. The most common method of Bayesian optimization would be Gaussian processes.
Bayesian Optimization is effective when the objective function is expensive to evaluate or when there are constraints on the parameter space.
The main drawback of this algorithm is its sensitivity to the choice of surrogate model and requires careful tuning of hyperparameters. Hence using this algorithm is only appropriate when the vanilla optimization methods cannot be employed on the existing machine learning model.
6. Genetic Algorithms
It starts with a population of candidate solutions represented as chromosomes. It applies selection, crossover, and mutation operations to create a new generation of solutions. Over multiple iterations, the algorithm evolves towards the optimal solution. This method assumes that the optimal solution can be represented as a combination of parameter and that the fitter solutions have a higher change of producing better offspring.
Genetic algorithms are used in feature selection, neural network architecture optimization, and other optimization problems where the solution space is large and complex.
Conclusion
Optimizing your ML models is imperative for accurate statistical conclusions and build better decisions for business growth. However, these methods highly depends on the availability of resources as well as the buy-in from the stakeholders to deploy at an enterprise scale.
If you enjoyed reading my content:
- Give this article a clap 👏 and follow me Aziz Budiman for stories and blogs on all things Data, Artificial Intelligence, and Coding Tips.
- Feedback and comments are welcome as this is a platform where we can learn from one another.
- Show your support and buy me a coffee perhaps? It’s okay if you are unable to do so at this moment.
- Let connect: LinkedIn | GitHub





{kind=link}