
6 Methods To Conduct Linear Regression In Python
Generalized Linear Models (GLM) is the basis of the majority of regression-based models
Linear regression is a statistical method for modeling the relationship between a dependent variable and one or more independent variables. In Python, there are several methods to conduct linear regression. Here are some of the most commonly used methods:
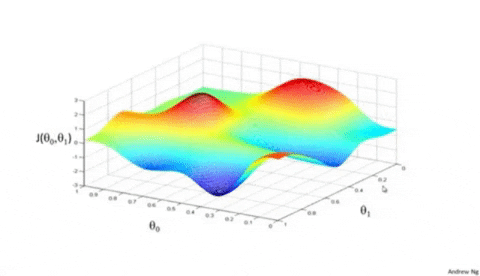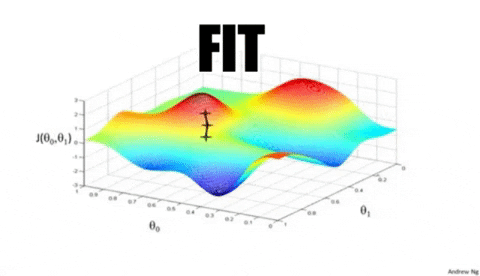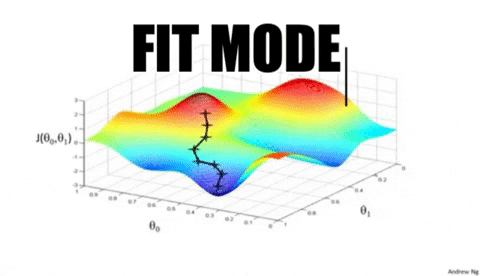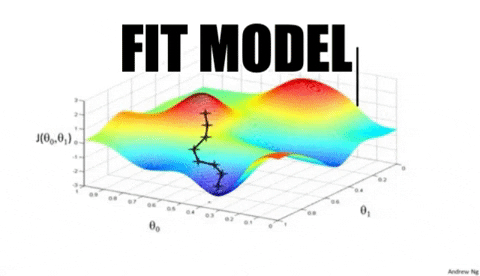
Scikit-learn
Scikit-learn is a popular machine-learning library in Python that provides a simple and efficient way to conduct linear regression. Here’s an example of how to use it:
from sklearn.linear_model import LinearRegression
import numpy as np
# Create some data
X = np.array([[10, 2], [20, 3], [3, 4], [4, 50]])
y = np.array([3, 5, 7, 9])
# Create a linear regression object
model = LinearRegression()
# Fit the model to the data
model.fit(X, y)
# Predict the target variable
y_pred = model.predict(X)Statsmodels
Statsmodels is another popular library in Python for statistical modeling. Here’s an example of how to use it for linear regression:
import statsmodels.api as sm
import numpy as np
# Create some data
X = np.array([[10, 2], [20, 3], [3, 4], [4, 50]])
y = np.array([3, 5, 7, 9])
# Add a constant to the independent variables
X = sm.add_constant(X)
# Create a linear regression object
model = sm.OLS(y, X)
# Fit the model to the data
results = model.fit()
# Predict the target variable
y_pred = results.predict(X)Gradient descent
Gradient descent is an optimization algorithm that can be used to estimate the parameters of a linear regression model. Here’s an example of how to use it:
import numpy as np
# Create some data
X = np.array([[10, 2], [20, 3], [3, 4], [4, 50]])
y = np.array([3, 5, 7, 9])
# Add a constant to the independent variables
X = np.c_[np.ones(X.shape[0]), X]
# Define the learning rate and number of iterations
learning_rate = 0.01
n_iterations = 1000
# Initialize the parameter vector
theta = np.random.randn(X.shape[1])
# Perform gradient descent
for i in range(n_iterations):
y_pred = X.dot(theta)
error = y_pred - y
gradient = X.T.dot(error) / len(X)
theta -= learning_rate * gradient
# Predict the target variable
y_pred = X.dot(theta)Normal equation
The normal equation is a closed-form solution for linear regression that can be used to estimate the parameters of a linear regression model. Here’s an example of how to use it:
import numpy as np
# Create some data
X = np.array([[10, 2], [20, 3], [3, 4], [4, 50]])
y = np.array([3, 5, 7, 9])
# Add a constant to the independent variables
X = np.c_[np.ones(X.shape[0]), X]
# Compute the normal equation
theta = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y)
# Predict the target variable
y_pred = X.dot(theta)Bayesian linear regression
Bayesian linear regression is a probabilistic approach to linear regression that allows for uncertainty in the estimates of the parameters. Here’s an example of how to use it:
Note: Bayesian linear regression using the latest version of pymc3 may cause issues related to intel’s mkl library of conflict with theano. Depending on your system, you might have to troubleshoot that.
import numpy as np
import pymc3 as pm
# Create some data
X = np.array([[10, 2], [20, 3], [3, 4], [4, 50]])
y = np.array([3, 5, 7, 9])
# Define the model
with pm.Model() as model:
# Define the priors
beta = pm.Normal('beta', mu=0, sd=10, shape=X.shape[1])
sigma = pm.HalfNormal('sigma', sd=1)
# Define the likelihood
y_obs = pm.Normal('y_obs', mu=X.dot(beta), sd=sigma, observed=y)
# Fit the model
trace = pm.sample(1000)
# Predict the target variable
y_pred = X.dot(trace['beta'].mean(axis=0))Ridge regression
Ridge regression is a regularized form of linear regression that can be used to prevent overfitting. Here’s an example of how to use it:
from sklearn.linear_model import Ridge
import numpy as np
# Create some data
X = np.array([[10, 2], [20, 3], [3, 4], [4, 50]])
y = np.array([3, 5, 7, 9])
# Create a ridge regression object
model = Ridge(alpha=0.1)
# Fit the model to the data
model.fit(X, y)
# Predict the target variable
y_pred = model.predict(X)Which one should I choose?
Great that there are multiple methods to achieve almost the same result, so which one should we choose and why? It might be helpful to look at the comparison of these methods. I will try to lay out some of the biggest pros and cons of each.
Scikit-learn
Pros:
- Easy to use and implement
- Provides a wide range of linear regression models and options (check out the https://scikit-learn.org/stable/supervised_learning.html list of linear models)
- Provides built-in methods for cross-validation and model selection
Cons:
- Assumes linearity and additivity of the relationship between the dependent and independent variables
- It does not provide a probabilistic interpretation of the model. For all the conventional statistics nerds, this might be a deal breaker. Statsmodels for the rescue
Statsmodels
Pros:
- Provides detailed statistical analysis and diagnostic tools
- Supports a wide range of statistical models, including linear regression with categorical variables
Cons:
- It can be more complex to use and implement than scikit-learn
- It may not scale well to large datasets (all the big data nerds, yes sampling might be your best friend if you insist on using
statmodels)
Gradient descent
Pros:
- Can handle large datasets and high-dimensional feature spaces
- It can be used for online and incremental learning. This is probably the biggest benefit of gradient descent but it comes at a steep cost of computational complexity and in-general slowness)
Cons:
- It may converge slowly or not at all if the learning rate is not set correctly.
- Be careful about choosing the right kernel, gradient step size, and the number of iterations. If you are using the cloud then better to experiment on a smaller set before breaking the bank.
- May converge to a suboptimal solution if the data is not standardized or normalized
Normal equation
Pros:
- Provides a closed-form solution that can be computed quickly
- It does not require tuning of hyperparameters
Cons:
- It can be computationally expensive for large datasets if the matrix is not invertible. Also, think about the memory size that the matrix needs to fit in. Be careful about float conversion. Try to use floatpoint 8 or FP16 operations to save some memory.
- Does not handle collinearity between the independent variables well
Bayesian linear regression
Pros:
- Provides a probabilistic interpretation of the model and estimates the uncertainty in the parameters
- Can handle more complex models with non-linear relationships and interactions between variables
Cons:
- It can be computationally expensive and challenging to implement
- It requires specifying prior distributions for the parameters which many times is challenging to say the least. Consult your subject matter experts to estimate what is a reasonable expectation and built parameters based off that.
Ridge regression
Pros:
- Can prevent overfitting and improve the generalization performance of the model
- Can handle collinearity between the independent variables
Cons:
- Requires tuning of hyperparameters, such as the regularization strength
- It does not provide a probabilistic interpretation of the model
Okay, so that's a wrap.
Don’t forget to follow, like, and share the article. Thank you!
🔔 clap | follow | Subscribe 🔔
Become a member using my link: https://ithinkbot.com/membership






