
Design Google search -part1 (HLD)
Design search typeahead like Google.
Functional requirement.
- Support only prefix-based searching.
- Ensure case-insensitive search capability.
- Enable searches up to 50 characters in length, including spaces.
- Display the most popular search strings first.
- Whenever a user selects a string from the search results or presses enter on a string, increase the popularity or search count of that string.
- Display only the top 10 most popular searches based on search frequency and trending queries.
- When user selects a auto suggest result or hit enter. If the search string is associated with links then those links should be shown.
Other requirements not considered in this design
- Account for spelling mistakes.
- Personalize search results.
- wildcard based search.
- block certain type of queries.
Non functional requirements.
- High availability (Google search is a highly available service)
- Low latency (We need to start showing suggest as fast as possible)
- Eventual consistency on most popular results.
Before you read further checkout this amazing system design courses from design guru.
Continue Reading….
Estimate on Scale
A quick google search
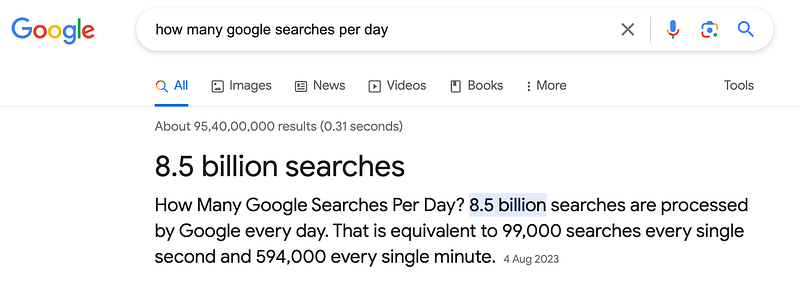

Storage requirement for all the search queries.
Around 9 billion search every day
15% of 9 billion is around 1.5 billion new query every day.
Estimating Storage Requirements for Search Strings
When designing a system to store and lookup search strings, a key engineering consideration is how much storage space will be required. Here we provide some back-of-the-envelope calculations to estimate the storage needs for 1.5 billion 20-character search strings per day over a year, using both individual string storage and a trie data structure.
Individual String Storage For individual storage, each search string is stored separately as a contiguous sequence of characters. With 1.5 billion 20-char strings per day, that’s: - 1.5 billion strings per day - 20 characters per string - So 30 billion total characters per day - Each character is 1 byte - Therefore, 30 billion bytes = 30 GB of storage needed per day - Over 365 days, that’s 30GB * 365 = ~11 TB per year
Trie Storage A trie (prefix tree) can encode common prefixes between strings just once, potentially reducing redundancy. However, in the worst case of random strings, a trie can take more space than individual storage. Each trie node contains: - Child pointers (e.g. 27 for English alphabet and space)
Assumption for trie storage - 5 bytes per trie node (4 byte pointer, 1 byte character) - 3/4 string overlap - 1.5 billion 20-char strings per day
Then each day needs: - Only 1/4 of characters are unique = 7.5 billion - 7.5 billion nodes per day at 5 bytes each = 37.5 GB per day - Over 1 year = 37.5 GB * 365 = ~13.7 TB
So with significant overlap, the trie requires about 13.7 TB for 1 year of search data. This is slightly larger than the 11 TB for individual storage, but the trie enables faster searching, so the space tradeoff may be worth it.
QPS calculations.
- Write QPS: — 9 Billion writes per day — 9 * 10⁹ / 86400 ≈ 100k write QPS
- Read QPS: — In worst case we can send a search query on every character that user type — 9Billion * 20 (average no of characters) reads per day — 18*10¹⁰ req / day — 18*10⁵ req / sec ≈ 2 million read QPS
High level design and deep dive
For prefix based search Trie is a good choice. But for this kind of large scale system we will not be able to fit trie in one machine. We will discuss about the strategy to distribute trie later.
For now Let’s assume we can fit Trie in one machine.
How a prefix search query will get executed.
Approach 1: Basic Trie Search and Sorting
We find all the search strings that match the prefix along with their search count. Then we sort the result by search count in descending order and return the top 10 results. However, this approach may be slow, especially when there are millions of strings with a prefix match.
Approach 2: Optimized Trie with Top 10 Results Stored
To address the slowness of the previous approach, we consider storing the top 10 prefix match search strings on each node of the trie. This optimization significantly improves response times, as it eliminates the need to search and sort through a large number of strings for each query.
Updating Frequencies and Results
Every time a query is entered or selected by the user, its frequency or search count needs to be increased. Subsequently, the top 10 results on each of the prefix nodes require updating. While this approach results in faster reads, it presents challenges with slower writes. Increasing frequency leads to the update of multiple prefix nodes, impacting write performance. Moreover, since both reads and writes occur on the same trie, frequent write operations can decrease overall read performance, as each read operation is dependent on the completion of a write.
Resolutions to Write Performance Issues
To mitigate the issues with slow writes, an alternative resolution involves accumulating all frequency increase events in a map of string to its count. Instead of updating the trie immediately, these events are batched and the trie is updated at regular intervals like every 1 day. This strategy reduces the number of writes significantly, improving overall system performance.
Problems with the Previous Approach
The aforementioned approach introduces a significant drawback: the potential for missing breaking news or trending topics. For instance, in the event of a major occurrence prompting a sudden surge in searches, updating the trie after a fixed time interval, such as 1 day, results in a delayed representation of the latest search trends. This delay adversely impacts customer experience, as users are unable to access the most relevant and recent information promptly.
Addressing the Recency Issue
To mitigate the recency concern, an alternative strategy can be employed. Instead of adhering to a fixed update interval, we can implement a dynamic approach in our frequency map. Specifically, when the frequency of a particular search string surpasses a predefined threshold, we can opt to update the search count for that string in our trie immediately. This adaptive mechanism ensures that trending search queries are promptly reflected in the results, alleviating the issue of missing out on breaking news and enhancing the overall user experience.
Further optimization through random sampling.
At Google’s scale, searches occur at an extremely high rate. Instead of maintaining a strict search count, even a random sample of search counts could mimic the actual data. We are only interested in the popularity of the search query, not the exact count. What if, out of all the search queries we receive, we only increase the count in our hashMap for just 5% of the traffic? This could reduce the write load by 95%, and we would still have almost the same results.
What if a particular search query is so popular today that it’s frequency count becomes in billions. Even after few month when this search string is not popular we might still be showing it on top and this is bad customer experience.
How to fix this?
Using Time decay. We can choose a decay factor for example it could be 1.2 and every day frequency gets divided by their decay factor. Let’s understand this with an example.
on 1st Jan 2022 {query: "corono virus": searchCount: 10000}
on 2nd Jan 2022 we got another 1000 search for query "corono virus"
on 2nd Jan 2022 new searchCount will be 1000 + 10000/1.2 => 9333
on 3rd only 100 people search for query "corono virus"
on 3rd Jan 2022 new searchCount will be 100 + 9333/1.2 => 7877
on 4th Jan only 10 people searched
on 4th Jan 2022 new searchCount will be 10 + 7877/1.2 => 6574
We can see that how the searchCount is decreases as popularity of search term
"corono virus" is decreasing.Let’s make our Trie distributed. To understand follow the conversation below.
Okay, so how do we spread out a Trie?
Here’s an idea: let’s shard our trie based on the first character of each string. So, all the strings starting with ‘a’ go to machine 1, those starting with ‘b’ go to machine 2, and so on. We’d end up with 26 shards, each one handling a different starting letter.
But hold on, we hit a snag: only 26 shards. That’s not great.
So, how about this? We can expand the idea to a prefix of size 3. ‘aaa’ goes to one shard, ‘aab’ to another, and ‘zzz’ to yet another. This way, we could have 26³ shards. Fancy, right?
But wait, there’s a problem. Shards with prefixes like ‘zzz’ and ‘yyz’ hardly get any action, making them “cold shards.” On the flip side, the shard for the prefix “how” becomes super popular because lots of Google queries start with “how.” That’s a bit of an issue.
But hey, we’ve got solutions! What if we group multiple cold shards together into one? We can get creative, like giving high-powered machines to the popular “hot shards” and saving smaller ones for the quiet “cold shards.” Plus, we can keep track of which prefix goes to which shard using a reliable service like Zookeeper. Cool, right?
And guess what? We can make things even cooler! We can use something called consistent hashing. Here’s the scoop: we take a prefix of size 2, 3, or 4 from the string, pass it into a hash function, and voila! We get the spot where that particular shard should be. It’s like giving each piece of the trie its own unique home with just a little piece of the string. How nifty is that?
Now that we’ve distributed our Trie, are we going to keep the full Trie on a machine in memory or on a hard disk?
RAM is expensive but fast, while a hard disk is cheap but slow.
We can use a hybrid strategy; we keep x levels of our Trie in memory or inside RAM, and the remaining levels can be stored on a hard disk. This way, we’ll be able to answer short queries much faster. In Google search, most of the queries (around 80–90%) are small queries.
Alternative solution to implement search typeahead without Trie
The issue with the solution using Trie to find popular search terms by prefix is that we have to handle sharding ourselves. This is a tricky problem to solve and this will create a lot of engineering overhead for the team.
Is there any alternative?
Let’s explore.
Usually, in big distributed systems, if we can organize our data as (key, value) pairs, it’s easy to expand our database using key-value store databases that are already great at scaling and have built-in horizontal scaling abilities. This way, we can keep the extra work needed for scaling to a minimum.
What if we consider each prefix as a key, and the value will be a list of the popular top 10 results with a prefix match? This way, our reads will be much faster to find the top 10 popular search queries with a prefix match. However, our frequency/searchCount updates will be slower, and we might need to update multiple prefixes that could be located in different nodes. For example
for search string "system design"
We need to store all of its prefixes of size >= 3 in a key value store
"sys" => List[{query: "system design", searchCount: 1000},{query: "system design cource", searchCount: 800}]
"syst" => List[...]
"syste" => List[...]
"system" => List[...]
"system " => List[...]
"system d" => List[...]
"system de" => List[...]
Read will be an O(1) operation
Write will be an O(N) operation as a string will have N prefixes (N is size of string)In this approach memory requirement will be much higher compared to trie. We are not only strings but all of its prefixes as well along with top 10 popular results.
We can apply all the optimizations we applied in Trie to improve write performance using buffered hashMap to keep counts and update counts only after it reaches certain threshold and Use sampling to reduce write load.
With key => value store we can apply another optimization.
If we can create a hash function that gives us a unique number for a given prefix, we can set up a mapping where an Integer corresponds to a string. We store this mapping in a different database. The key in this database will be an Integer, and the value will be a list of Integers, each representing a unique search string. Looking up Integers is faster than looking up strings, and it can also lighten the memory load on our main database since we don’t have to store the entire string there. The mapping of Integer to string can be stored in a separate database. There are many flows with this approach as well when we have a scale like Google. No of search string might not fit in Integer after a point. Difficult to create a hash function which generate unique no without any collision.
Conclusion:
Despite our initial goal of creating a straightforward auto-suggest feature based on strict prefixes, the task became quite intricate for a large-scale system. We imposed limitations, such as restricting the search string size to 50 characters and allowing only lowercase English alphabets.
Consider the complexity of Google search, which offers localization, personalization, wildcard matching, the flexibility to handle any search string size, keyword blocking, very low latency, and such high availability that people commonly use google.com to check their internet connection. Google has become synonymous with the internet itself.
Thank you for taking the time to read. Feel free to connect with me on LinkedIn if you require any assistance! I’m more than happy to help with your interview preparation or provide guidance for your career.
Follow me on LinkedIn and Medium for more tech content and insights.
Similar interesting read Pastebin System design Instagram System design
My interview Experience Google interview experience Read about my interview experience at Facebook Read about my interview experience at Amazon
Checkout Design Guru Courses on DSA and System design
Thankyou so much for reading!!!




