
Common Amazon and Facebook Interview Question: Word Break
This is a frequently asked question at Amazon and Facebook in the last six months.
Question
Given a string s and a dictionary of strings wordDict, return true if s can be segmented into a space-separated sequence of one or more dictionary words.Note that the same word in the dictionary may be reused multiple times in the segmentation.So as an example, if I had:
s = 'mediumrocks'
wordDict = ['medium', 'rocks']Then the output would be True.
Here’s another example:
Input: s = "catsandog", wordDict = ["cats","dog","sand","and","cat"]
Output: falseThe output isFalse because there isn’t a way to actually compose the given string with the words in the list.
See below for the solution!

Intuition
We can model this as a graph problem (“we have a starting position at the beginning of the word — index 0 — and we want to get an end position, which is the index at the end of the word”).
Let’s think about how to map a common graph traversal algorithm, breadth-first search, to this problem.
Our queue will initially hold one value to explore, 0, which represents the start of the word.
We can add another value to the queue when we have a word that essentially acts as an “edge” to our current position. For example, for “mediumrocks”, if we’re exploring index 0, and we have the word “medium” in our word list, we know we can get to index 6, which is where the letter “r” is.
We return True when the next position to evaluate is the length of the given word. If we exit the breadth-first search without returning True then we know we weren’t able to reach the end position successfully, and instead return False .
An important optimization
Similar to many other graph problems, we’ll also want to keep a “visited” set to know which positions we’ve explored before. For this problem, we don’t care about *how* we got to our current position, just whether we’ve explored it before. So, when evaluating whether to add a “next position” into the queue, if we’ve seen it before, we should skip it.
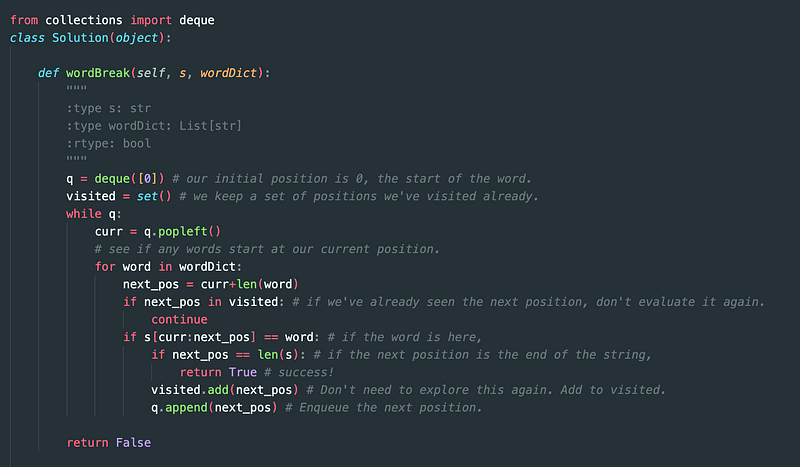
Annotated Code
Algorithmic Complexity
Let’s say M is the length of S and Nis the size of wordDict .
Runtime
Since we will at most explore every position once, that’s a factor of M .
Then, we iterate over each word, so that’s a factor of N .
Note that we also generate the substring each time in if s[curr:next_pos] == word , so that’s another factor of M.
The overall runtime then is O(M²N).
Space Complexity
We are only tracking visited positions and a queue, both of which scale linearly with the size of the given string, S. So the space complexity is O(M) .
Hope this was helpful and let me know if you want me to cover any other problems.
For more articles like this, follow me on Medium. Not a member yet? Join the community. Want more software engineering interview guides and coding question tips? Check out all of my writing organized by topic in this article.
If you have any requests for what I should write, please let me know!