
5 Ways for Deciding Number of Clusters in a Clustering Model
Elbow method, Silhouette score, hierarchical graph, AIC & BIC, and gap statistics

Deciding the optimal number of clusters is a critical step in building an unsupervised clustering model. In this tutorial, we will talk about five ways to decide the number of clusters for a clustering model in Python. You will learn:
- How to use the elbow method on within cluster sum of squares to decide the number of clusters?
- How to use the Silhouette score to decide the number of clusters?
- How to use the hierarchical graph to find the optimal number of clusters visually?
- How to use AIC and BIC for choosing the number of clusters?
- How to use gap statistics to decide the number of clusters?
Resources for this post:
- Video tutorial for this post on YouTube
- Python code is at the end of the post. Click here for the Colab notebook.
- More video tutorials on unsupervised model
- More blog posts on unsupervised model
Let’s get started!
Step 1: Import Libraries
In the first step, we will import the Python libraries.
pandasandnumpyare for data processing.matplotlibandseabornare for visualization.datasetsfrom thesklearnlibrary contains some toy datasets. We will use the iris dataset to illustrate the different ways of deciding the number of clusters.PCAis for dimensionality reduction.KMeans,hierachy, andGaussianMixtureare three widely used clustering models.silhouette_scoreis a metric to evaluate clustering model performance.
# Data processing
import pandas as pd
import numpy as np# Visualization
import matplotlib.pyplot as plt
import seaborn as sns# Dataset
from sklearn import datasets# Dimensionality reduction
from sklearn.decomposition import PCA# Modeling
from sklearn.cluster import KMeans
import scipy.cluster.hierarchy as hier
from sklearn.mixture import GaussianMixture# Number of clusters
from sklearn.metrics import silhouette_scoreStep 2: Read Data
Step 2 reads the data. we first load the data using load_iris(), which is in a Python dictionary format. The keys of the dictionary show that the iris dataset includes the data, target, frame, target names, description of the dataset, feature names, filename, and data module.
# Load data
iris = datasets.load_iris()# Show data information
iris.keys()Output
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])Next, let’s print out the feature_names, target_names, and target. We can see that there are four features, Sepal length, sepal width, petal length, and petal width. The target contains the names of three different flowers, setosa, Versicolor, and virginica, which are encoded into three numbers, 0, 1, and 2.
# Print feature and target information
print('The feature names are:', iris['feature_names'])
print('The target names are:', iris['target_names'])
print('The target values are:', iris['target'])Output
The feature names are: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
The target names are: ['setosa' 'versicolor' 'virginica']
The target values are: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]In order to use the data for the clustering model, we need to convert the data into a dataframe format. Using .info(), we can see that the dataset has 150 records, and there are no missing values.
# Put features data into a dataframe
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)# Add target to the dataframe
df['target'] = iris.target# Data information
df.info()Output
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal length (cm) 150 non-null float64
1 sepal width (cm) 150 non-null float64
2 petal length (cm) 150 non-null float64
3 petal width (cm) 150 non-null float64
4 target 150 non-null int64
dtypes: float64(4), int64(1)
memory usage: 6.0 KBUsing value_counts(), we can see that there are 50 records for each type of flower.
# Check counts of each category
df['target'].value_counts()Output
0 50
1 50
2 50
Name: target, dtype: int64Clustering model is a type of unsupervised model, so we will not use the target information for the model. Only the four features will be utilized in the model and the goal is to group the same type of flowers together, therefore, a new dataframe called X is created, which includes only the four features.
# Remove target for the clustering model
X = df[df.columns.difference(['target'])]Step 3: Dimensionality Reduction and Visualization
In step 3, we will visualize the data to understand the ground truth clusters.
Since there are four features, we need to use a dimensionality reduction technique to convert the features from a 4-dimensional space to a 2-dimensional space for visualization.
Principle Component Analysis (PCA) is applied and the three types of flowers are visualized in the scatter plot. We can see that among the three types of flowers, one type is quite different from the other two flowers, but the other two flowers are quite similar to each other.
# Fit PCA with 2 components
pca = PCA(n_components=2).fit_transform(X)# Add the two components as columns in the dataframe
df['PCA1'] = pca[:, 0]
df['PCA2'] = pca[:, 1]# Visualize the data
sns.set(rc={'figure.figsize':(12,8)})
sns.scatterplot(data=df, x="PCA1", y="PCA2", hue="target")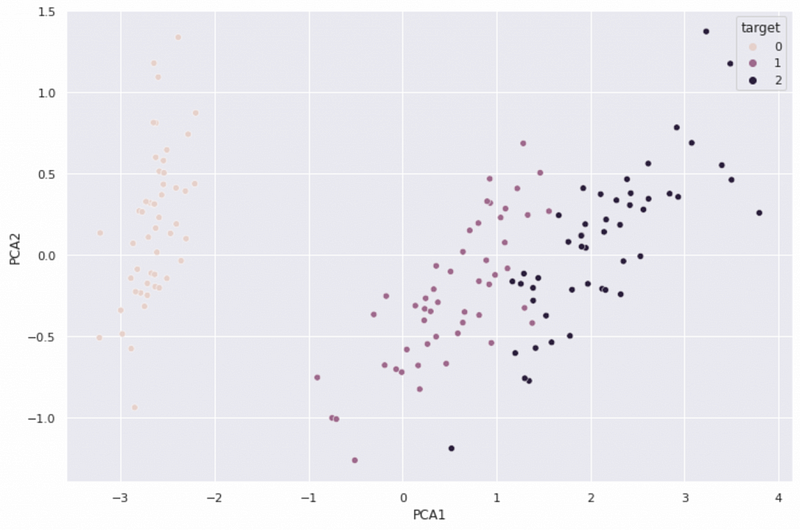
We know the ground truth for the number of clusters is three, but two can be a reasonable number as well because of the similarity of the two types of flowers.
Note that in a real-world project, there is usually no ground truth label available for the clustering model. We pick a dataset with labels for this tutorial mainly to evaluate different ways of deciding the number of clusters.
Step 4: Deciding Number of Clusters Using Elbow Method (Method 1)
In step 4, we will show how to use an elbow method to decide the number of optimal clusters.
The elbow method is the most widely used method for choosing the number of clusters. It runs clustering models for a range of cluster numbers and plots the within cluster sum of squares. The elbow on the plot shows the point where the diminishing returns for additional clusters happen.
# Create an empty dictionary to save the within cluster sum of square values
wcss = {}
# Look through the number of clusters
for i in range(1,11):
# Run kmeans model
kmeans = KMeans(n_clusters=i, random_state=0).fit(X)
#Sum of squared distances of samples to their closest cluster center.
wcss[i] = (kmeans.inertia_)
# Print the within cluster sum of squares for each cluster number
print(f'The within cluster sum of squares for {i} clusters is {wcss[i]:.2f}')Output
The within cluster sum of squares for 1 clusters is 681.37
The within cluster sum of squares for 2 clusters is 152.35
The within cluster sum of squares for 3 clusters is 78.85
The within cluster sum of squares for 4 clusters is 57.23
The within cluster sum of squares for 5 clusters is 46.47
The within cluster sum of squares for 6 clusters is 39.04
The within cluster sum of squares for 7 clusters is 34.30
The within cluster sum of squares for 8 clusters is 30.06
The within cluster sum of squares for 9 clusters is 28.27
The within cluster sum of squares for 10 clusters is 26.09From the visualization, we can see that the biggest decrease in within cluster sum of squares happens at 2 clusters, and there is a relatively large decrease from 2 to 3 clusters. The decreases are small for the models with the number of clusters greater than 3. Therefore, we can conclude that the optimal number of clusters is probably 2 or 3.
# Visualization
plt.figure(figsize=(12,8))
plt.plot(list(wcss.keys()),list(wcss.values()))
plt.title('Elbow Method')
plt.xlabel('Number of Clusters')
plt.ylabel('Within Cluster Sum Of Squares')
plt.show()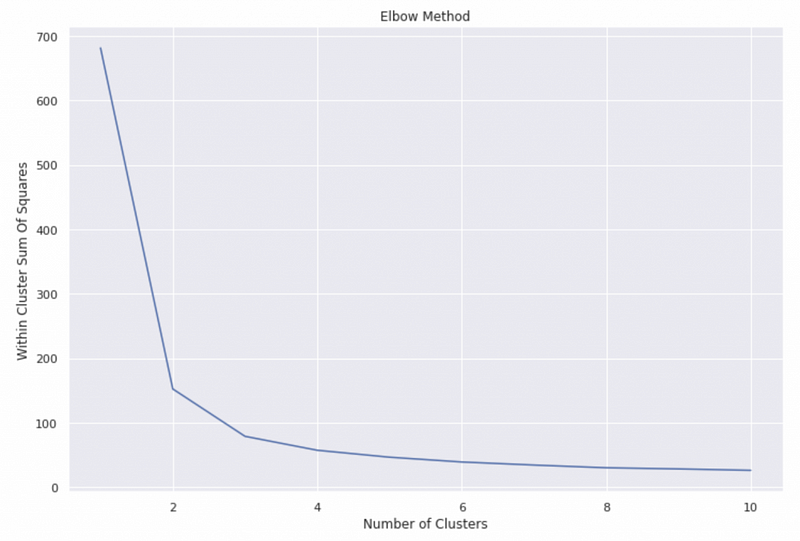
Step 5: Deciding Number of Clusters Using Silhouette Score (Method 2)
In step 5, we will talk about how to use the Silhouette score to decide the number of clusters.
The silhouette score measures how similar a data point is to its own cluster compared to the closest neighbor cluster. The silhouette ranges from −1 to +1.
- The best value is 1, and a value close to 1 means that the sample’s distance to the nearest neighbor cluster is much larger than the intra-cluster distance.
- 0 indicate overlapping clusters[2].
- The worst value is -1, and a value close to -1 means that the sample is assigned to the wrong cluster[2].
Note that Silhouette Coefficient is only defined if the number of clusters is at least 2 and at most the number of samples minus 1.
The Silhouette score of the model is the average Silhouette value of all samples.
# Create an empty dictionary for the Silhouette score
s_score = {}
# Loop through the number of clusters
for i in range(2,11): # Note that the minimum number of clusters is 2
# Fit kmeans clustering model for each cluster number
kmeans = KMeans(n_clusters=i, random_state=0).fit(X)
# Make prediction
classes = kmeans.predict(X)
# Calculate Silhouette score
s_score[i] = (silhouette_score(X, classes))
# Print the Silhouette score for each cluster number
print(f'The silhouette score for {i} clusters is {s_score[i]:.3f}')Output
The silhouette score for 2 clusters is 0.681
The silhouette score for 3 clusters is 0.553
The silhouette score for 4 clusters is 0.498
The silhouette score for 5 clusters is 0.493
The silhouette score for 6 clusters is 0.365
The silhouette score for 7 clusters is 0.357
The silhouette score for 8 clusters is 0.362
The silhouette score for 9 clusters is 0.349
The silhouette score for 10 clusters is 0.331From the visualization, we can see that the model with 2 clusters has the highest value of Silhouette score, and the model with 3 clusters has the 2nd highest value, so we get the consistent result that there are 2 or 3 clusters.
# Visualization
plt.figure(figsize=(12,8))
plt.plot(list(s_score.keys()),list(s_score.values()))
plt.title('Silhouette Score')
plt.xlabel('Number of Clusters')
plt.ylabel('Silhouette Value')
plt.show()
Step 6: Deciding Number of Clusters Using Hierarchical Graph (Method 3)
In step 6, we will use the hierarchical graph to find the number of clusters.
The y axis is the euclidean distance, so the longer the vertical line is, the larger distance between the clusters.
From the graph, we can see that the two clusters connected by the blue line have the largest distance, and the two sub-clusters in red have a relatively large distance too. Therefore, the hierarchical graph suggests 2 or 3 clusters as well.
# Change figure size
plt.figure(figsize=(16,12))# Fit the heirachical graph
heirachical_graph=hier.dendrogram(hier.linkage(X, method='ward')) #method='ward' uses the Ward variance minimization algorithm# Add titles and labels
plt.title('Hierachical Clustering Graph')
plt.xlabel('Flowers')
plt.ylabel('Euclidean Distance')
Step 7: Deciding Number of Clusters Using AIC and BIC from GMM (Method 4)
In step 7, we will talk about how to decide the number of clusters using AIC and BIC values.
Both AIC (Akaike Information Criterion) and BIC (Bayesian Information Criterion) are metrics that measure the relative prediction errors of different models. The lower the value is, the better the model is.
The Gaussian Mixture Model AIC and BIC scores can help us decide the optimal number of clusters.
# Create empty dictionary for AIC and BIC values
aic_score = {}
bic_score = {}# Loop through different number of clusters
for i in range(1,11):
# Create Gaussian Mixture Model
gmm = GaussianMixture(n_components=i, random_state=0).fit(X)
# Get AIC score for the model
aic_score[i] = gmm.aic(X)
# Get BIC score for the model
bic_score[i] = gmm.bic(X)# Visualization
plt.figure(figsize=(12,8))
plt.plot(list(aic_score.keys()),list(aic_score.values()), label='AIC')
plt.plot(list(bic_score.keys()),list(bic_score.values()), label='BIC')
plt.legend(loc='best')
plt.title('AIC and BIC from GMM')
plt.xlabel('Number of Clusters')
plt.ylabel('AIC and BIC values')
plt.show()
From the visualization, we can see that AIC has the smallest value at 3 clusters. Although the AIC value for 10 clusters is smaller, the difference between 3 clusters and 10 clusters is quite small. In this case, we will choose a simpler model with 3 clusters.
BIC has the smallest value at the 2-cluster model, and the 3-cluster model has a similar value, suggesting that the optimal number of clusters is 2 or 3.
Step 8: Deciding Number of Clusters Using Gap Statistics (Method 5)
In step 8, we will talk about how to decide the optimal number of clusters using gap statistics. Gap statistics compares the change in within-cluster dispersion with the uniform distribution[3]. A large gap statistics value means that the clustering is very different from the uniform distribution.
Anaconda.org has a notebook with the implementation of gap statistics[1]. The code in the gap statistics section are all borrowed from the notebook.
def optimalK(data, nrefs=3, maxClusters=15):
"""
Calculates KMeans optimal K using Gap Statistic from Tibshirani, Walther, Hastie
Params:
data: ndarry of shape (n_samples, n_features)
nrefs: number of sample reference datasets to create
maxClusters: Maximum number of clusters to test for
Returns: (gaps, optimalK)
"""
gaps = np.zeros((len(range(1, maxClusters)),))
resultsdf = pd.DataFrame({'clusterCount':[], 'gap':[]})
for gap_index, k in enumerate(range(1, maxClusters)): # Holder for reference dispersion results
refDisps = np.zeros(nrefs) # For n references, generate random sample and perform kmeans getting resulting dispersion of each loop
for i in range(nrefs):
# Create new random reference set
randomReference = np.random.random_sample(size=data.shape)
# Fit to it
km = KMeans(k)
km.fit(randomReference)
refDisp = km.inertia_
refDisps[i] = refDisp # Fit cluster to original data and create dispersion
km = KMeans(k)
km.fit(data)
origDisp = km.inertia_ # Calculate gap statistic
gap = np.log(np.mean(refDisps)) - np.log(origDisp) # Assign this loop's gap statistic to gaps
gaps[gap_index] = gap
resultsdf = resultsdf.append({'clusterCount':k, 'gap':gap}, ignore_index=True) return (gaps.argmax() + 1, resultsdf) # Plus 1 because index of 0 means 1 cluster is optimal, index 2 = 3 clusters are optimalThe function output the optimal number of cluster based on the number of clusters with the largest gap value, but we can see from the visualization that after 3 clusters, the graph is relatively flat, showing a diminishing gap increase. Therefore, the optimal number of clusters is 3 if we use the elbow method.
# Automatically output the number of clusters
k, gapdf = optimalK(X, nrefs=3, maxClusters=11)
print('Optimal k is: ', k)# Visualization
plt.plot(gapdf.clusterCount, gapdf.gap, linewidth=3)
plt.scatter(gapdf[gapdf.clusterCount == k].clusterCount, gapdf[gapdf.clusterCount == k].gap, s=250, c='r')
plt.grid(True)
plt.xlabel('Cluster Count')
plt.ylabel('Gap Value')
plt.title('Gap Values by Cluster Count')
plt.show()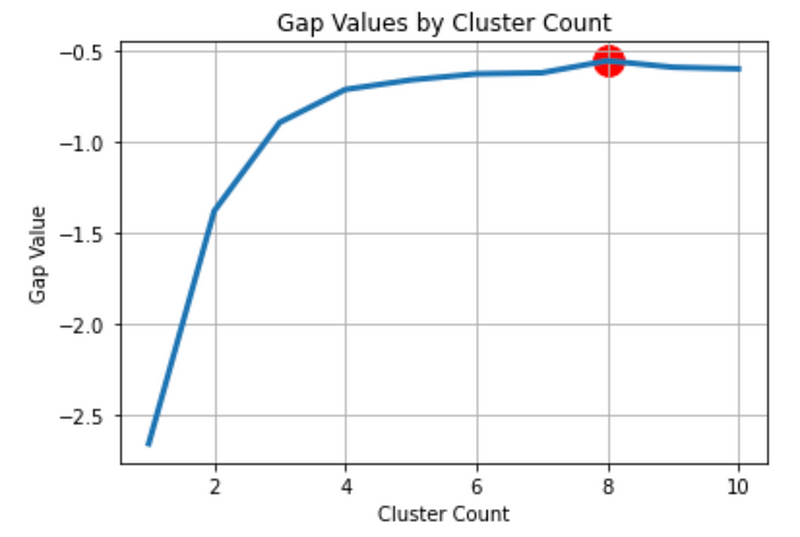
Step 9: Which method to use for the optimal number of clusters?
Now we have learned the 5 different ways of choosing the number of clusters, you might wonder how to choose a method for your project. Here is a general guideline:
- Start with the elbow method for the within cluster sum of squares and see if there is a clear elbow.
- If the elbow is not very clear, use the hierarchical graph to help decide the optimal number.
- If the optimal number of clusters is still not obvious after using the elbow method and hierarchical graph, use all five methods and choose the optimal number of clusters the majority of methods suggest.
Summary
In this tutorial, we talked about five ways to decide the number of clusters for a clustering model in Python. You learned:
- How to use the elbow method on within cluster sum of squares to decide the number of clusters?
- How to use the Silhouette score to decide the number of clusters?
- How to use the hierarchical graph to find the optimal number of clusters visually?
- How to use AIC and BIC for choosing the number of clusters?
- How to use gap statistics to decide the number of clusters?
More tutorials are available on GrabNGoInfo YouTube Channel and GrabNGoInfo.com.
Recommended Tutorials
- GrabNGoInfo Machine Learning Tutorials Inventory
- Time Series Forecasting Of Bitcoin Prices Using Prophet
- Multivariate Time Series Forecasting with Seasonality and Holiday Effect Using Prophet in Python
- Four Oversampling And Under-Sampling Methods For Imbalanced Classification Using Python
- Recommendation System: User-Based Collaborative Filtering
- Sentiment Analysis Without Modeling: TextBlob vs. VADER vs. Flair
References
[1] Python implementation of the Gap Statistic




