
5 Signs You’ve Become an Advanced Pandas User Without Even Realizing It
Time to take credit

Introduction
Do you find yourself daydreaming about Pandas DataFrames and Series? Do you spend hours on end performing complex manipulations and aggregations, barely noticing your back pain and thinking “this is so much fun” all the while?
Well, you might as well be an advanced Pandas user without even realizing it. Join the club of Pandas aficionados who have reached this rare level and embrace the fact that you are officially a data wizard.
So, let’s take a look at five signs that you are in this club.
0. Know when to ditch Pandas
When you first started out learning data analysis, it might have seemed like Pandas could do everything. Many online courses market Pandas as a one-stop-shop for all your data-related needs.
However, with experience, you’ve come to realize that Pandas has many shortcomings. Instead of blindly busting it for any data-related task, you know how to take a step back and ask yourself, “Is Pandas the best option here?”
There are a few scenarios where the answer to that question is a big fat NO. These include real-time data processing, handling massive datasets, high-performance computing, and production-level data pipelines.
1/ For real-time data processing, imagine a cannon that shoots pieces of real-time data from some process at 100 sph (shoots per hour :). The pieces are coming fast and furious, and you have to catch, process, and save each one mid-air.
Put gently, Pandas will be suffocated by this level of data processing. Instead, you should use libraries like Apache Kafka.
2/ When it comes to massive datasets, Wes McKinney, the creator of Pandas, had a rule of thumb:
The RAM must be 5–10 times bigger than the dataset size for Pandas to work optimally.
“Easy enough”, you would say if it was 2013, but today’s datasets tend to break this rule easily.
3/ High-performance computing is like conducting a symphony. Just as a conductor needs to coordinate the action of many different musicians to create a harmonious performance, high-performance computing tasks require coordination and synchronization of multiple processing elements and threads to achieve the best results.
As for Pandas, it runs solo.
4/ For production-level data pipelines, think of them as a water supply system. Just as it needs to be reliable, scalable, and maintainable to ensure a constant supply of clean water, data pipelines need similar qualities. While Pandas may take care of cleaning and transformation, other libraries should be used for the rest.
It may be difficult to leave the furry arms of Pandas, but don’t feel guilty about exploring other options if it isn’t enough.
Personally, I have recently become interested in Polars, a library written in Rust that was designed from scratch to address all the limitations of Pandas.
You can also play mix-and-match with libraries like datatable. Here is a code snippet I often use to load large CSVs in a fraction of a second and perform my analyses in Pandas:
import datatable as dt
df = dt.fread("my_large_file.csv").to_pandas()1. Need For Speed
Pandas is a massive library with many different methods to perform the same task. However, if you’re an experienced user, you know which method works best in specific situations.
For instance, you’re familiar with the differences between iteration functions like apply, applymap, map, iterrows, and itertuples. You are also aware of the trade-offs between using a slower alternative for better functionality and using the best one for optimal speed.
While some people may call you fussy, you carefully use iloc and loc because you know that iloc is faster for indexing rows, and loc is faster for columns.
However, when it comes to indexing values, you avoid these accessors because you understand that conditional indexing is orders of magnitude faster with the query function.
# DataFrame of stock prices
stocks_df = pd.DataFrame(
columns=['date', 'company', 'price', 'volume']
)
threshold = 1e5
# Rows where the average volume for a company
# is greater than some threshold
result = df.query(
'(volume.groupby(company).transform("mean") > @threshold)'
)And you also know that the replace function is best friends with query to replace values.
df.query('category == "electronics"').replace(
{"category": {"electronics": "electronics_new"}}, inplace=True
)Besides, you are comfortable with different file formats such as CSVs, Parquets, Feathers, and HDFs and you consciously choose between them, instead of blindly pouring everything into good-old CSVs. You know that choosing the right format can help save hours and memory resources down the line.
In addition to file formats, you also have a powerful trick up your sleeve — vectorization!
Rather than treating DataFrames as just data frames, you think of them as matrices and the columns as vectors. Whenever you find yourself itching to use an iteration function like apply or itertuples, you first see if you can use vectorization to apply a function to all elements in a column simultaneously, rather than one-by-one.
Moreover, you prefer to use the underlying NumPy arrays with the .values attribute instead of Pandas Series because you have observed first-hand how vectorization is much faster with NumPy arrays.
When all else fails, you don’t call it a day and give up. No.
You turn to either Cython or Numba for truly computationally-intensive tasks because you are a pro. While most people learned Pandas basics, you spent a few excruciating hours to learn these two technologies. That’s what sets you apart.
As if all these weren’t enough, you have given the Enhancing performance page of Pandas user guide a thorough read.
2. So many data types
Pandas offers so much flexibility with data types. Instead of just using plain float, int, and object data types, you have made the following two images your wallpapers:
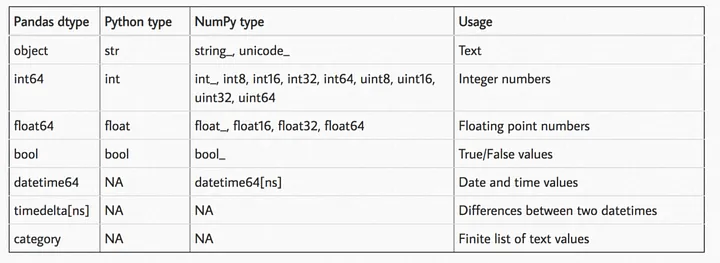

You deliberately choose the smallest data type possible because you know it is very friendly for your RAM. You know that int8 takes up much less memory than int64, and the same goes for floats.
You also avoid the object data type like the plague since it is the worst one there is.
Before reading data files, you observe their top few rows with cat file_name.extension to decide which data types you want to use for the columns. Then, when using read_* functions, you fill out the dtype parameter for each column instead of letting Pandas decide for itself.
You also perform data manipulation inplace as much as possible. Without it, you know that Pandas spawns off copies of the DataFrames and Series, littering your memory. Additionally, you have a very good grip of classes and parameters like pd.Categorical and chunksize.
3. Friends with Pandas
If there is one thing that makes Pandas the king of data analysis libraries, it’s got to be its integration with the rest of the data ecosystem.
For example, by now you must have realized how you can change the plotting backend of Pandas from Matplotlib to either Plotly, HVPlot, holoviews, Bokeh, or Altair.
Yes, Matplotlib is best friends with Pandas but for once in a while, you fancy something interactive like Plotly or Altair.
import pandas as pd
import plotly.express as px
# Set the default plotting backend to Plotly
pd.options.plotting.backend = 'plotly'Talking about backends, you’ve also noticed that Pandas added a fully-supported PyArrow implementation for its read_* functions to load data files in the brand-new 2.0.0 version.
import pandas as pd
pd.read_csv(file_name, engine='pyarrow')When it was NumPy backend only, there were many limitations like little support for non-numeric data types, near-total disregard to missing values or no support for complex data structures (dates, timestamps, categoricals).
Before 2.0.0, Pandas had been cooking up in-house solutions to these problems but they were not as good as some heavy users have hoped. With PyArrow backend, loading data is considerably faster and it brings a suite of data types that Apache Arrow users are familiar with:
import pandas as pd
pd.read_csv(file_name, engine='pyarrow', dtype_engine='pyarrow')Another cool feature of Pandas I am sure you use all the time in JupyterLab is styling DataFrames.
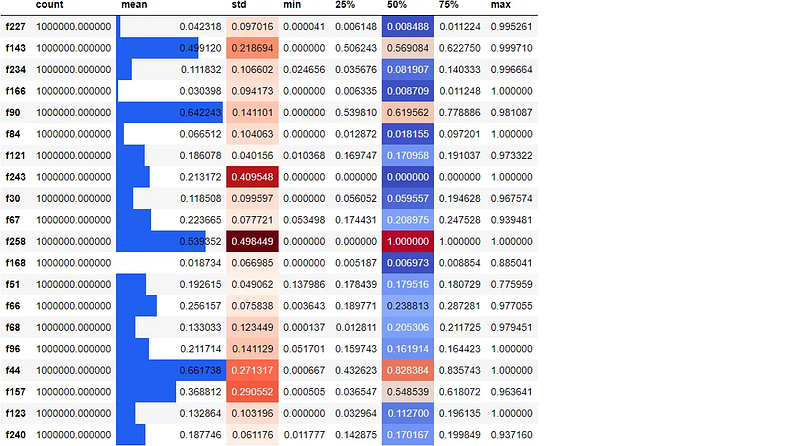
Since project Jupyter is so awesome, Pandas developers added a bit of HTML/CSS magic under the .style attribute so you can spice up plain old DataFrames in a way that reveals additional insights
df.sample(20, axis=1).describe().T.style.bar(
subset=["mean"], color="#205ff2"
).background_gradient(
subset=["std"], cmap="Reds"
).background_gradient(
subset=["50%"], cmap="coolwarm"
)
4. The data sculptor
Since Pandas is a data analysis and manipulation library, the truest sign you are pro is how flexibly you can shape and transform datasets to suit your purposes.
While most online courses provide the ready-made, cleaned columnar format data, the datasets in the wild come in many shapes and forms. For example, one of the most annoying formats of data is row-based (very common with financial data):
import pandas as pd
# create example DataFrame
df = pd.DataFrame(
{
"Date": [
"2022-01-01",
"2022-01-02",
"2022-01-01",
"2022-01-02",
],
"Country": ["USA", "USA", "Canada", "Canada"],
"Value": [10, 15, 5, 8],
}
)
df
You must be able to convert row-based format into a more useful format like the below example using pivot function:
pivot_df = df.pivot(
index="Date",
columns="Country",
values="Value",
)
pivot_df
You may also have to perform the opposite of this operation, called a melt.
Here is an example with melt function of Pandas that turns columnar data into row-based format:
df = pd.DataFrame(
{
"Date": ["2022-01-01", "2022-01-02", "2022-01-03"],
"AAPL": [100.0, 101.0, 99.0],
"GOOG": [200.0, 205.0, 195.0],
"MSFT": [50.0, 52.0, 48.0],
}
)
df
melted_df = pd.melt(
df, id_vars=["Date"], var_name="Stock", value_name="Price"
)
melted_df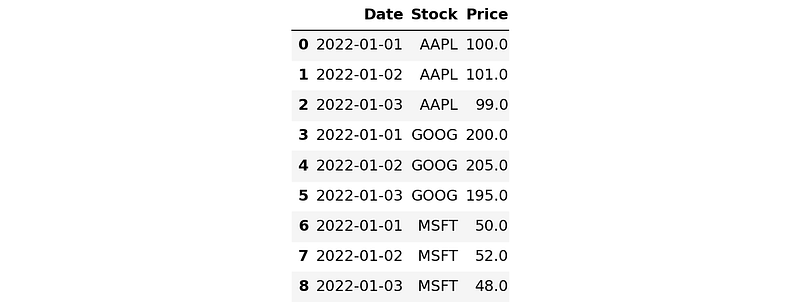
Such functions can be quite challenging to understand and even harder to apply.
There are other similar ones like pivot_table, which creates a pivot table that can compute different types of aggregations for each value in the table.
Another function is stack/unstack, which can collapse/explode DataFrame indices. crosstab computes a cross-tabulation of two or more factors, and by default, computes a frequency table of the factors but can also compute other summary statistics.
Then there’s groupby. Even though the basics of this function is simple, its more advanced use-cases are very hard to master. If the contents of the Pandas groupby function were made into a separate library, it would be larger than most in the Python ecosystem.
# Group by a date column, use a monthly frequency
# and find the total revenue for `category`
grouped = df.groupby(['category', pd.Grouper(key='date', freq='M')])
monthly_revenue = grouped['revenue'].sum()Skillfully choosing the right function for a particular situation is a sign you are true data sculptor.
Read parts two and three to learn the ins and outs of the functions mentioned in this section.
Conclusion
While the title of the article may have seemed like a playful way to recognize advanced Pandas users, my aim was to also provide some guidance for beginners looking to up their data analysis skills.
By highlighting some of the quirky habits of advanced users, I wanted to shed light on some of the lesser-known but powerful features of this versatile library.
Whether you are a seasoned data pro or just starting out, mastering Pandas can be daunting. However, by recognizing the signs of an advanced user and adopting some of their techniques and tricks, you can take your data analysis game to the next level.
I hope this article has provided some entertainment and inspiration for you to explore the depths of Pandas and become a master of data manipulation. Thank you for taking reading!
Loved this article and, let’s face it, its bizarre writing style? Imagine having access to dozens more just like it, all written by a brilliant, charming, witty author (that’s me, by the way :).
For only 4.99$ membership, you will get access to not just my stories, but a treasure trove of knowledge from the best and brightest minds on Medium. And if you use my referral link, you will earn my supernova of gratitude and a virtual high-five for supporting my work.






