
5 Powerful Cross-Validation Methods to Skyrocket Robustness of Your ML Models
All CV procedures you need to know as a data scientist, explained

Why cross-validate?
Before I start selling the merchandise, I need to pitch the main idea. Picture a crazy world where you don’t know what cross-validation is. In this world, you split your data into a single train and test set, train your model, and test it. If unsatisfied with the score, you tweak your model until GridSearch (or Optuna) cries out “enough!”.
Here, two things can go horribly wrong:
- The sets may not represent the entire population well. For instance, categories or numeric variables may be unevenly distributed between the train and test sets, leading to skewed learning.
- You risk leaking test set knowledge during hyperparameter tuning. The tuning framework may give you parameters that work best for that specific test set, which can lead to overfitting.
In a world where cross-validation is embraced, these issues are resolved. The magic of cross-validation, as exemplified in this 5-fold process:
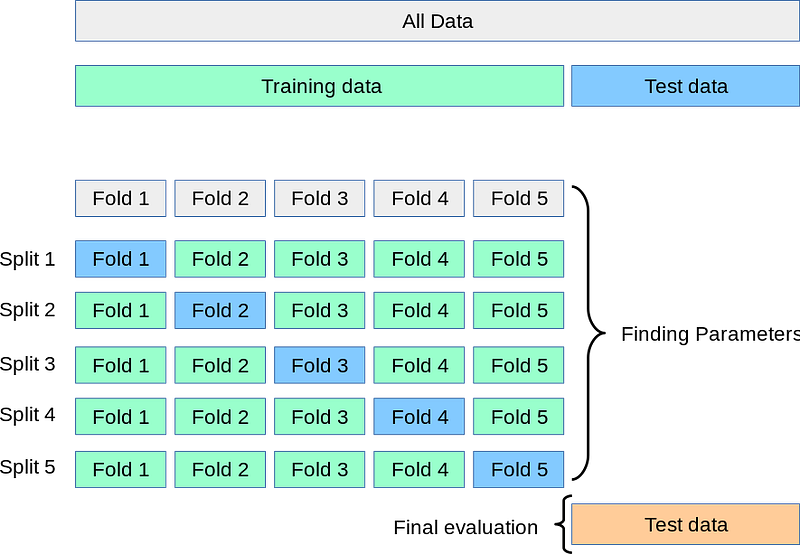
A new model is trained on four folds and tested on the last holdout fold in each iteration, ensuring all data is used. The average scores and their standard deviations are reported as a confidence interval, providing a true measure of your model’s performance.
There are many variants of cross-validation and we will look at the five most important ones in this article.
1. KFold
The simplest CV procedure is KFold as seen in the above image. It is implemented with the same name in Sklearn. Here, we will write a quick function that visualizes the split indices of the CV splitter:
Now, let’s pass a KFold splitter with seven splits to this function:
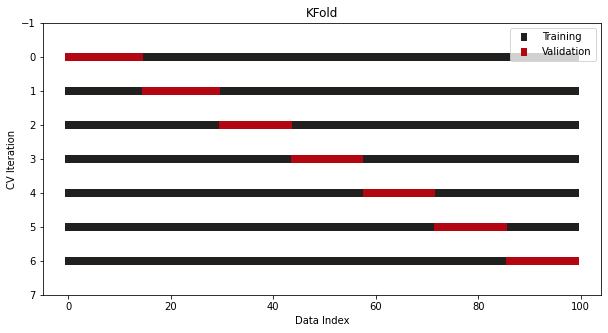
This is what a vanilla KFold looks like.
Another version is shuffling the data before a split is performed. This further minimizes the risk of overfitting by breaking the original order of the samples:
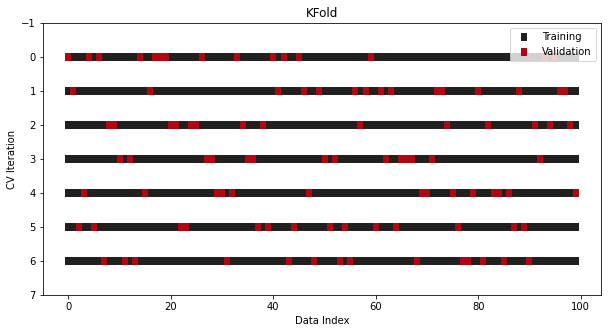
As you can see, the indices of the validation samples are chosen in a shuffled manner. Even so, the overall number of samples is still one-seventh of the whole data because we are doing a 7-fold CV.
KFold is the most commonly used CV splitter. It is easy to understand and deadly effective. However, depending on the characteristics of your datasets, sometimes you need to be pickier over what CV procedure to use. So, let’s discuss the alternatives.
2. StratifiedKFold
Another version of KFold designed explicitly for classification problems is StratifiedKFold.
In classification, the target distribution must be preserved even after the data is split into multiple sets. More specifically, a binary target with 30 to 70 class ratios should still hold the same ratios in both the training and test sets.
The rule is broken in vanilla KFold because the class ratios won’t be preserved when you shuffle the data before splitting. As a solution, we use another splitter class for classification in Sklearn — StratifiedKFold:
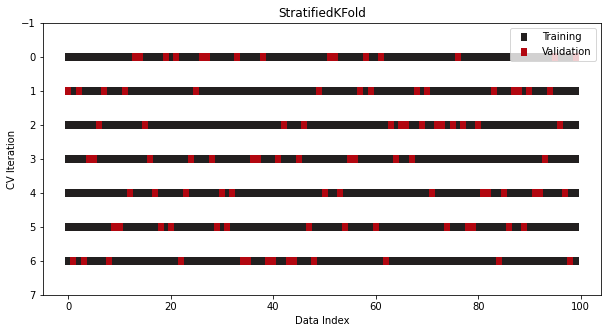
It looks the same as KFold, but now class ratios are preserved across all folds and iterations.
3. LeavePOut
Sometimes, the data you have is so limited that you can’t even afford to divide it into train and test sets. In that case, you can perform a CV where you set aside only a few rows of data in each iteration. This is known as LeavePOut CV, where P is the parameter you choose to specify the number of rows in each holdout set.
The most extreme case is the LeaveOneOut splitter where you only use a single row as a test set, and the number of iterations equals the number of rows in the full data. If building 100 models for a small 100-row dataset seems like it is bordering on crazy, I am right there with you.
Even for higher numbers of p, the number of iterations grows exponentially as your dataset size increases. Just imagine how many models will be built when p is five and your data has just 50 rows (hint - use the permutations formula).
So, you rarely see this one in practice, but it comes up enough times that Sklearn implements these procedures as separate classes:
from sklearn.model_selection import LeaveOneOut, LeavePOut4. ShuffleSplit
How about we don’t do CV at all and just repeat the train/test split process multiple times? Well, that’s another way you can flirt with the idea of cross-validation and yet still not do it.
By logic, generating multiple train/test sets using different random seeds should resemble a robust CV process if done for enough iterations. That’s why there is a splitter that performs this process in Sklearn:

The advantage of ShuffleSplit is that you have complete control over the sizes of the train and sets in each fold. The size of the sets doesn’t have to be inversely proportionate to the number of splits.
For example, a ShuffleSplit with 5 folds and a test size of 25%:
- Generates 75/25 ratio train/test sets in each fold.
- Shuffles the data before splitting.
However, unlike other splitters, there is no guarantee that random splits will generate different folds in each iteration. So, use this class with caution.
By the way, there is also a stratified version of ShuffleSplit for classification:

5. TimeSeriesSplit
Finally, we have the special case of time series data where the ordering of samples matters.
We can’t use any of the traditional CV classes because they would lead to a disaster. There is a high chance you would be training on the future samples and predicting the past ones.
To solve this, Sklearn offers yet another splitter — TimeSeriesSplit where it ensures that the above does not happen:
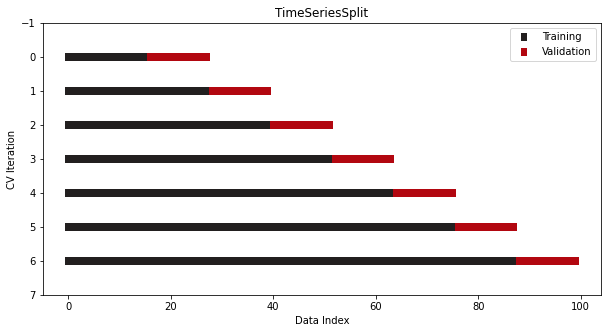
As you can see, the validation set always comes after the indices of the training set. Since the indices are dates, you won’t accidentally train a time series model on future dates and predict on the previous ones.
Other CV splitters for non-IID data
So far, we have been dealing with IID (independent and identically distributed) data. In other words, the process that generated the data does not have a memory of the past samples.
However, there are cases where your data is not IID — that some groups of samples are dependent on each other. For example, in the Google Brain Ventilator Pressure competition on Kaggle, the participants should work with non-IID data.
The data records thousands of breaths (in, out) that an artificial lung takes and records the air pressure for each breath at some millisecond intervals. As a result, the data contains about 80 rows for each breath taken, making those rows dependent.
Here, traditional CV splitters won’t work as expected because there is a definite chance that a split might occur “right in the middle of a breath.” Here is another example from the Sklearn user guide:
Such a grouping of data is domain specific. An example would be when there is medical data collected from multiple patients, with multiple samples taken from each patient. And such data is likely to be dependent on the individual group. In our example, the patient id for each sample will be its group identifier.
It also states the solution right after that:
In this case we would like to know if a model trained on a particular set of groups generalizes well to the unseen groups. To measure this, we need to ensure that all the samples in the validation fold come from groups that are not represented at all in the paired training fold.
Then, Sklearn lists five different classes that can work with grouped data. If you grasped the ideas from the previous sections and understood what non-IID data is, you won’t have trouble working with them:
Each of these splitters has a groups argument where you should pass the column the group ids are stored. This tells the classes how to differentiate between each group.
Summary
Finally, the dust settles, and we are here.
One question I probably left unanswered is, “Should you always use cross-validation?” The answer is a tentative yes. When your dataset is sufficiently large, any random split will probably resemble the original data well in both sets. In that case, a CV is not a strict requirement.
However, statisticians and folks much more experienced than me on StackExchange say that you should perform at least two or 3-fold cross-validation no matter the data size. You just can never be too cautious.
Thank you for reading!
Loved this article and, let’s face it, its bizarre writing style? Imagine having access to dozens more just like it, all written by a brilliant, charming, witty author (that’s me, by the way :).
For only 4.99$ membership, you will get access to not just my stories, but a treasure trove of knowledge from the best and brightest minds on Medium. And if you use my referral link, you will earn my supernova of gratitude and a virtual high-five for supporting my work.





